Foxr – a Node.js API to control Firefox
- uses a built-in Marionette through remote protocol
- no Selenium WebDriver is needed
- works with Headless mode
- compatible subset of Puppeteer API
Very much a WIP. 🚧
- uses a built-in Marionette through remote protocol
- no Selenium WebDriver is needed
- works with Headless mode
- compatible subset of Puppeteer API
Very much a WIP. 🚧
Read this for the sidebar management tips alone! Wow, I had no idea how cluttered my sidebar was until I followed Peter’s guidance from this post.
Declutter your sidebar by hiding all channels that don’t contain unread messages and are not starred. You still won’t miss anything, as they pop up if there’s chatter, and you can always use ⌘-T to open the Jump menu. It’s amazing how much better it feels if there aren’t 50 channels you need to scroll through all the time.
This post was extracted from Peter’s talk Effective Remote Communication.
We had the pleasure of meeting up with Safia last year at OSCON. You can hear the conversation we had on this anthology episode where we discussed the future of open source.
I saw this tweet (see below) and wanted to help amplify it.
Hello!
I’m still looking for my first full-time, post-grad engineering gig.
I’m looking for SE roles in Chicago/remote starting in early April.
Let me know if you’d like to interview me!
We think Safia is awesome. Hire her. You can view Safia’s résumé here.
Watson lets you create issues while you code, including custom labels, without ever having to interrupt your workflow. It syncs with remote services like GitHub and Bitbucket – Push locally created issues and get the status of remote issues right in your command line.
Pick your flavor and install either the Ruby or Perl version.
dotCloud’s Docker — a project which makes managing Linux containers easy, previously covered here and discussed on episode #89 — is inspiring & enabling a bunch of open source Platforms as a Service (PaaS).
One of the first (and definitely the smallest) of these is Dokku by Jeff Lindsay.
Dokku weighs in at under 1,000 lines of Bash and offers the same git-push-based app deployment made famous by Heroku and emulated by many PaaS providers. After installation and some configuration, you can deploy to your own mini-Heroku using one of the many supported buildpacks.
Here’s what deploying Heroku’s example Node.js app looks like with Dokku:
$ cd node-js-sample
$ git remote add progrium git@progriumapp.com:node-js-app
$ git push progrium master
Counting objects: 296, done.
Delta compression using up to 4 threads.
Compressing objects: 100% (254/254), done.
Writing objects: 100% (296/296), 193.59 KiB, done.
Total 296 (delta 25), reused 276 (delta 13)
remote: -----> Building node-js-app ...
remote: Node.js app detected
remote: -----> Resolving engine versions
... blah blah blah ...
remote: -----> Application deployed:
remote: http://node-js-app.progriumapp.com
It’s exciting to see how much can be done with so little code. Dokku is MIT licensed and hosted on GitHub.
Paul Frazee’s side project, Local, is not just a library for getting better utility out of Web Workers. It is that, of course, but it’s also a different way to think about web apps.
Local allows servers to run in browser threads where they host HTML and act as proxies between the main thread and remote services. The server threads run in their own Web Worker namespaces and communicate via Local’s implementation of HTTP over the postMessage API.
This architecture presents many interesting opportunities for new kinds of web apps. Want to learn more? Paul wrote an article outlining four potential use cases that Local enables. Give it a read, check out the docs (which are built using Local), or view the project’s source code on GitHub.
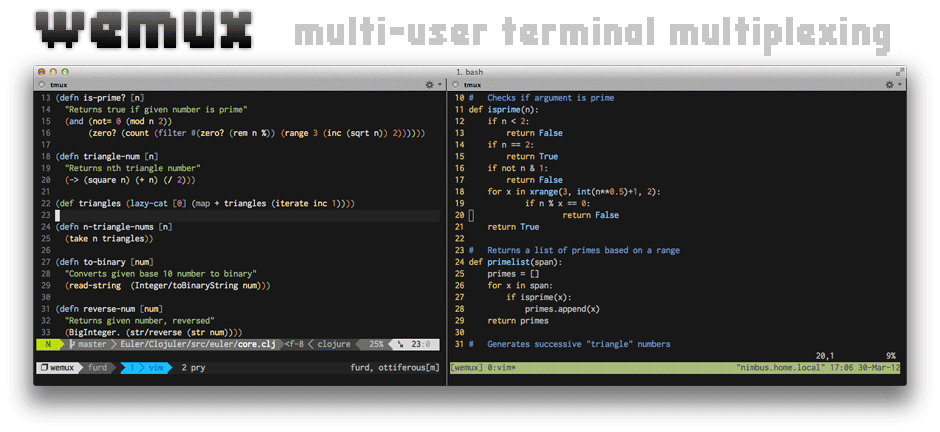
Two of the many things in the development community that are growing in popularity are remote work and pair programming. Traditionally, pairing meant you had two people looking at the same computer and one person doing the typing. This is great, as long as you are in the same room.
What about those developers, like myself, who rarely (if ever) find themselves in the same room as their coworkers? Enter wemux by Matt Furden, the tmux tool that makes it simple for multiple users to connect to the same tmux session so you can see the same thing.
The only requirement, according to the README, is tmux >= 1.6. Installation is simple, with the preferred method being Homebrew:
>> brew install https://github.com/downloads/zolrath/wemux/wemux.rb
After installation, you — the host — would start a new wemux server:
>> wemux start
At this time, anyone else — the clients — could connect with any of the following three commands:
wemux mirror - attach to the server in read-only mode.wemux pair - attach to the server in pair mode, where both the client and the host can control the terminal.wemux rogue - attach to the server in rogue mode, where the client and host can work independently of eachother.There are plenty of other features, from listing users to running multiple wemux servers at once. Once you get the hang of it, pairing while working remotely becomes much simpler than screen sharing on Skype!
You can find out everything you need to know in the README or discuss this post on HackerNews.
Tools like Capistrano and Vlad have been popular for deploying applications to remote servers. Mina is a new entrant in the field that uses a single SSH session per server, cutting down on deploy time. Mina uses Rake and deploy routines are set up in config/deploy.rb:
require 'mina/git'
set :domain, 'your.server.com'
set :user, 'flipstack'
set :repository, 'flipstack'
task :deploy do
deploy do
# Preparations here
invoke :'git:clone'
invoke :'bundle:install'
end
end
task :restart do
queue 'sudo service restart apache'
end
Check out the project web site or source on GitHub for complete usage instructions, including test deploys with Rspec and other popular frameworks.
![]()
Plumbum is an interesting project from Tomer Filiba that aims to bring shell syntax to Python scripts:
The motto of the library is “Never write shell scripts again”, and thus it attempts to mimic the shell syntax (shell combinators) where it makes sense, while keeping it all pythonic and cross-platform.
A piping example:
>>> chain = ls["-a"] | grep["-v", "\.py"] | wc["-l"]
>>> print chain
/bin/ls -a | /bin/grep -v '.py' | /usr/bin/wc -l
>>> chain()
u'13n'
In addition to piping, Plumbum supports redirection and even remote commands over SSH. Check out the source on GitHub, Tomer’s introductory blog post or the excellent project docs for more.
We just can’t shut up about the joys of tmux, especially for remote pairing. Matt Furden aims to make it even easier to set up a secure multi-user environment with wemux. Wemux sets up an SSH server and tmux sessions for three use cases:
Mirror Mode gives clients (another SSH user on your machine) read-only access to the session, allowing them to see you work, orPair Mode allows the client and yourself to work in the same terminal (shared cursor)
Rogue Mode allows the client to pair or work independently in another window (separate cursors) in the same tmux session.
Wemux can be installed via Homebrew and provides a command line interface with a host of options, for listing and joining servers, kicking users, and more:
$ wemux list
Currently active wemux servers:
1. project-x
2. rails
3. wemux <- current server
Check the README for advanced installation and usage.
For many of you reading this, you might be playing catch up on the disappearance of Mark Pilgrim — like I was while writing this.
On October 4th, 2011 various websites of Mark’s (diveintomark.org, diveintohtml5.org, diveintoaccessibility.org, diveintogreasemonkey.org, diveintopython.org, etc.) started to return the HTTP status code, 410 Gone.
The 410 response is primarily intended to assist the task of web maintenance by notifying the recipient that the resource is intentionally unavailable and that the server owners desire that remote links to that resource be removed. ~ 410 Gone
Mark also deleted his Twitter, Reddit, Google+ and GitHub accounts as well. But don’t worry, we are now more than 145 days past all of this so there’s no need to launch a manhunt — he’s OK. All that’s over now.
There is a lot more to this story, but I don’t desire to regurgitate that here when other sources have already good and covered it. However, before we move on from that subject — I did get a chuckle from this response from Mark to Jason Scott on Twitter.
Mark Pilgrim is alive/annoyed we called the police. Please stand down and give the man privacy and space, and thanks everyone for caring.— Jason Scott (@textfiles) October 5, 2011
…and there you have it …
Since we know he’s OK, and that he obviously intended to pull a _why — I guess we can simply do our best to preserve his contributions to the web community.
Thanks to Kenneth Reitz, Paul Irish and Jonathan Neal, most of Mark’s public work has been preserved in the mirror of Mark Pilgrim’s GitHub — special thanks to Kenneth for switching github/diveintomark to an org so we can all contribute.
GitHub continues to share their homegrown development toolbox with the world. The latest is Janky, a specialized continuous integration server powered by Jenkins and Hubot. No longer is Hubot good just for entertainment or demystifying esoteric 80s TV show references in the team chatroom. With Janky, Hubot is a remote control for your build box:
hubot ci build <project>
hubot ci build <project>/<branch>
hubot ci status
Check the README for advanced usage.
I’ll be honest: I hate uploading files. It shouldn’t be hard, but it always is, because there are so many details. The core case is so simple: You just need an <input> with the file type. Then you forget to make your form multipart, or configure your webserver to not time out for large files, or you want a progress indicator…
The last one is always AJAX. AJAX, AJAX, AJAX. If you’ve had to write this yourself, you know that you end up doing silly stuff with iframe injection, and it always feels so sloppy. Well, that’s why remotipart exists. It doesn’t get rid of the base issue (we’ll leave that up to the standards people), but it does make it super, ultra, mega easy to turn your regular upload form into an AJAX one.
Three steps: install the gem, add :remote => true to your form options, and wrap your response with a remotipart_response block. Here’s the full example, from the README:
sample_layout.html.erb
<%= form_for @sample, :html => { :multipart => true }, :remote => true do |f| %>
<div class="field">
<%= f.label :file %>
<%= f.file_field :file %>
</div>
<div class="actions">
<%= f.submit %>
</div>
<% end %>
sample_controller.rb
def create
respond_to do |format|
if @sample.save
format.js
end
end
end
create.js.erb
<%= remotipart_response do %>
// Display a Javascript alert
alert('success!');
<% if remotipart_submitted? %>
alert('submitted via remotipart')
<% else %>
alert('submitted via native jquery-ujs')
<% end %>
<% end %>
That simple. Bam. I love Rails 3’s unobtrusive Javascript.
Since it’s typed, human readable, and supported darn near everywhere,
JSON is the new hotness for data transport formats.
Unfortunately, many systems don’t expose a JSON API. Relational data is
often represented in the tried and true CSV format.
Paul Engel has introduced
CSONV.js, a JavaScript library
that can consume remote CSV data and transform it to JSON, a more
client-side developer friendly format.
Consider the following delimited files:
# books.csv
id;name;author
integer;string;authors:1
1;To Kill an Angry Bird;1
2;The Rabbit;2
3;Parslet;3
4;The Lord of the Things;2
5;The Michelangelo Code;4
# authors.csv
id;name;written_books
integer;string;books:n:author
1;Harper Lee;
2;JRR Tolkien;
3;William Shakespeare;
4;Dan Brown;
CSONV.js can transform these two relational sources into the following JSON:
[
{
"id": 1,
"name": "To Kill an Angry Bird",
"author": {
"id": 1,
"name": "Harper Lee"
}
},
{
"id": 2,
"name": "The Rabbit",
"author": {
"id": 2,
"name": "JRR Tolkien"
}
},
{
"id": 3,
"name": "Parslet",
"author": {
"id": 3,
"name": "William Shakespeare"
}
},
{
"id": 4,
"name": "The Lord of the Things",
"author": {
"id": 2,
"name": "JRR Tolkien"
}
},
{
"id": 5,
"name": "The Michelangelo Code",
"author": {
"id": 4,
"name": "Dan Brown"
}
}
]
Be sure and check out the project on
GitHub for complete feature list
and advanced usage info.
Yup, this is sexy and smart. Great work Robby Russell.
For the Oh My Zsh users out there, my guess is when you opened Terminal or iTerm2 today you were greeted with a request to update Oh My Zsh.
Call me a noob, but I think this is awesome.
Last login: Fri May 13 07:41:18 on console
[Oh My Zsh] Would you like to check for updates?
Type Y to update oh-my-zsh: Y
Upgrading Oh My Zsh
remote: Counting objects: 62, done.
remote: Compressing objects: 100% (44/44), done.
remote: Total 46 (delta 27), reused 11 (delta 1)
Unpacking objects: 100% (46/46), done.
From git://github.com/robbyrussell/oh-my-zsh
* branch master -> FETCH_HEAD
Updating 0365ef0..7c3d12c
Fast-forward
lib/git.zsh | 2 +-
lib/key-bindings.zsh | 5 ++++
.../apache2-macports/apache2-macports.plugin.zsh | 6 +++++
plugins/compleat/compleat.plugin.zsh | 22 ++++++++++++++++++++
themes/jispwoso.zsh-theme | 4 +++
themes/jtriley.zsh-theme | 2 +-
6 files changed, 39 insertions(+), 2 deletions(-)
create mode 100644 plugins/apache2-macports/apache2-macports.plugin.zsh
create mode 100644 plugins/compleat/compleat.plugin.zsh
create mode 100644 themes/jispwoso.zsh-theme
__ __
____ / /_ ____ ___ __ __ ____ _____/ /_
/ __ / __ / __ `__ / / / / /_ / / ___/ __
/ /_/ / / / / / / / / / / /_/ / / /_(__ ) / / /
____/_/ /_/ /_/ /_/ /_/__, / /___/____/_/ /_/
/____/
Hooray! Oh My Zsh has been updated and/or is at the current version.
Any new updates will be reflected when you start your next terminal session.
To keep up on the latest, be sure to follow Oh My Zsh on twitter: http://twitter.com/ohmyzsh
If you read this blog, you obviously care about open source. If you’ve never contributed to an open source project, though, you might have some cold feet about it. So, inspired by the Ruby 1.9.3 Documentation Challenge, I wrote up a post for my blog about how to contribute documentation to Ruby. I got some feedback like this:
@steveklabnik Hey this is awesome. It's time for me to solider up and pitch in. Thanks for the added incentive!— Chris Baglieri (@chrisbaglieri) May 10, 2011
So I figured something more general might encourage you to get involved with whatever open source project you’re using, even if it’s not in Ruby. Every project can use a hand, especially the small ones.
If you’re not contributing because you think you’re not ready, don’t worry about it! I know that this is easier said that done, but really, you’re ready. A friend of mine posted an article about why he doesn’t contribute, and I’m sure that many people share these kinds of fears. Greg Brown responded and addressed some of his concerns, but most of the people I’ve talked to object for two basic reasons:
Let’s talk about each of these, in reverse order. It’s true, you may have a busy life. I don’t know your personal schedule. But I’m sure you could find a spare hour or two, maybe on a weekend? That’s all it takes to get started. Most projects are built on the backs of a thousand tiny commits. You don’t need to make a large contribution, even small ones are valuable.
If you have fears about the quality of your code, well, the only way you’ll get better is with practice. So fire up that editor, and submit a patch! Generally, if something isn’t quite right about your submission, there’ll be a discussion about it on GitHub, and everyone learns. Take this pull request, for example. Colin originally submitted a patch that linked to the wrong URL, wilkie mentioned this, and Colin updated his code. It’s going to get merged as soon as I stop writing posts for the Changelog. :) But, this is generally what happens if your first submission is a bit off the mark. Don’t be scared! This is how we all learned, from each other.
The “It’s too hard” complaint usually comes out of “I’m not good enough.” But it can also happen if you try to contribute to a large project, where there are a lot of rules. Contribution guidelines, code coverage requirements, updating AUTHORS and CHANGELOG files… big projects need to have process to manage the large number of contributors, but this can certainly create a barrier to entry for newcomers. If process intimidates you, I have a suggestion: start small! Smaller projects often have little to no process whatsoever. Plus, you’ll make someone feel incredibly good. Think about it: Python receives a bunch of patches every day, but if you had a little tool you wrote up on GitHub, and all of a sudden you got an email, “Hey, someone has a patch for you,” I bet you’d feel pretty good about it!
When contributing to an open source project on GitHub, there’s a very basic workflow that almost every project follows. Three steps: Fork, commit, pull request.
GitHub makes the fork step really easy. Just click on the ‘fork’ button found on any project page. Let’s use Ruby as an example. The project page is here. You can see the fork button on the upper right. It looks like this:

Click that, and you’ll see some ‘hardcore forking action,’ and then you’ll be at your own fork! This is your own version of your project, and it appears on your GitHub page. For example, here’s my fork of Ruby. You’ll see a URL on that page, and that lets you clone the project down.
$ git clone git@github.com:steveklabnik/ruby.git
This creates a ‘ruby’ directory with all of the code in it. Next, let’s add a remote for upstream, so we can keep track of changes they make:
$ cd ruby
$ git remote add upstream https://github.com/ruby/ruby.git
$ git fetch upstream
Now at any time, we can grab all of the changes the main Ruby repository by doing a rebase:
$ git rebase upstream/master
A small note: ruby still uses both svn as well as git, so they call the master branch trunk. If you’re doing this for ruby, you’ll need git rebase upstream/trunk.
Now that you’ve cloned, you can do you work! I like to work in feature branches, as it makes things nice and clean, and I can work on two features at once.
$ git checkout -b feature/super-cool-feature
$ vim something
$ git add something
$ git commit -m "Fixed something in something"
Once you’ve got some commits that fix your problem, push them up to GitHub:
$ git push origin feature/super-cool-feature
And then you click the pull request button:

Select your branch, change the description of you want, and you’re good to go! The maintainer of the project will look it over, you might end up with a discussion, and you’ll soon get something accepted in somewhere!
The best way to contribute is to help out with a project that you actually use. That way you’ll get to take advantage of the fruits of your labors. You’ll be more motivated, you already understand the project and what it does, and that’ll make it easier on you.
If you don’t want to or can’t figure out how to work on something you use, the next best way is to start using some new software! Keep reading the Changelog and pick a project that looks interesting, use it for a few weeks, and then contribute!
I hope this encourages you to get your hands dirty, roll up your sleeves, and contribute. Even the smallest patch has worth, so please, make some time out in your schedule, pick a project, and give it a shot. You might just find yourself hooked.
Behind most every App Store download, there is a painful trail of ad hoc beta builds as developers send beta bits to users to gather feedback and fix bugs. Luke Redpath, UK Rubyist and iOS developer, aims to ease that pain for iOS developers with BetaBuilder, a Ruby gem that bundles up a collection of rake tasks to make it easier to deploy your iOS apps.
BetaBuilder supports distributing your apps own your own server or using TestFlightApp.com. To get started, first install the gem:
gem install betabuilder
Next, require BetaBuilder in your Rakefile:
require 'rubygems'
require 'betabuilder'
… and configure your app:
BetaBuilder::Tasks.new do |config|
# your Xcode target name
config.target = "MyGreatApp"
# the Xcode configuration profile
config.configuration = "Adhoc"
config.deploy_using(:web) do |web|
web.deploy_to = "http://beta.myserver.co.uk/myapp"
web.remote_host = "myserver.com"
web.remote_directory = "/remote/path/to/deployment/directory"
end
end
Now we can see all of our tasks with rake -T:
rake beta:archive # Build and archive the app
rake beta:build # Build the beta release of the app
rake beta:deploy # Deploy the beta using your chosen deployment strategy
rake beta:package # Package the beta release as an IPA file
rake beta:prepare # Prepare your app for deployment
rake beta:redeploy # Deploy the last build
If you want to use TestFlight instead of hosting your builds yourself, simply swap out the deploy config with:
config.deploy_using(:testflight) do |tf|
tf.api_token = "YOUR_API_TOKEN"
tf.team_token = "YOUR_TEAM_TOKEN"
end
Nifty. Need additional deploy strategies? Go ahead and fork the project and share it with the community.
[Update]:
Thanks, Luke, for pointing out some prior art from Hunter who lent the name to the project.
The Nodejitsu team has released Winston, a pluggable, async logger for Node.js that also supports multiple transports. Out of the box, Winston includes several transports including:
Winston can be installed via npm
npm install winston
In the simplest case, we can log to the console with just a few lines of code:
var winston = require('winston');
winston.log('info', 'Hello from Winston!');
winston.info('This also works');
You’re also free to set up your own loggers and choose your transport:
var logger = new (winston.Logger)({
transports: [
new (winston.transports.Console)(),
new (winston.transports.File)({ filename: 'somefile.log' })
]
});
We also mentioned that Winston supports async, Node.js callback-style logging.
logger.on('log', function (transport, level, msg, meta) {
// [msg] and [meta] have now been logged at [level] to [transport]
});
logger.on('error', function (err) {
// handle an error
});
logger.info('CHILL WINSTON!', { seriously: true });
One of the more interesting features of Winston is its support for logging metadata with log events. Depending on your transport, metadata is either simply displayed or stored alongside your log events. Perhaps the most robust example is storing metadata as a JSON literal in your Riak logging store:
winston.log('info', 'Test Log Message', { anything: 'This is metadata' });
For more on Winston or to find out how to support for your favorite transport, check the source. For a bit of background on the project name, check out Charlie’s blog post.
Team Adafruit is doing their first ever “X prize” type project. Hack the Kinect for Xbox 360 and claim the NOW $3,000 bounty! Hat tip to Himanshu Chhetri for letting us know about this. Thanks man!
The Open Kinect project has started a bit of drama around this contest. Microsoft seems to not be taking kindly to the bounty offer. Read the article titled “Bounty offered for open-source Kinect driver” over at CNET.
Kinect for Xbox 360, or simply Kinect (originally known as code name Project Natal (pronounced /nəˈtɒl/ nə-tahl)), is a “controller-free gaming and entertainment experience” by Microsoft currently only available on the Xbox 360 video game platform. In the future PCs via Windows 8 may be supported.
Kinect is based around a webcam-style add-on peripheral. It enables users to control and interact with the Xbox 360 through a natural user interface using gestures, spoken commands, or presented objects and images. The project is aimed at broadening the Xbox 360’s audience beyond its typical gamer base and will compete with other consoles, motion control systems and peripherals such as Wii Remote, Wii MotionPlus and PlayStation Move for the Wii and PlayStation 3.

An invisible light source illuminates the subject. A sensor chip then measures the distance the light has to travel to each pixel within the chip. A unique imaging software uses a “depth map” to perceive and identify objects in realtime and the end-user device reacts appropriately.
Wired has a great article about how motion detection works in Xbox Kinect!
They are looking to expand open source drivers for this cool USB device. The drivers and/or application can run on any operating system. Here’s the catch, everything has to be completely documented and under an open source license. To demonstrate the driver you must also write an application with one “window” showing video (640 x 480) and one window showing depth. Then just upload your project to GitHub.
Anyone around the world can work on this, even folks from Microsoft. Upload your code, examples and documentation to GitHub. The first person or group to get RGB out with distance values being used … wins. All code needs to be open source and/or public domain.
Email them a link to your repo, and Adafruit Industries as well as some “other” Kinect for Xbox 360 hackers will check it out – if it’s good to go, you’ll get the $3,000 bounty!
Good luck.
The Ajax.org Team has finally unveiled Cloud9, their much anticpated IDE-in-the-sky. Cloud9 runs on a stack of Node.js, HTML5, and their own Ajax.org frameworks which Ruben and Rik discussed in episode #16.
Although an early alpha, Cloud9 looks polished and includes a number of cool features:
- Easy hackability for Javascript developers
- At least as good as existing IDE’s and text editors with help from the latest browsers
- Local and remote file and repository integration
- Debugging support for Chrome / NodeJS
- Test and deploy your code in the cloud
To kick the tires yourself, you’ll need Node.js installed. You can then clone the repo and run the install script for your version:
$ bin/cloud9-osx64
$ bin/cloud9-lin32
> bincloud9-win32.bat
On the Mac, the script automatically starts the server and opens Cloud9 at http://localhost:3000.
Meant to support the SproutCore HTML5 Platform as well as manage packages for apps on the server, web browser, and other clients, SeedJS is built on node.js and Google V8 and helps distribute and install shared JavaScript code.
Seed builds upon the CommonJS package format and Seed archives are normal zip archives.
To get started once you have Node up and running, start by cloning the repo:
git clone git://github.com/seedjs/seed
cd seed
git submodule update --init
and then run the setup script:
./scripts/install.js
Make sure the seed binary is in your path:
export PATH=~/.seeds/bin:$PATH
You’re then free to list and install seeds:
seed list --remote
seed install markdown
… and use them in your app:
var markdown = require('markdown');
markdown.html('__Hello World__');
YouTuber “Internet of Bugs” breaks down why AI “software engineer” Devin is no Upwork hero, Redka is Anton Zhiyanov’s attempt to reimplement Redis with SQLite, OpenTofu issues its response to Hashicorp’s Cease and Desist letter, Brian LeRoux introduces Enhance WASM & PumpkinOS is not your average PalmOS emulator.
Matched from the episode's transcript 👇
Jerod Santo: It’s now time for Sponsored News!
Save the date! On April 30th, our friends at Tailscale are doing a webinar covering how to connect to your AWS resources easily and securely, which lets you:
Reserve your spot today by following the link in your chapter data and the newsletter. Thanks to Tailscale for supporting our work by sponsoring Changelog News.
Why would you want to switch your developer environments from containers to nix? Ádám from LastPass has a few reasons.
Matched from the episode's transcript 👇
Justin Garrison: It’s fun. It’s fun. The last remote dev environments I just want to point out to are things that are fully browser-based, where it’s like you don’t have this sort of remote connection. And it’s meant for environments where it’s like - maybe this is a Chromebook, maybe you don’t control the environment… These work great in lab settings. We just did Scale, the Southern California Linux Expo, and people that came with workshops that were fully web-based had a fantastic time. When you had to clone it locally or rely on someone’s local machine to set stuff up, it became a little more difficult. So…
Thisis our 14th Kaizen episode! Gerhard put some CDNs to the test, we’ve taken our next step with Postgres on Neon & Jerod pushed 55 commits (but 0 PRs)!
Matched from the episode's transcript 👇
Gerhard Lazu: I knew this, which is why I set up that remote engine, so that Jerod could actually test this. So I knew that he doesn’t have a container runtime locally, and that’s fine; that’s perfectly fine. So as long as you will run a local Postgres, which is the same version as the Neon one, this will be very straightforward. Or more straightforward than if we have to do checks and ensure that it’s the same one; then we have to do failures, and things like that. So that’s fine.
This week Adam is joined by Zeno Rocha — the creator of the beloved Dracula theme and Co-founder and CEO of Resend. They discuss his personal journey and the challenges of balancing work and family life, how becoming a parent has given him new perspectives and influenced his decision to start his own company, the role of citizenship and immigration in his journey, how he prepared for the Y Combinator interview, meeting Paul Graham, the challenges of sending email, and the future of Resend and the possibility of a Series A round.
Matched from the episode's transcript 👇
Zeno Rocha: I love that. I feel like whenever a meeting ends, three or four minutes and I have the next meeting, and I’m like “Oh, this is perfect. Let me go downstairs, let me play around with her a little bit.” Or whenever I’m working, I hear them screaming, and talking, and laughing, I’m like “I’ve gotta stop this”, and I go down there, and then we start playing… I wouldn’t trade that for anything, to be honest. And we had like VCs ask us “Oh, are you really sure that you’re going to do a remote company? After COVID, now all the companies are going back to in-person.” And for me, it feels like such a hard ask to tell folks “Hey, you’ve gotta leave your family – you’re not going to have those micro moments because of this thing that we’re building.” It just feels so unfair. I don’t have a face to make that ask.
In this episode Matt, Bill & Jon discuss various debugging techniques for use in both production and development. Bill explains why he doesn’t like his developers to use the debugger and how he prefers to only use techniques available in production. Matt expresses a few counterpoints based on his different experiences, and then the group goes over some techniques for debugging in production.
Matched from the episode's transcript 👇
Matthew Boyle: There’s a really famous indie hacker. I share his Twitter handle; it’s called Petr Levels I think is his name… And he makes millions of dollars a year by – he’s built AI apps, he’s built remote communities and stuff like that… And he has done all of this without really truly learning how software works. He kind of just like smashes together PHP. And he’s proud of it, by the way. I don’t think he would be mad at me saying this. He’s very much like a great product thinker, and he really leans into what’s popular at the moment, and discovers trends… But he quite often shares controversial by software engineering standards on Twitter that really rile up the software community. And it kind of makes me laugh, because you’ve got all these software purists telling him “That’s not how you should write software.”
For example, he shared the other day that he’s never done a join in the database. He does all of it in PHP. He does all of his join logic inside his code, rather than in a database, because he just doesn’t see the point of doing it in a database. And as you can imagine, that made tech Twitter very mad.
But he just uses code as a means to an end, and it works for him. And I think there’s probably a lot of people out there like him, who - especially as indie hackers, or someone just working for themselves, you can just get away with not really ever understanding what’s going on, as long as you can kind of smash everything together so it works. And I wonder if we’ll see more of those people or less of them.
What’s the difference between productivity engineering and platform engineering? How can you continue to re-platform with a moving target? On this episode, we’re joined by Andy Glover, who spent ten years productivity engineering at Netflix, to discuss.
Matched from the episode's transcript 👇
Andy Glover: At the end of the day, I think, human beings, I think we all value a sense of belonging, whether it be in a group or with another human… And that’s to your point about like chit-chatting about like Disney, or the stuff on Justin’s wall, or whatever, you know… And what I certainly found and have found with remote is it’s very tactical. It’s like “Hey, I’ve got 30 minutes to talk about business…”
THE Cameron Seay joins us once again! This time we learn more about his life/history, hear all about the boot camps he runs, discuss recent advancements in AI / quantum computing and how they might affect the tech labor market & more!
Matched from the episode's transcript 👇
Adam Stacoviak: What is the working environment of one of these developers? Is it remote, work from home? Sometimes you’re attracted to an environment, and sometimes you’re attracted to a money outcome, or a financial outcome… 80 grand a year is not that bad of an income. It’s a really great income. But at the same time, if you’re a software developer you can go and get a quarter million dollar salary at a startup, or something that was just recently funded, doing different work. So maybe that’s this person’s commentary from that perspective…
This week Adam talks with Kris Moore, Senior Vice President of Engineering at iXsystems, about all things TrueNAS. They discuss the history of TrueNAS starting from its origins as a FreeBSD project, TrueNAS Core being in maintenance mode, the momentum and innovation happening in TrueNAS Scale, the evolution of the TrueNAS user interface, managing ZFS compatibility in TrueNAS, the business model of iXsystems and their commitment to the open-source community, and of course what’s to come in the upcoming Dragonfish release of TrueNAS Scale.
Matched from the episode's transcript 👇
Kris Moore: So I guess I’ll talk about the business side a little bit. So iXsystems, of course, we’re the makers of TrueNAS, we do all the primary development, all the testing, all that good stuff on the software side. And then on the enterprise side of the business, we offer TrueNAS as an appliance. And that competes with more of your traditional vendors out there, if you can think of who they are out in the wild. But we’re the kind of young [unintelligible 00:56:01.02] guys who do the really cool stuff, and offer a lot of neat functionality that’s just all inclusive, it’s there; we’re not nickel and diming you for license fees, and all that good stuff. But we take that software, and we marry it to different hardware appliance platforms. The key thing is, we offer both single controller variants, so if you’re not in a high-availability need situation, you can do that. Or we have the HA platforms, which everything’s fully redundant. So one chassis, two discrete controllers in there, they all have redundant access to the storage, and we can do failovers between them. So if you do have catastrophic system failure or something, it can failover to the other controller, and you’re back in business within seconds, because it’s all accessing the same ZFS pool, and it makes upgrades super-simple, because you can failover between them. It’s quite nice. So we do that on the enterprise side, and that’s very popular. Our customers really love that.
And then we do things a little nicer, like the proactive support as well, which means we’re getting alerts and notices if a drive starts to behave flaky, or if we detect some other error conditioner on the box… We can reach out to you and let you know “Hey, we’ve detected something on your rig here. We’re gonna send you a new drive. Or we need to schedule a call to go dive into this deeper and see what’s going on.” So really popular on that side.
One thing I will speak about a little bit is I don’t think a lot of people realize how much work goes into doing an enterprise product like that. So we come out of the home lab space, right? We’re used to going on Amazon, or Newegg, and buying our parts and putting together our system, and kind of do it yourself… And that works to a degree of works. But to go to the real next level of enterprise-level functionality and stability is huge. Now we’re talking - we spend a lot of time working with vendors, firmwares, trying to make everything as reliable as possible to get all the nines on uptime we can, on every single platform we sell and support. That’s not something you get if you homelab it. A lot of times for homelab it’s fine, it’s good enough, but for an enterprise that says “Man, I’m running critical infrastructure off this. I cannot accept any kind of downtime.” Like, there’s a lot of extra work that goes into TrueNAS to polish it to that level, to make sure it’s just rock-solid stable for the most critical of environments.
[58:17] And the beautiful thing is the open source community benefits a lot from that too, because a lot of those fixes end up in the open source side, of course… And then a lot of it is on firmware and vendors and all that good stuff, to make sure that everything’s compatible, and it’s just hunky-dory, and hotplug, always works… And yes, enclosure management always works, and you get the nice visuals, and you can tell the remote hands in the data center which drive to pull by just looking at a graph and saying ‘Okay, it’s the second down, third to the right, go pull that one that’s flashing”, that kind of thing. So a lot of work goes into that. But that’s –





