
Recently a16z released a diagram showing the “Emerging Architectures for LLM Applications.” In this episode, we expand on things covered in that diagram to a more general mental model for the new AI app stack. We cover a variety of things from model “middleware” for caching and control to app orchestration.
Featuring
Sponsors
Fastly – Our bandwidth partner. Fastly powers fast, secure, and scalable digital experiences. Move beyond your content delivery network to their powerful edge cloud platform. Learn more at fastly.com
Fly.io – The home of Changelog.com — Deploy your apps and databases close to your users. In minutes you can run your Ruby, Go, Node, Deno, Python, or Elixir app (and databases!) all over the world. No ops required. Learn more at fly.io/changelog and check out the speedrun in their docs.
Typesense – Lightning fast, globally distributed Search-as-a-Service that runs in memory. You literally can’t get any faster!
Changelog News – A podcast+newsletter combo that’s brief, entertaining & always on-point. Subscribe today.
Notes & Links
Chapters
| Chapter Number | Chapter Start Time | Chapter Title | Chapter Duration |
| 1 | 00:07 | Welcome to Practical AI | 00:29 |
| 2 | 00:43 | Deep dive into LLMs | 01:42 |
| 3 | 02:25 | Emerging LLM app stack 👀 | 02:10 |
| 4 | 04:35 | Playgrounds | 03:32 |
| 5 | 08:07 | App Hosting | 02:39 |
| 6 | 10:46 | Stack orchestration | 05:05 |
| 7 | 15:50 | Maintenance breakdown | 03:18 |
| 8 | 19:08 | Sponsor: Changelog News | 01:35 |
| 9 | 20:43 | Vector databases | 01:53 |
| 10 | 22:36 | Embedding models | 01:51 |
| 11 | 24:27 | Benchmarks and measurements | 02:32 |
| 12 | 26:59 | Data & poor architecture | 02:42 |
| 13 | 29:42 | LLM logging | 03:02 |
| 14 | 33:01 | Middleware Caching | 04:31 |
| 15 | 37:32 | Validation | 03:21 |
| 16 | 40:53 | Key takeaways | 01:43 |
| 17 | 42:36 | Closing thoughts | 01:38 |
| 18 | 44:23 | Outro | 00:44 |
Transcript
Play the audio to listen along while you enjoy the transcript. 🎧
Welcome to another Fully Connected episode of Practical AI. In these episodes, Chris and I keep you fully connected with everything that’s happening in the AI community. We’ll cover some of the latest news, and we’ll cover some learning resources that will help you level up your machine learning game. I’m Daniel Whitenack, I’m the founder of Prediction Guard, and I’m joined as always by my co-host, Chris Benson, who is a tech strategist at Lockheed Martin. How are you doing, Chris?
I’m doing very well, today, Daniel. How are you?
I’m doing great. I am uncharacteristically joining this episode from the lobby of a Hampton Inn in Nashville, Tennessee… So if our listeners hear any background noise, they know what that is.
So you have a built-in audience right there.
A built-in audience; the people in this lobby are unexpectedly learning about AI today, which I’m happy to do… Yeah, out here visiting a customer on-site, and… Yeah, it’s nice to sit back and take a break from that, and talk about all the cool stuff going on.
Excellent. Well, I’ll tell you what, we have had so many questions and kind of sorting out all the things that have happened the last few months, and over the last year… And we’ve done a couple of episodes, we were trying to kind of clear out generative AI, what’s in it, what LLMs are, how they relate, and stuff like that… What do you think about taking a little bit of a deep-dive into large language models, and kind of all the things that make them up? Because there’s a lot of lingo being hurled about these days.
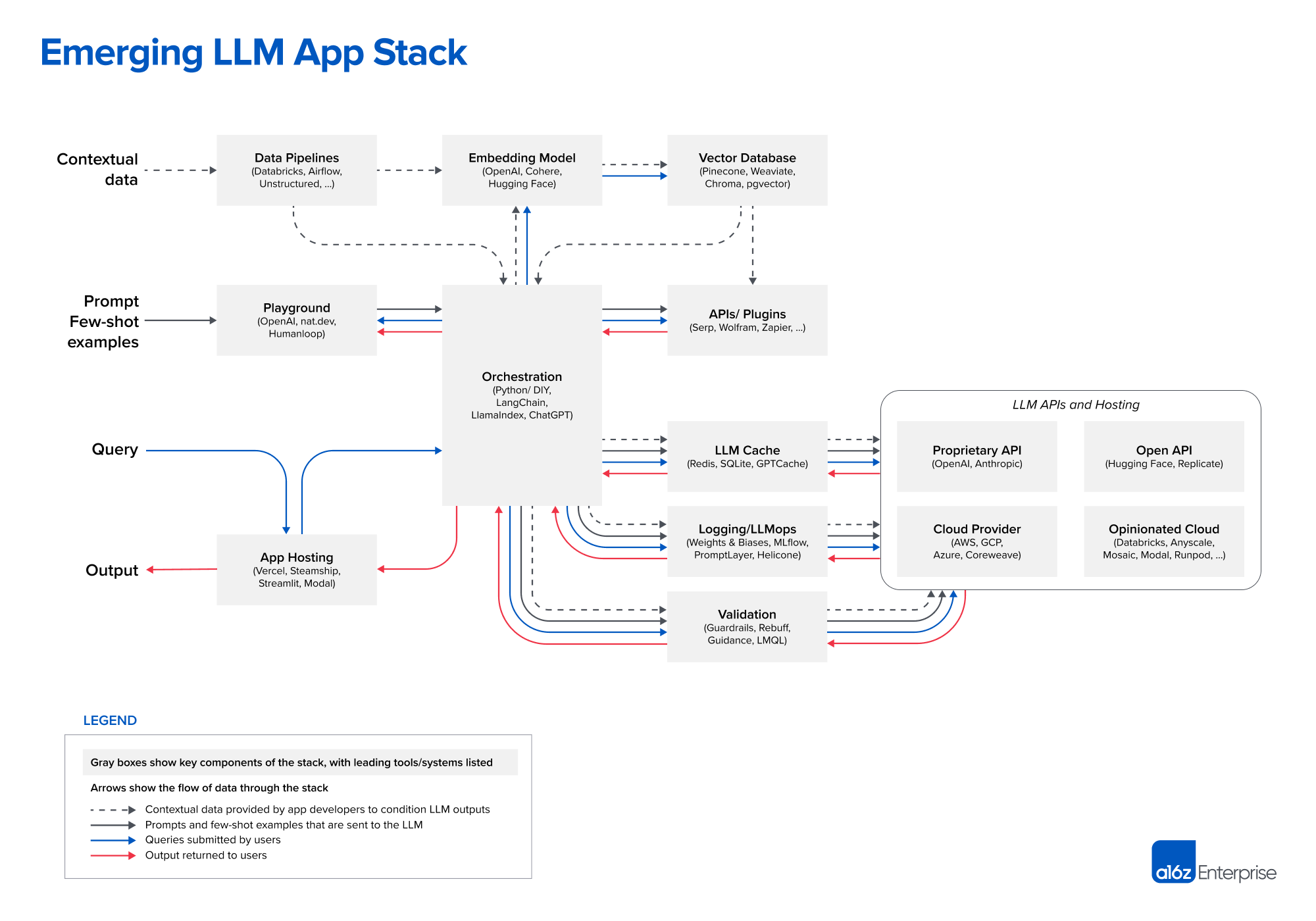
Yeah, I think maybe even outside of LLMs there’s this perception that the model, whether it be for image generation, or video generation, or language generation, that the model is the application. So when you are creating value, the sort of model, whether that be LLaMA2, to or Stable Diffusion, Excel, or whatever, that somehow the model is the application, it’s providing the functionality that your users want. And that’s basically a falsehood, I would say. And there’s this whole ecosystem of tooling that’s developing around this… And one of the things that I sent you recently, which I think does a good job at illustrating some of the various things that are part of this new ecosystem, or this new generative AI app stack, was created by Andreessen Horowitz. They’ve created a figure that’s like an emerging LLM app stack; we’ll link it in our show notes. I think it goes though maybe more generally than LLMs… But that provides maybe a nice framework to talk through some of these things. Now, of course, they’re providing their own look at this stack, especially because they’re invested in many of the companies that they highlight on the stack… But I think regardless of that, they’re trying to help people understand how some of these things fit together. Have you seen this picture?
I have, and I appreciated when you pointed it out a while back there. It definitely is an interesting – I haven’t seen anything quite like it in terms of putting it together, and some things they seem to dive into more than others in the chart… It will be interesting to see how we parse that going forward here.
Yeah. And maybe we could just take some of these categories and talk them through in terms of the terminology that’s used, and how they fit into the overall ecosystem. We can take an easy example here, which is one of the things that they call out, which is playground. Now, I think this is probably the place where many people start their generative AI journey, let’s say… So they either go to – I think within the playground category there would be, like, ChatGPT might fit in that category, where you’re prompting a model, it’s interactive, it’s a UI… You can put stuff in, you can put in a prompt and get an output.
Now, ChatGPT is maybe a little bit more than that, because there’s a chat thread, and all of that… But there’s other playgrounds as well. So you can think of Spaces on Hugging Face, that allow you to use Stable Diffusion, or allow you to use other types of models… There’s other proprietary kind of playgrounds that are either part of a product, or are their own product… So OpenAI has their own playground within their platform; you can log in and try out your prompts. There’s nat.dev, which is a cool one that kind of allows you to compare one model to the other… There’s other products… Like, I would say something like Clipdrop, which is a tool that lets you use Stable Diffusion, and you can just go there – you can try out prompts for free; you can pay up if you need to use it more. So there’s a limit to that. But there’s a lot of these playgrounds floating around, and that’s often where people start things.
[06:02] It’s funny, the playground itself as a category has a lot of subcategories, I think, to it… Because you’ve already kind of called out kind of diversity of what you might – in the cloud providers, for instance, all the big cloud providers have their own playground areas. Nvidia has a playground area… I think it’s almost becoming a ubiquitous notion. And of course, all these playground areas for the commercial entities are focused on their products and services, definitely, but trying to bring some cool factor to it.
Yeah. It’s almost like a demo or experimentation interface. So if we define this playground category, it’s usually - but not always - a browser-based playground, or a browser-based interface, where you can try to prompt a model and see what the output is like. I think that would kind of generally be true. Maybe there’s some caveats to certain ones… Midjourney, for example, is a Discord bot. Or there’s still a Discord bot that you could use, maybe that fits into the playground. But generally, these are interactive and useful for experimentation, but not necessarily useful to like build an application.
Yeah, I agree. And another thing to note about it from a characteristic standpoint is not only is it really – it’s not made for you to go build your own thing, it’s made for you to try the kind of the stuff of whatever the organization is doing. But they do it – they provide the resources. So by being in a browser, you don’t have to have a GPU on your laptop…
You don’t have to have resources, yeah.
Yeah. You don’t have to have all the things. Through various means, they set up all that for you on the backend, whether it be just calling a service, or whether it be creating a temporary environment through virtualization… But it is a good way to either to test out a new product line, or to just get your toes wet a little bit, if you want to try some stuff out; maybe you’ve been listening to the Practical AI podcast for a little while and a particular topic grabs you; that would be a good place to go.
Yeah. And I think within that same vein, you could transition to talk about this other category, which is not unique to the generative AI app stack, let’s call it, but it’s still part of the stack, which - they have called out app hosting. So that’s very generic. So in here would fit things like Vercel, or I would say generally the cloud providers, and the various ways that you can host things, whether that be an Amazon with ECS, or App Runner, or whatever that is… Or even your own infrastructure, your own on-prem infrastructure, if you host things. Now there are, I would say, a number of hosting providers that are kind of cool and trendy, and people that are building new AI apps, they seem to gravitate towards, let’s say, Vercel, and a lot of frontend developers that use Vercel, which I think is an amazing platform. So cool. That hasn’t traditionally been like a data sciency hosting way of doing things, but it represents, I think, this new wave of application developers that are developing applications, integrating AI… And you see some of those now kind of coming into or being exposed in this kind of wider app stack.
Which is a good thing, because we’ve talked for a long time, even as we opened this conversation up saying the model is not the app; you have to wrap the model with some goodness to get the value out of it, to be productive with it… And so I personally like the fact that we’re seeing the model hosting and the app hosting are starting to merge… Because I think that’s more manageable over time. It’s less being in its own special category, and it’s more about “Okay, every app in the future is going to have models in it, and so we’re accommodating that notion.” So I like seeing it go there. I’ve been waiting for that for a while.
[10:05] Yeah. And to really clarify and define things, you could kind of think about the playground that we talked about as an app that has been developed by these different people, that illustrates some LLM functionality… But it’s usually not THE app that you’re going to build; you’re gonna build another app that is exposed to your users, that uses the functionality… And you’ll need to host that either in ways that people have been hosting things for a long time, or new, interesting patterns that are popping up, like things that Modal is doing, or maybe things that frontend developers really like to use, like Vercel, and other things. But there’s still that app hosting side.
Now, where I think things get interesting is you have the playground, you have the app hosting, but regardless of both of those, what happens under the hood. And this is, I think, where things get quite interesting and where there’s a lot of differences in the kind of emerging generative AI stack, compared to the maybe more traditional, non-AI stack. In the middle of the diagram - we’re talking about this emerging LLM app stack diagram, which I think also is, again, more general - is this layer of orchestration. So I don’t know about you, Chris, but I am old enough, I guess - you don’t have to be that old, I don’t think, to… When someone says “orchestration”, I think of like Kubernetes, or like container orchestration…
Yeah.
Maybe that’s my own bias coming from working in a few microservices-oriented startups, and that sort of thing. But this is distinctly not the orchestration that’s being called out here. In the generative AI app stack there’s a level of orchestration which in some of my workshops I’ve been kind of referring to as almost like a convenience layer… Think about like when you’re interacting with a model… Let’s give a really concrete example; let’s say I want to do question and answer with an LLM. I need to somehow get a context for answering the question, I need to insert the question and that context into a prompt, and then I need to send that prompt to a model, I need to get the result back, and maybe do some like cleanup on it. I have some stop tokens, or I want it to end at a certain punctuation mark, or whatever that is. That’s all convenience; what I would consider sort of this convenience, and what they’re calling orchestration around the call to the model. And so this orchestration layer, I think, has to do with prompt templates, generating prompts, chains of prompts, agents, plugging in data sources, like plugins… These are all things that kind of circle around your AI calls, but aren’t the AI model.
Yeah, I mean, it’s the software around it, just to simplify a little bit…
Yeah, and maybe tooling. Orchestration tooling, yeah.
Yeah. It’s the stuff you have to wrap the model with, to make it usable in a productive sense. And from the moment that I saw that word, that was almost the very first thing that grabbed me… You know those little psychological quirks where you kind of notice the thing that sticks out?
Yeah.
That’s the thing that stuck out, was that it’s a big bucket that they’re calling orchestration, which is a loaded word, that can mean a lot of different things depending on what it is you’re trying to do… And the examples that they list in that category are all somewhat diverse as well. I think that was the first point where I thought, “Well, it’s a chart; the creator has a bias there.” What are some of the ways - I’m just curious - when we think about this kind of orchestration, as they say, wrapping around and providing the convenience… Any ways that you would break that up, like how you think about it? You mentioned convenience and stuff, but they go from something like Python as a programming language, to Langchain, to ChatGPT, all three very distinct kinds of entities.
[14:21] Yeah, I think that you’re kind of seeing a number of things happen here. The first one that they call out is Python/DIY. So you’re seeing a lot of roll your own kind of convenience functionality built up around LLMs, but I do think one of the big players here would be like Langchain, and what they’re doing… Because if you look again at those kinds of layers of what’s available there, you have maybe categories that I would call out… If we just take Langchain as an example, categories that I would call out of this sort of orchestration functionality would be templating… So this would be like prompt templates, for example, or templating in terms of chains… So manually setting up a chain of things that can be called in one call.
There’s also an automation component of it… Maybe this is a way that orchestration kind of fits with the older way the orchestration term is used in like DevOps and other things, where some of it could be automation-related too with things like agents, or something like that, where you have an agent that automates certain functionality… It’s not the LLM itself, but it’s really automations around calling the LLMs, or the other generative AI models to generate an image, or what have you.
They also kind of have some separate callouts for APIs and plugins. And then they have - which we can hit in a moment - they kind of have a collection of the maintenance items, the things to keep the lights on, if you will… Logging, and caching, and things like that. How do you look at that breakdown, the way they have it?
Yeah, so I think this is where they kind of have the orchestration piece in the middle there, as connecting a couple different things. One of those would be what I would consider I think more on the data or resource side, and then one is more on the model side. So I think we get splitted into those two major categories. So what are you orchestrating when you’re orchestrating something with Langchain or similar? Well, you’re orchestrating connections to resources; I’ll use the term “resources”, because it might not be data per se. It might be, like you say, an API, or another platform, like Zapier, or Wolfram Alpha, something like that.
The other side of that it’s the model side, both the model hosting and some really useful tooling around that… But let’s start on the resource side. So as you mentioned, you might orchestrate things – like, one of the things that I’ve found both really fun to do, and useful, is to orchestrate calls into like a Google search. So if I want to pull in some context on the fly, then I might want to do a Google search. That’s a call to an API, so that’s a resource or a plugin that might be conveniently integrated into your orchestration layer, either via something like Langchain, or via your own DIY code.
Another side of this would be the actual data and the data pipelines, which are your own data or data that you’ve gathered or is relevant to your problem. So again, if we’re thinking about this sort of set of resources that could be orchestrated into your app, maybe you have a set of documentation that you want to generate answers to questions out of; or maybe you have a bunch of images that you want to use to fine-tune Stable Diffusion, or something like that.
Having data and integrating it into models isn’t new, and so the things that are called out in this particular image, like data pipelines, those are also not new, and are part of this app stack if you’re integrating your own data. So things like Databricks, or Airflow, or Pachyderm, or tools to parse data, so PDF parsers, or unstructured data parsers, or image parsers, or image resizing, or all of that sort of stuff still fits into the data pipelining piece. And so you’ve either got your data coming from APIs, which might be a resource that you’re orchestrating, or you’ve got your data coming from your data sources, which might be traditional data sources of any type, from databases to unstructured data.
Break: [19:09]
Well, Chris, part of the data piece or the resource piece that is kind of unique within this new generative AI app stack is the embedding and the vector database piece. And I have to say, I’ve just got to recommend that our listeners, if they haven’t listened to our very recent episode about vector databases - because that episode goes into way more depth in terms of what a vector database is, and why people are using it… But just for a quick recap, part of what you might want to do with generative AI models is find relevant data, that’s relevant to a user query, and somehow orchestrate that into your LLM calls, either for chat, or question answering, or maybe even into image generation or video generation, in order to find relevant data. What people have found is that they would like to do a vector or an embedding search on their own data to find relevant data… And again, you can find out much more about that in our previous episode. But that’s called out in this app stack as probably something unique that’s developing, which is not just having data pipelines and databases, but having data flow through an embedding model, and into a factor database where you’re performing semantic searches.
I mean, at the end of the day, it’s a database that’s very – it works well for the kind of operation that we’re doing here. Whereas some of the traditional things that we had been working on for years before - there’s kind of a context shifting in terms of how you’re handling data, what data is, how it’s organized… So this makes a lot more sense.
Yeah. And I should call out here too, part of the stack here - and I’m glad that they called it out in this way in the schematic that we’re looking at, is the embedding model. So a lot of people are talking about these vector databases, but in order to store a vector in a vector database there is a very relevant component to this stack, which is the actual model that you’re using to create embeddings. And not all are created equal. So think about if you are working on an image problem, you may use a pre-trained feature extractor type model from Hugging Face to extract vectors that your images – so put an image and get a vector out… But if you’re working with both image and text, for example, maybe you’re going to use something like Clip, or a related model that’s able to embed both images and text in a similar semantic space. But if you’re only using text, there’s a whole bunch of, of course, choices… And all of those don’t perform equally for different types of tasks as well. If you search on Hugging Face, or just do a Google search for a Hugging Face embeddings leaderboard, there’s actually a separate leaderboard. So Hugging Face has a leaderboard for open models and how those score in various metrics. They also have a leaderboard for embeddings, and you can click through the different tasks. Let’s say you’re doing retrieval tasks, like we’re talking about here from a vector database. You can see which embeddings perform the best according to a variety of benchmarks, in retrieval, or in summarization, or other things.
[24:27] Do you use that a lot when you’re putting models and storing them into vector databases, and figuring out the embeddings, do you tend to go and see what is going on? Because right now, there’s so much happening in that space. Does that make for a good guidepost for you?
Yeah, yeah. And I think what is also useful is looking at those performance metrics, but also, at least on the Hugging Face leaderboard, and some other leaderboards - so if you’re working with text, one of the major tools for creating these embeddings in a really useful way is called sentence transformers. And they have their own table where they have measured and benchmarked various embeddings that can be integrated in sentence transformers. That’s useful, but it’s also useful to look at the columns, whether you’re looking in the Hugging Face leaderboard, or the [unintelligible 00:25:18.01] transformers, or wherever you’re looking, at the size of the embedding, and the speed of the embedding… Because it was called out when we had our vector database discussion, but only in passing… Let’s say you want to embed 200,000 PDFs. So I just ran across this use case with some of the work that we’re doing, and it can take a really, really, really, really long time, depending on how you implement it, to both parse and embed a significant number of PDFs. The same would be true for documents, or other texts, or other types of data even.
So when you’re looking at that, there’s two implications here. One is how fast am I able to generate these embeddings? Do I have to use a GPU, or can I use a CPU? Because there’s going to be a different speed on GPUs versus CPUs. And how big are the embeddings? This is another kind of interesting piece, which is if I have got embeddings that are 1000 or more in dimension, that’s going to take up a lot more room in my database and on disk than embeddings that are 256, or something like that. So there’s also storage and moving around data implications to how you choose this embedding space. So there’s a lot of, I think, practical things that maybe people skip over here. When they’re just doing a prototype with Langchain and some vector database, it’s easy. But then, as soon as you try to put all your data in, it gets much harder.
You raised a question in my mind, and I’m going to throw it out; you may or may not be familiar with what the answer would be… But when you’re looking at vector databases, and you’re looking at all the diversity and embedding possibilities here, and the fact that has kind of physical layer consequences, in terms of storage and stuff like that… Are we seeing that in vector or other database arenas where they’re trying to accommodate this new approach to capturing data in terms of having embeddings with the rise of vector databases? It seems that there would be a whole lot of kind of vendor-related research on how you do that. Because to your point a moment ago, you’re talking about data at such a volume that poor architecture in terms of what’s under the hood could have some pretty big consequences there.
[27:51] Yeah, I think that’s definitely true. And there was a point that was made in one of our last episodes that the vendors for these things are having different priorities that don’t always align. So some are optimizing for how quickly you can get a large amount of data in, but maybe they’re not as optimized for the query speed. Some are optimizing for query speed, but it might be really slow to get data in. And so that’s one piece of it.
I think another piece of it is how large of an embedding do you need, and how complicated is your retrieval problem? I would recommend that people do some testing around this, because let’s say you have 100,000 documents that are very, very similar one to another, or 100,000 images that are very, very similar to one another, and the retrieval problem is actually semantically very difficult. You might need a larger embedding and more kind of power, even like optimization around the query, like re-ranking and other things to get the data that you need. Whereas if you have 100,000 images and they’re all fairly different - well, maybe you don’t need to go to some of those lengths.
So yeah, I think that that’s also part of this problem, and people are still feeling out the best practices around some of this, partially because it’s this kind of new part of the AI stack, and partially because things are constantly updating as well… So if you use this embedding today, there’s a better one tomorrow, and vector databases are updating all the time… So it’s also just a very dynamic time here.
As we look at the chart here, and there’s kind of the three that we referred to earlier that are kind of together, and those are LLM cache, logging/LLM ops, and validation… First of all, could you kind of describe what’s encompassed in each of those, and also kind of why are they fit together? Why are we seeing those lumped in one category here, one super-category?
Yeah. So if you think about what we’ve talked about so far, there’s this new generative AI stack, whether you’re doing images or language or whatever, there’s an application side, which might just be the playground, or it might be your own application… There’s a data and resources side, which is what we’ve talked about with integrating APIs, and data sources… And then there’s a third arm here, which is the model side. And all of those are kind of connected through the orchestration layer, or the automation layer, the convenience layer, whatever you want to end up calling that.
So now we’re kind of going to this third arm of the model side… And we can come back to it here in a second, but one side of this is just hosting the models and having an API around them, which we can come back to. But between the model and your orchestration layer, almost as – maybe we could call it like model middleware… I’ll just go ahead and coin that – I just coined it on… Or maybe people are already referring to it that way, and I didn’t coin it. But model middleware sits kind of either wrapping around, or in between your orchestration layer and your model hosting. And these are the things that you’re referring to around caching, logging, validation.
Probably the one that people are most familiar with if they are familiar with one of these would be the logging layer, which is, again, something that is kind of a DevOpsy infrastructure term… But here, we might think of a very specific type of logging, like model logging, which might be more natively supported in things like Weights & Biases, or ClearML, or these other kind of MLOps type of solutions, where you’re logging requests that are coming in, prompts that are being provided, response time, GPU usage… All the kind of model-related things, and you want to put those into graphs and other things.
So there may be specific kinds of logging… So how quickly, on average, is my model responding? What is the latency between making a prompt or a request and getting a response? How much GPU usage is my model using, and do I need more replicas of that model? These sorts of things can be really helpful as you’re putting things into production. So that’s a first of these middleware layers.
Break: [32:47]
So Chris, the other middleware layers, I would say, that have been called out, at least in what we’re looking at, are validation and caching. So I’ll talk about caching, and then we can talk about validation a little bit, which is close to my heart… But caching - let’s say that, again, this already happens in a lot of different applications. So think about like a general API application. If someone makes a request for data in your database, and you retrieve that data, and then the next user asks for the same data in your database, the proper and smart thing to do would not be to do two retrievals, but to cache that data in the application layer in memory, so that you can respond very quickly and reduce the number of times that you’re reaching out to your database, and things like that.
I noticed in this chart that some of the examples that they put for caching, such as Redis and SQLite and such, are very typical and long-term players in the app dev world.
Yup.
So does that beg the question – or at least for me, begging the question that when you’re caching… Like, you’re really talking about, for the input, here’s an output, whether it goes to a model or not. Is it really just application data that you’re caching at that point?
So it’s caching in that sense, but I think there’s maybe implications to it that go beyond kind of normal caching… You know, running AI models is expensive most of the time, because you have to run them on some type of specialized hardware. If I’ve got a model running on two A100s, I would rather not have four replicas of that model. I would rather just have one, if I can, because I don’t want to pay for all those GPUs. So part of it is really related to cost and performance. So it’s also for a large model - this is mainly for large models, I would say - you’ve got a lot of cost, either because you’re running that model on really specialized hardware, or because – like, if I’m calling out to GPT-4, it’s really expensive to do a lot of requests to GPT-4. So in order to deal with that, if you have a prompt input, you can cache that prompt, and if users are asking the same question, I would rather just send them back the same response from GPT-4, or my large LLaMA 2 70 billion model, or whatever it is; I’m going to respond to them the same way, based on the same or a similar input.
The other implication to this, which in my mind it sort of fits in to caching, but maybe not in the traditional sense… So I normally think of caching as like “Oh, I’m going to cache things in memory, or locally, at the application layer.” But if you’re caching prompts and responses, there is a real opportunity to leverage that data to build your own sort of competitive moat with your specific generative AI application.
[36:18] For example, you’ve got a user base, they’re prompting all of these sorts of things… All of a sudden, if you’re saving all of that data and the responses that you’re giving, you’re essentially starting to form your own domain-specific dataset, that you could kind of leverage in a very competitive way in kind of two senses. One is right now, if you’re using a really expensive model to make those responses; maybe you start saving those responses from the really expensive model, and you can use that data to fine-tune a smaller model that might be more performant and cost-effective in the long term. So it’s an operational kind of play.
The other way is, if you’re gathering that over time and you actually have the resources to human label that, or give your own human preferences on that, or certain annotations on that, that now is your own kind of advantage in fine-tuning either one of these generative models, or your own internal model for the domain that you’re working in. So it’s caching, but that’s almost like a feedback or data curation side of things as well.
So you mentioned earlier that validation was close to your heart…
Yeah. So as our users know, I think part of the tooling that I’m building with Prediction Guard would fit into this category. It would actually span, I think, more categories… It’d kind of span between validation and orchestration and model hosting. So there’s kind of a little bit of overlap there. But this validation layer really has to do with the fact that generative AI models across the board, I think people would say are – there’s a lot of concerns around reliability, privacy, security, compliance, what have you… And so there’s a rising number of tools that are addressing some or all of those issues. So whether it be putting controls on the output of your LLM… Again, think about this as a middleware layer. My LLM produces something harmful as output, or my generative AI model generates an image that is not fit for my users… I want to somehow catch that and correct it if I can. Or I want to put certain things into my model, but I want to make sure that I’m not putting in either private or sensitive data, or I want to structure the output of my model in a certain way, into certain structures or types, like JSON or integer or float… All of these sorts of things kind of – I personally would break this apart probably into maybe like validation type and structure, and then security-related things… Because there’s a lot here. There’s validation, which is like “Is my output what I want it to be?” There’s security-related things, which is “Am I okay with putting the current request into my model, or sending the output back to my users?” And then there’s type, and structuring things. So with images, like, is the image upscaled appropriately for my use case? Or with text, if I’m putting in something and wanting JSON back, is it actually valid JSON? That’s more of a structure type-checking type of thing. So there’s a lot in this category, and I think you’re probably getting the fact that I’m thinking a lot about this, and there’s a lot here…
I can tell.
[39:58] But yeah, other things fitting in this category would – I think a cool one called Rebuff which is checking for prompt injections, for example; that’s like part of that security side of things. There’s things like Prediction Guard and GuardRails guidance outlines now, that do type and structure type of things… There is also, I would say, a layer of this which a lot of people are implementing in the kind of roll your own Python DIY way as well, which in Prediction Guard we implement some of these, but also people are implementing them in their own systems, like self-consistency sampling… Like calling a model multiple times, and either choosing between the output, or merging the output in some interesting way, or things like that, this sort of consistency stuff… I think a lot of people are rolling their own, too.
As we start winding up here, what do you think are some of the takeaways from this chart? Or what brings top of mind things that people as they look at it might benefit from? How would you see it in the large?
Yeah, it’s a good question. I think one major takeaway, one thing to keep in mind is the model is only a small part of the whole app stack here… In a similar way to, like it used to when a thing existed called data science. We would say training a model is only a very small part of the kind of end-to-end data science lifecycle of a project. There’s a lot of other things involved, and I think here you can make a similar conclusion. The tendency is to think of the model as the application, but there’s really a lot more involved, and our friends over at Latent Space would say this is really where AI engineering comes into play. This space of AI engineering seems to be developing into a real thing; whether you call it that word or not, it is part of what this is.
So that’s one takeaway… I think the other takeaway is maybe just kind of forming this mental model around these three spokes of the stack. So you’ve got your app, and app hosting, you’ve got your data and your resources, and you’ve got your model and your model middleware. And that kind of middle hub would be some sort of orchestration that you’re performing, either in a DIY way, or with things Langchain to connect all of those pieces together.
So you’re probably hoarse by now, because we’ve pulled so much information out of you… This was a really, really good dive… It’s one particular publisher’s way of looking at it, but we’ve never really dived into all the components of the infrastructure of a stack with this kind of – and I think most people haven’t had a chance to see it yet, because so much of this has really arisen in recent months. Thanks for kind of wearing half of a guest hat along the way here, and taking us through this on this Fully Connected episode.
Yeah, and I think, in terms of learning about these things, I think people can check out our show notes. We’ll have a link to the diagram that we’ve been discussing here. I would say learning-wise, this helps you organize your thought process, but to really get an intuition around these things, you can look at various examples in this diagram, and go to their docs, and try out some of that. There’s a variety of kind of end-to-end examples as well that are pretty typical these days… Like, in language, if you’re doing kind of a chat over your docs thing that involves a model and a data layer and an application layer… So just building one of these example apps I think could give people the kind of learning and that sort of thing that they need. But yeah, it’s been fun. It’s always helpful to talk these things out loud with you, Chris. I find it very useful.
Well, I learn a lot every time we do this… So thanks a lot, man.
Yeah, yeah. Well, we’ll see you next week.
See you next week.
Our transcripts are open source on GitHub. Improvements are welcome. 💚