Today we are talking with Maikel Vlasman, technical lead for a large Dutch machine construction company, and a cloud engineer by heart. We cover self-updating GitLab & ArgoCD, Maikel’s thinking behind dev environment setup and a Kubernetes workshop that he is preparing for his team. The goal is to function as a true DevOps team with shared responsibilities.
This conversation started as a thread in our community Slack - link in the show notes. Thank you Maikel for being a long-time Changelog listener and for reaching out to us - we enjoyed telling this story.
Featuring
Sponsors
Akuity – Akuity is a new platform (founded by Argo co-creators) that brings fully-managed Argo CD and enterprise services to the cloud or on premise. They’re inviting our listeners to join the closed beta at akuity.io/changelog. The platform is a versatile Kubernetes operator for handling cluster deployments the GitOps way. Deploy your apps instantly and monitor their state — get minimum overhead, maximum impact, and enterprise readiness from day one.
Raygun – Never miss another mission-critical issue again — Raygun Alerting is now available for Crash Reporting and Real User Monitoring, to make sure you are quickly notified of the errors, crashes, and front-end performance issues that matter most to you and your business. Set thresholds for your alert based on an increase in error count, a spike in load time, or new issues introduced in the latest deployment. Start your free 14-day trial at Raygun.com
Sentry – Working code means happy customers. That’s exactly why teams choose Sentry. From error tracking to performance monitoring, Sentry helps teams see what actually matters, resolve problems quicker, and learn continuously about their applications - from the frontend to the backend. Use the code SHIPIT and get the team plan free for three months.
Chronosphere – Chronosphere is the observability platform for cloud-native teams operating at scale. When it comes to observability, teams need a reliable, scalable, and efficient solution so they can know about issues well before their customers do. Teams choose Chronosphere to help them move faster than the competition. Learn more and get a demo at chronosphere.io.
Notes & Links
- 2 months ago, Maikel reached out via our Slack
- 🎬 Introduction to Docker - the video that introduced Maikel to cloud engineering
- Terraform Argo CD - set up Argo CD in K8s & then maintain everything (including Argo CD) using Argo CD GitOps pull functionality

Transcript
Play the audio to listen along while you enjoy the transcript. 🎧
Two months ago Maikel reached out via Slack and he said "Hi, all. This long-time listener from when Changelog was in the 5by5 network has finally joined the Slack." I like that you referred, Maikel, to yourself in the third person. That was very good. "You definitely impacted my career and love for the open source community. Big love and thank you."
Maikel, I'm very happy to welcome you here today on Ship It. Welcome!
Thanks for inviting me.
So these are my favorite stories, the long-term ones. When was, by the way, the 5by5 network? How long ago was that, Maikel?
Wow…
I listened to other podcasts in that network, so I also came across this one. At the time I was really busy with Docker, and in 2013 there was a talk from Solomon Hykes in the Twitter meeting, where I learned about Docker. So that was my inspiration to go full-on web development.
So the tweet from Solomon inspired you to go into web development full-time?
Yeah, I came across a demo from the first Docker intro.
Okay, I'll mention it to him. I'm sure he'll be very glad to hear that. Okay… So what inspired you (I'm very curious) from that tweet? What was it?
It showed me that the world is gonna change with the technology that Docker provides us. I even set my story on hold to fully focus on Docker and to learn the technology, and that full year I did that for school, for my study, because I thought it would change the world.
The next year I had an internship at a company where I introduced Docker, and then later on Kubernetes, and that was a great success. I'm very thankful for Docker… And Kubernetes, of course.
Are you still using Docker today?
Yes, but I use another tool, Rancher Desktop, and more like the OCI general tools which are available.
Okay. But when it comes to running your applications, the ones that you're a part of, you're not using Docker in production to run them. You're just using Docker locally – well, you're using Rancher Desktop locally to build images, I'm assuming?
Yeah, it's quite a different setup nowadays. I'm using Kaniko to build the images in the cluster itself.
So that is used with Kubernetes. Do you have a local Kubernetes, or do you target a remote Kubernetes?
Yeah, it's a local Kubernetes cluster with Rancher, and that one builds images.
Okay. You're using Kaniko, okay. That's good to know. Cool. See? Side-tracked by technology. Can you tell I'm a nerd for this? Whenever I hear things like that, like "Yes, tell me more. Tell me more." Okay. So when you introduced yourself two months ago you said that you're a cloud engineer by heart. What did you mean by that? And specifically, what does it mean to you to be a cloud engineer?
Well, for me it's a way to enable the developers in the team, and UX designers, to deliver the software. So a full-on focus on the developer experience, from the moment you're beginning to code, to when it's in a feature side or review app to production. I'm focused on making that experience great, so their potential can be used to the full extent.
So if cloud shipper was a role – I think you're a cloud shipper; you're shipping code into the cloud… Okay. What is the difference between what you just mentioned and a platform engineer?
I think as a cloud within the team you have more connection with your development team. So you stand close to them and you can discuss – I think you're more integrated into the project, for example.
Okay. I know that the platform engineers are more about the self-service model, so what do they need to build so that others can just consume it themselves, via docs, via APIs, and less about helping them go through that, and provision things, or set things up. So I think it would help me understand a bit better if you were to describe your day to day. What does your day to day look like when it comes to interacting with the engineers, with the admins? Do you have admins? I'm not sure whether you have admins…
Okay, so no infrastructure ops sort of people. Okay. And the frontend –
Oh, sorry, we have admins.
Yeah, that's fine, that's fine. So when it comes to your day to day, what does it look like when it comes to interacting with all those different types of roles with the company?
For now, we are migrating from on-premise to cloud. So for now it's mainly setting up the new stuff in a greenfield… And the challenge is for me now to keep the engineers so that they can keep their work going, and so that they aren't blocked in their work.
So do you have mostly backend developers that just develop APIs, or what do the engineers develop?
It's both frontend and backend.
And do you have the SRE type or the ops types, the ones that look after the systems, or are they fully managed? What does that look like?
Yeah, so we have multiple people, and some people [unintelligible 00:09:26.13] so they do a lot of the database actions. Other people focus purely on the frontend, and others purely on the backend. My goal also is for the team to be able to – so that everyone can, for example, add an environment variable to a deployment if they need to have that. And that they don't depend on some ops person to do that.
That's nice. That's a self-service model where people know how to make the changes. There must be some documentation, I imagine, that they can look up… They know how to make, and when the change is made, I think this is like a bit of the GitOps model - it's in a repository, it gets merged, it gets applied to the environment. Is that right?
Yeah, that's correct.
So what does your stack look like, I'm wondering? Because that will help me understand a bit better in terms of the technology that you use, whether it's front-facing, whether it's a mobile app, whether it's multiple things… What does that look like?
Yeah, so the greenfield new cloud environment contains Terraform, first of all, which on a button it's able to deploy all that's needed, so like a Kubernetes cluster, VPCs and all that.
Where does this Terraform run? Sorry to interrupt.
For now, it runs in Azure DevOps. We tied it to that one. The goal is to have it in GitLab CI, because it enables us to be a bit more flexible, and we think it's the more mature platform for how it works. Also, I'm a big fan of GitLab myself, so that's why.
So GitLab is the CI/CD system, or just the CI system?
Both.
Both, okay. So GitLab CI/CD, and you have some pipelines that provision infrastructure; that is provisioned using Terraform. The infrastructure is Kubernetes… Other things, other than Kubernetes clusters?
Many Kubernetes, and the database is separately managed by another team for now. But maybe in the future it moves also to cloud.
And where do you provision the Kubernetes clusters?
Yeah, it's in Azure for now, but we have made it so that it's also able to run in GKE, in for example. So we made it cloud-agnostic as much as possible, so we can move to another cloud if that's required.
So after Kubernetes comes up and there's this managed database that comes up, what happens next?
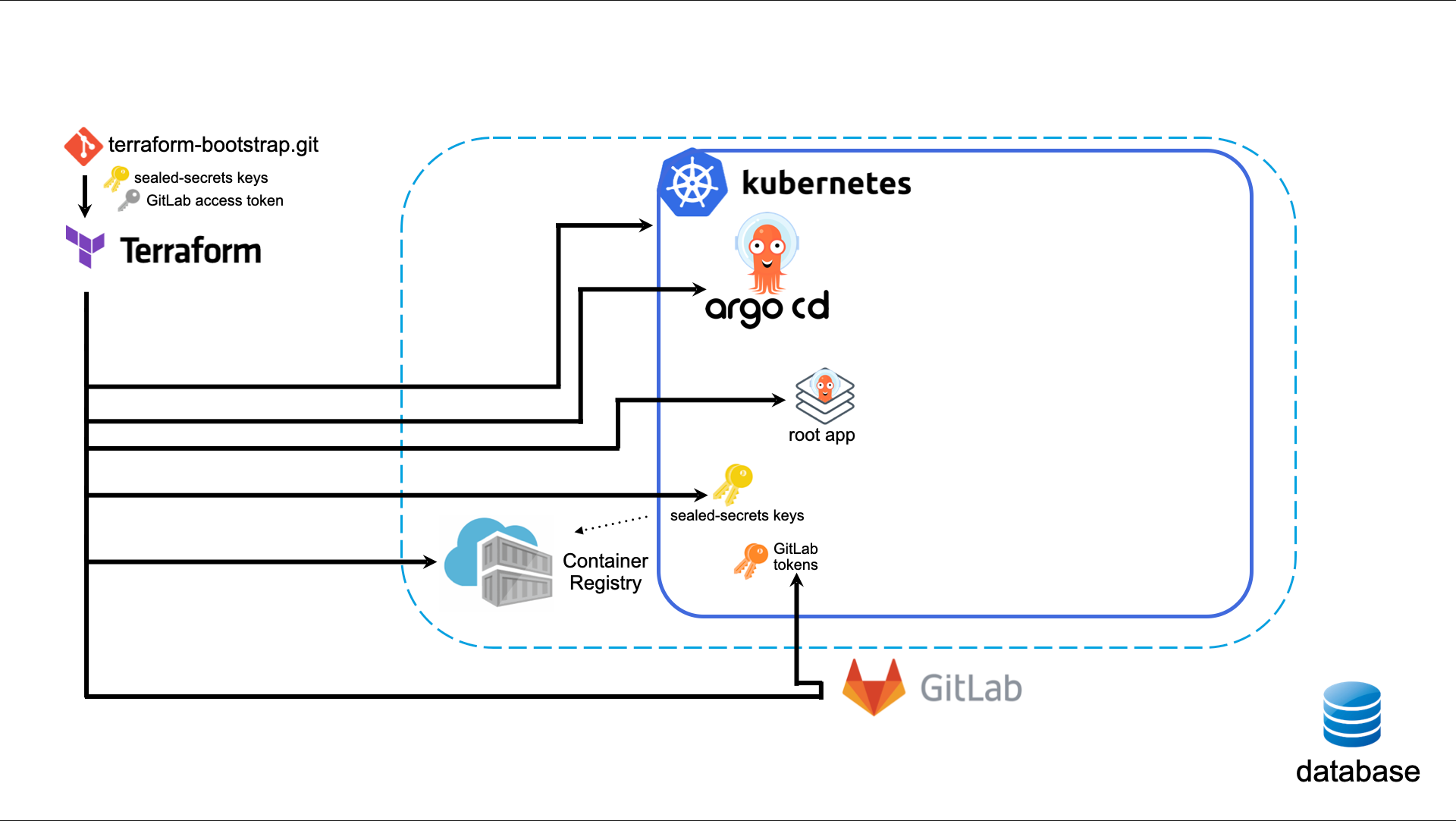
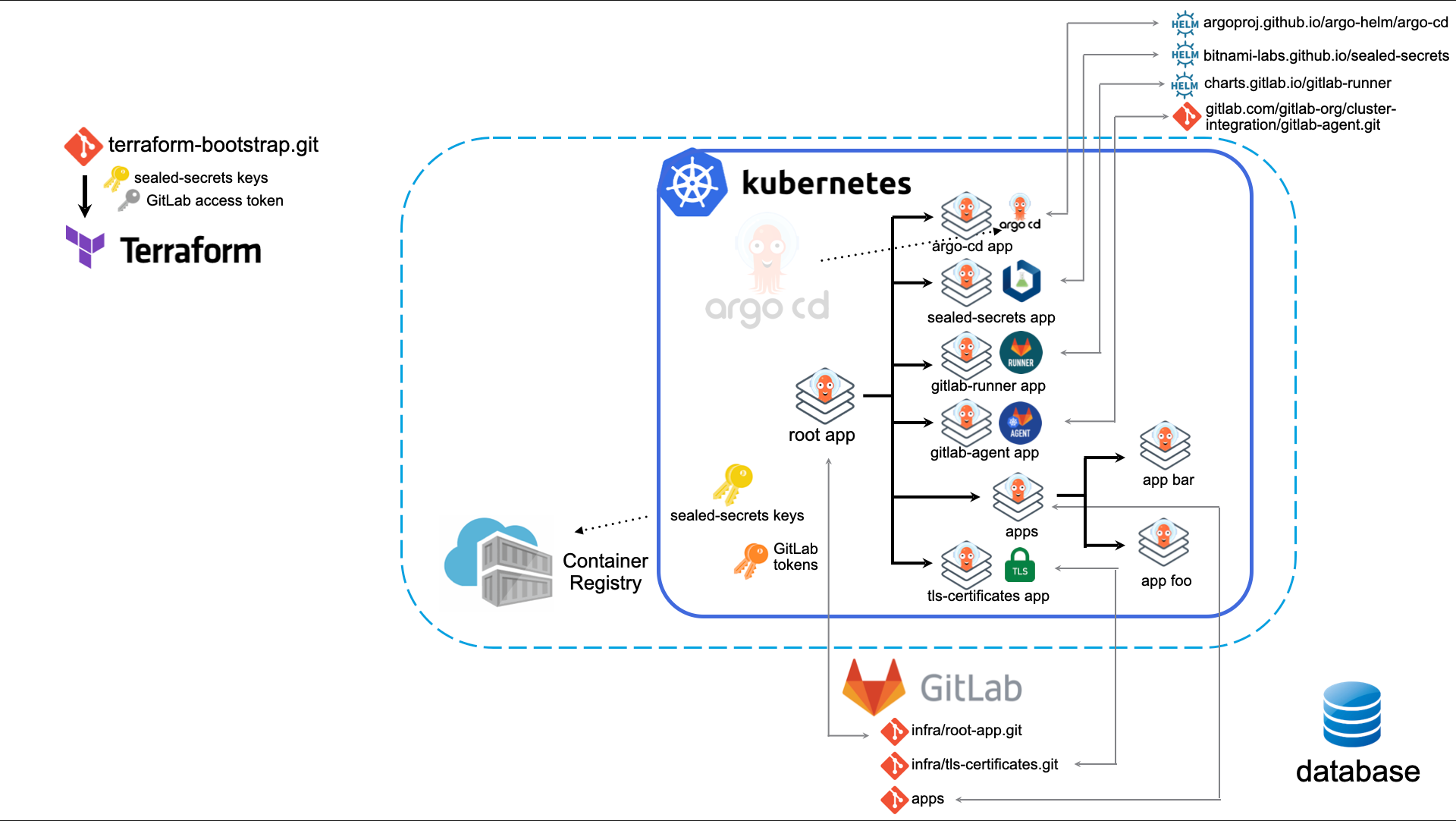
[11:53] For now, the managed database is not in place yet. So it's for the future. But yeah, we have Argo CD installed via that Terraform script. So in the terraform apply it creates Argo CD with a Helm chart, then it pulls down from the Git repo the root application, the Argo CD application, and from that one it spins up all necessary tools, for example an Ingress controller. Argo CD itself is also managed by Argo, so that's also quite a nice thing, to be able to manage Argo through Argo.
That's very interesting. I mean, if Argo manages itself, what happens if it's upgrading itself and it's still running? Will the run fail?
Well, in the end it can fail, if there's a missing chart value, for example. But we wanna set up the Prometheus monitoring tool to lock that, and then it notifies us that it's failed. But if you're operating Argo through the latest release, what you face on the UI…so…you see that it fails.
But what I'm wondering is if Argo is upgrading itself, Argo is running while it's upgrading, the upgrade gets applied, which means that the run will have to be stopped, because it just needs to basically restart with a new version. And when that happens, how does it continue the upgrade? Because the upgrade failed, because it was updated. Do you see what I mean?
Yeah, I see what you mean. So it's using the deployments, for example, for the controller. It tears down the old controller when the new controller is up, so in that way it keeps running. I tested it thoroughly, so it worked for quite a few releases now.
Is this a done thing, where a service can update itself in Kubernetes? This is a very interesting pattern which I haven't seen.
Yeah, so first of all, when Terraform is applied, it fetches the local repository from our GitLab instance, and it looks at the values of that Argo CD, and then for one time it does a local Helm install, and from there on it watches that root repository, and then Argo CD takes over that initial Helm install. So that way we can update the version of Argo and then it will be released in the cluster.
Now, this sounds very interesting. Do you have some code that is publicly available for me to look at, just to see how you configure this? Because this is super-interesting to me.
Yeah, I can make it available. It's okay.
Yeah, that would be very nice, to see how Argo CD can update itself without any downtime, and then when the run finishes, it succeeds, and Argo itself is at a new version. That is very cool.
Yeah. And that same one applies to how I used to administer GitLab, a self-hosted version of GitLab. We also wanted with that GitLab instance, once a month at least, with the patch releases, I needed to roll a script and then update GitLab, and then we started it. So just like Kelsey Hightower mentioned in a previous episode, when you want to automate it, first you have to know exactly how you do it manually. So that was also a great lesson from Kelsey Hightower.
So I was tired of operating that by myself, so I automated the whole process. So once a night there will be run a GitLab CI job on the schedule, which checks if there's a new release or a new patch release of GitLab, and then it creates a merge request for itself. So there's a CI which creates a merge request and assigns it to the administrator. Then the administrator can merge that merge request, and then GitLab, using GitLab CI, will apply itself to the cluster, and then it's upgraded.
[16:16] So in this case we're talking about a self-hosted GitLab?
Yeah.
…that is running on Kubernetes, and you're merging the pull request which basically upgrades GitLab, which then GitLab runs and it gets upgraded – it basically upgrades itself in Kubernetes.
Yeah.
Okay. And again, no downtime. I'm surprised by this. No downtime.
Well, it depends. If it's a major release with migrations for the database, you have downtime. But we were a small company, with ten people, so that went smooth.
Yeah. So there is like this piece which I'm missing, around how can an upgrade continue running if the system that runs it will be taken down?
That's a good question. In the case of GitLab it's quite easy, because the CI is different; there are different deployments, different [unintelligible 00:17:11.28] than where GitLab itself is hosted. So as long as that job runs, it takes care of the upgrades in Kubernetes.
But won't that job be upgraded part of the upgrade? Because that's also GitLab that runs that job. So the job that it runs will upgrade itself, which means it will have to terminate, which means it will not know whether it succeeded or not, because it's running the upgrade.
So when a GitLab Runner gets terminated because of the upgrade, it first waits until all jobs it has assigned to it will succeed, or finish. So in that case, the Helm chart upgrade in that CI job - it will wait for that to succeed.
But then it can't upgrade itself…? So the job will not go down, because it's still running, and it's waiting for itself to be upgraded… So how does that work?
It's quite a challenge to describe in words…
Do we need a diagram? I think we need a diagram.
We need a diagram, yeah.
Okay, alright. Because that will definitely help explaining this. I remember because I was involved with similar systems that would upgrade itself. Concourse was one CI that we were using Concourse to upgrade itself. But when that was upgrading itself, like it would apply the upgrade, the job would be force-terminated, the one that was upgrading itself, so the job would fail… But the job would be configured to retrigger itself. So when the job would be scheduled again because it hasn't finished, so it will need to retry, the job would start from the beginning, it would say "Oh, this has already been done, so–"
Idempotent.
It was idempotent, exactly. It was trying to apply the same upgrade. But the second time when it would run, it would succeed, because it would see the upgrade actually was successful. And the first time when it ran, it was basically aborted. But the job was aborted, not the upgrade. I mean, that was like still running, because once you give the instruction to whatever needs upgrading - in this case it was Bosch that was basically managing the upgrade - the upgrade would go through, but Concourse wouldn't know whether it succeeded or failed. And they would try to apply it again, and then it would talk to Bosch directly in that case.
And this is not too dissimilar from the Kubernetes controller… Or shall I say the control plane. So the control plane would know what the state is, and then the job would succeed on the retry, because oh, guess what, the update has already been applied. So that is how I've seen it work… But again, the initial run would fail.
In our case it wouldn't fail. It would succeed.
Wow. Okay. I really wanna see that diagram, that's what I'm thinking.
That's cool, yeah.
That's super-interesting. Okay.
Break : [20:00]
So I know that a lot of users are using GitHub and GitHub Actions. Not that many - again, from the ones that I'm talking to - are using GitLab. What made you choose GitLab?
The GitLab CI was a while back part of GitLab itself, right before GitHub Actions was introduced. And that made it very easy to set up the CI system. There were some features in GitLab I've found very useful. For example, if you've got a readme, then you could show the source files in the web UI. And a lot of features - they weren't in GitHub yet. They are now, but…
And also, GitLab has a once-a-month release, with a lot of features every month added… So that was very nice. And also, for us it was very important to have a self-hosted GitLab, so we could upgrade to our needs if we wish.
How long have you been using GitLab for? How many years?
Actually, I started with GitLab 8 in 2013, also around that same year when I still had the old Tanuki icon. You know, the non-orange one.
I don't remember that one, I have to say. Okay, so the original GitLab icon.
Yeah. And I came across them by a DigitalOcean post. DigitalOcean had a lot of tutorials which I learned a lot from. And then I set it up at first at my home server, for the first time; then a CI was integrated into GitLab. And at my job back then, at my internship, I introduced GitLab. So we had all those nice features and feature sets, and new, shiny things. GitLab and GitHub have quite a lot in common these days, but back then the feature set differed a lot.
[24:26] Okay. So in the almost ten years since you have been using GitLab, did you have some upgrades that didn't work very well because you were self-hosting it? Any issues that you ran into it while you were running it yourself, that you wish you hadn't?
Yeah, the upgrades back then were not always that smooth. For example, maybe the major upgrades were not so smooth.
So like 8 to 9, 9 to 10? Is that what you're thinking about?
No, also the minor upgrades.
Okay.
There were bugs introduced. And then we had the option for ourselves to go back to the previous version of GitLab. That was also the reason why we wanted to self-host. We didn't want to upgrade GitLab before a major client project update.
I see. Okay. And would you ever run migrations? So rather than upgrading in-place, would you blue/green? Like, you'd stand another GitLab and then you'd migrate the data? Have you ever done that?
No, no.
Okay, so always in-place upgrades.
We had backups, of course. So in theory, we could go back with an old database.
Okay. So apart from a few issues with upgrades, things were fairly straightforward; you didn't have days and days of things where you couldn't use GitLab because something didn't work.
Yeah.
Okay, so everything was fairly easy to navigate when problems did happen.
Yeah.
That's good. Okay. And you still use GitLab today…
Yeah, indeed.
Okay. And where does Azure DevOps fit with GitLab? How do the two work? Because you have three - you have Azure DevOps, GitLab, and Argo CD. How do the three work together? Plus obviously Terraform, but that's for something else.
So it all starts with Azure DevOps in our setup, and that one is responsible for applying the TerraForm infrastructure as code in those repositories there are references to GitLab, where the other code is hosted.
Okay.
So they're not tied to each other with API, or something.
I see. And Argo CD gets deployed on the cluster, and then Argo CD manages the application, so you don't use GitLab or Azure DevOps to deploy the app. You're not using those.
No.
Okay, so Argo CD manages the app. So I remember that we got up to Argo CD. So Argo CD - does it deploy one app, multiple apps? How does that setup look like?
For now, it deploys the infrastructure which is needed, so Argo itself, and GitLab runners, and the GitLab agent; also the Ingress controller. And we want to have it so that the company applications, the actual workload is also managed through Argo.
For now, Argo CD manages the infrastructure-related workfload, so for example the Ingress, the GitLab runner, and the GitLab agent, and some other infrastructure tools. And for now, the workload is deployed using GitLab CI, a push model, so a GitOps push. The downside of that is that you need to deploy them if you've got a brand new cluster. You need to deploy them actively.
[27:58] So in contrast to a GitOps pull model, which Argo CD is using, in that case the infrastructure-as-code is as-is, and you can just continue where you left off. So in the end, we want to integrate also the workload applications [unintelligible 00:28:13.02]
That makes sense. Okay. Some of that is coming back from our Kubernetes days; when we were running our application on Kubernetes, we would start with the latest, so whatever was latest at that point in time, that's what would be pulled down. But we didn't have a declarative model that specified "These are all the things that you need to be running par to this cluster." So still you would set up the initial tools, and then you would deploy a bit more and a bit more, more of the dependencies, until you would eventually be able to deploy the application.
I know what you mean when you say that Argo CD is managing the deployment currently, but it's like that push model. GitLab does like a push-deploy of the app. Okay.
The upside of using a GitOps push model with GitLab CI to deploy your application is that in your logs of GitLab CI you see what's eventually or what's potentially going wrong. You see a failed state.
Right. So GitLab is showing you when a deployment fails, versus Argo CD showing you when a (basically) apply failed.
So if you use an automated task to release your application, it creates just a commit. But that's not showing you if the deployment fails. So that's a challenge we have to accommodate for.
So when it comes to all those different systems that do things to your infrastructure, how do you basically understand what is the source of truth, what is running where? Because GitLab does something, Argo does something else… How do you reconcile all of these systems into a single view?
Yeah. We made the documentation for that. That's the simple answer. So everyone can just continue working on it. the goal is that everybody can just go along and also edit the infrastructure.
Okay, so there is a document that people can read to understand where the different endpoints are, what basically the things to check are, whether it's the Argo CD UI, whether it's the GitLab pipeline view, whatever the case may be, where they can go and see what the current state of the world is.
I'm planning to organize a Kubernetes workshop for my team, so I can also explain to them how those things are working.
Interesting.
So that everybody has a nice understanding of the setup.
So would you expect your team members to use Kubectl, or Kube Cuttle – which one do you prefer? Hang on, this is really important. How do you call the tool, the CLI for Kubernetes? How do you call it?
I always say Kube CTL.
Kube CTL, okay. Good. I know there's so many pronunciations… It's important to use the one that you prefer. Okay, so would you expect your team members to use Kubectl directly?
Yeah, they asked for it. It feels like the same as asking for SSH access to me. I also always think about, there is a goal behind it, that why would they want Kubectl. And mainly, it's because of logs. They want to see the application logs.
Logs. Okay, yeah.
On the roadmap we also now have a goal to add Loki as a logging system… So when that's set up, they don't need access to the cluster directly.
So you're setting up all these clusters… Would you think of centralizing the logs? How would that work? Because I imagine you have a production cluster… Or first of all, how do you slice up your clusters? Is it per environment, is it per application? How does that look like?
Yeah, it's per environment. We have developement acceptance production clusters.
[32:11] Okay, so you have three clusters, and… Are you thinking of running Loki in each of them?
Yeah, it's good that you mentioned that… It's still a discussion point. The same applies to Argo itself. I heard somewhere or read somewhere that it's not very recommended to host Argo CD in that same cluster it's managing. so I would split that into a separate cluster. And that also applies to the logging system and the monitoring system, like Prometheus. So we have to think about that one.
Yeah, when you rotate the clusters, when the clusters go away, or you don't have just the three, there's a fourth one, then you have N places to look for things… And it's nice, because it's self-contained. But then it makes you wonder, "Well, shall I have a single system to centralize all these things?" And then maybe you're thinking "Should I maybe have a managed service for this? Have a service for logs?" Just as you have one for the database, so that you don't have to run those things yourself… Because then there's a contract, a commercial contract. And I know that in Europe it can be a little bit challenging because of data privacy, and all sorts of regulations around data… And that's why maybe the choice isn't as broad as it's in the U.S. But it's still better than having to worry about your logging system, or your metrics system, or whatever the case may be. And that's just like a service that you consume.
Indeed. And there's also a cost to managing it. You have to maintain it.
Exactly. Apply upgrades, and you know how fun those are…
Yeah… Especially with the Log4j CVE going around, it's quite tricky to do it yourself.
So where do you stand on that? Would you prefer to have a managed service, or would you like to run it yourself? What would you prefer?
Yeah, the nice thing about running it yourself, I've found that you are in control of when you upgrade, and whatnot. That's the main benefit of running it yourself.
So would you run it yourself?
Yeah, for now I think I would run it myself. Because if you make the maintenance story easy for everyone, even with tools like Dependabot or Renovate bot, you just have a merge request, and then merge it, and you're able to see that the rollout goes well. Then the maintenance burden should be low. But I can see why people choose for a cloud solution.
Yeah. I mean, since you run GitLab self-hosted, I kind of could have guessed which way you're going; like, you would prefer to run your service self-hosted. And I think for you, because you're based in Europe, I think the data protection and the data regulations are much easier to work with, because all the data - you know where it is. All of it. So you don't have to worry about "Oh, where does this service put it?" and you have to figure out which region you want, and a couple of other things.
But also, when you go the route to a SaaS offering, then you have to get people along with you which are higher up in the organization, which in a large company is sometimes a great challenge.
Okay, so you're saying that the company itself, the leadership prefers for you to run everything yourselves, versus using managed services, or software as a service?
Yeah. Maybe not, but the easy route is to host it yourself. In practice, that's the easy route.
Okay.
Break : [35:47]
So I know that via your message, because when we talked on Slack there were quite a few things we've exchanged… You told me that your goal in life is to make things easier for people. Tell me a little bit more about that. We mentioned Kubernetes, we mentioned workshops, we mentioned self-hosted services… How does making things easier for people work out in practice, with all these tools and technologies? And the people, let's not forget them.
So in my study, I studied Informatica, which is computer science in America, and with a specialty in human-centered design. So human-centered design is about user experience design and make it easy for the user. And I got thrown into infrastructure side of things, because I was very interested in that. So I applied some principles into the infrastructure side of things.
So I think that getting started must be fast, you have to just clone a repository and the readme should guide you as fast as possible to get started and to get to your goal. I would say it should be possible to contribute to a project on your first day of work.
But then you got into the story of "Yeah, some people want to use an IntelliJ IDE, some people want a VS Code IDE, and another one uses Vim, for example." And then the configuration gets fragmented. So it's quite a challenge to align all those.
For example, your Prettier formatter should be usable in all circumstances, but it must be possible in the repository to add your own workflow, to apply your own workflow.
Okay, so how does this translate to your company and the team that you're a part of? First of all, is there like a single repository that they clone, and that's how they get started? Are there multiple repositories? What is the starting point?
[40:13] We started with multiple repositories, but we're now migrating to a monorepo. So code sharing between the applications is easy.
So the readme is the first step to read, and that implies fetching credentials - a way to get credentials.
Where do they get credentials from? That's an interesting one… Because there's so many answers to that. Everyone does it differently.
Yeah, we have a system in the company, single sign-on, so that's how it's being set up. And then you have to create some tokens for yourself, and then you can use that locally.
So the tokens - are the tokens to get credentials, or are the tokens the credentials that users use?
The latter. The tokens are the credentials you use in your local set up.
But what about, for example, the database credentials? Or the Kubernetes ones, if you don't use the database. I think for GitLab it's easy, because you log in with your company username. Is it like open ID or open ID connect, something like that?
Something like that, yeah.
Okay.
OAuth.
OAuth, sure. What I'm wondering - is the application, the credentials which need to… Like, do they stand everything up locally, and then the credentials get just generated? How does that look?
For now, you have to fetch them from external. But in the end, I want to be able to create a system where you just need one secret for your personal, and then that secret, again, can grant you to the database and the other systems. That's the goal. We're not there yet.
So when it comes to storing secrets, where do you store secrets for the apps?
Now some just need to be entered in the application, like the .env file, for example. So it's just git ignored. It's something in Git, stored.
Okay. We do something very similar for our application. Our source of truth for secrets at Changelog is still LastPass, but we want to migrate to Vault. So that's what we're thinking. 1Password, that's something which – I used LastPass for many years, and it was the easiest thing. So let's just put them there, let's just create a shared folder, and that's how we're going to share the secrets between – we're just a small team. That has its own challenges. It is a service, so –
But you still have to make manual action when you install your project.
Yes. So there's something to run, exactly, to set up. And it basically generates the .env file. So in our case, it's make.env, and then that file gets generated from LastPass. And if you were to delete it, and if you were to re-generate it again, it will just get the latest values from LastPass. That's how that works.
So you want to be able to use Vault.
Yeah.
And are you planning to use the cloud version, the managed version?
That's something which I don't know, to be honest. I'll have some people from HashiCorp in a future episode to talk about this, like "How should we use Vault? What are the options?" Because that's exactly what I don't know. I know it's time to move from our current setup to something better… I mean, we've been talking for a while to improve it. It was never high enough on the list, but I think the time is right for us to have a better source of truth, and I think I would prefer it to be managed. Again, this goes back to the conversation which I had with Kelsey - the database should be managed, everything documented… And I think secrets - we should have a service for that, for sure.
Yeah. Because it's quite a beast to manage it on your own. The impact is quite high if you lose access to some systems.
[44:11] Yeah. And then as you know, you should always have a back-up. That's something that if you had to recreate things, they should be fairly easy to recreate. Again, I don't know how we would encrypt that, because we need to somehow encrypt it… That's something to think about, for sure. With a GPG, or…
Yeah. For now, we also use, of course, TLS certificates. And we are not using a Let's Encrypt system like cert-manager because the certificates are just with our own CI from the company. So the way it was fixed previously was they were using GitLab CI variables. Previously, they were using encrypted secrets in Git, and with SOPS, the Mozilla tool. But I came across the Sealed Secrets operator from Bitnami. You heard about it…
Yes.
So we're now storing the TLS certificates like a Sealed Secret in Git. So you are able to distribute your secrets safely.
Yeah, I think that's an interesting idea. I can see the appeal of that. The problem with that approach is that you don't know where your secrets are, like all the places where your secrets are, because they're now being spread. As long as there's like a Git clone of your repo, there is a copy of your secrets there. So I think storing secrets in Git - it has some applications, some benefits, but I'm on the fence. I'm not sure if it's the best idea. I tried it myself, and in certain contexts, with certain teams, we even do that. But I think I would prefer to have a single source of truth which is managed, where all the secrets are stored, and then we pull from that. And I don't think I would give the actual secrets, if possible. I would give something that can easily be rotated, and something that is rotated, so that when you want to expire them, or basically refresh all your secrets, it's easy to do so, and then everyone can get them without having to reclone, reconfigure things.
So I see the appeal of setting connections to your source of truth where the secrets are, and having a way of refreshing everyone's view. The ones that still have access, by the way, to the secrets, because I think that's the whole idea. So you're focusing on the connections, rather than absolutes, like absolute files, or things like that. Ephemeral things which can get updated on the fly.
Yeah. It’s also possible to reference them in Kubernetes for example. It references a secret name in your code. So your secret is not stored locally, but when you deploy on your Kubernetes cluster in the cloud, using for example DevSpace, it references that secret and it can use that, but you don't have it stored in your Git repository.
Interesting. So hang on… Are you suggesting to develop in Kubernetes? Because that's crazy interesting.
Yeah, yeah.
Okay, tell me more about that.
So my mantra was "Getting started must be fast." A lot of time is spent when developing locally to set up your system. So you want to take all that work to the cloud. We have a Kubernetes cluster especially for development. Then you run DevSpace. The only tool you need is DevSpace, which is DevSpace.sh. That tool is able to spin up your infrastructure Helm chart for your application, and then synchronize your local files to the cluster. And when you make a file change, it recompiles and then you can use the power of the cloud to develop for your own environment. So it's kind of a remote development environment.
Interesting. What's the latency like?
It's quite fast, yeah. I don't have numbers on that, but it ships them, it ships the changes, and then deploys them; it mirrors them, and vice-versa also. I used it a lot last week, for example, when running Prettier on the frontend code, and it works great.
[48:27] How does this compare to GitHub Codespaces, or Gitpod? Is it something similar, or…?
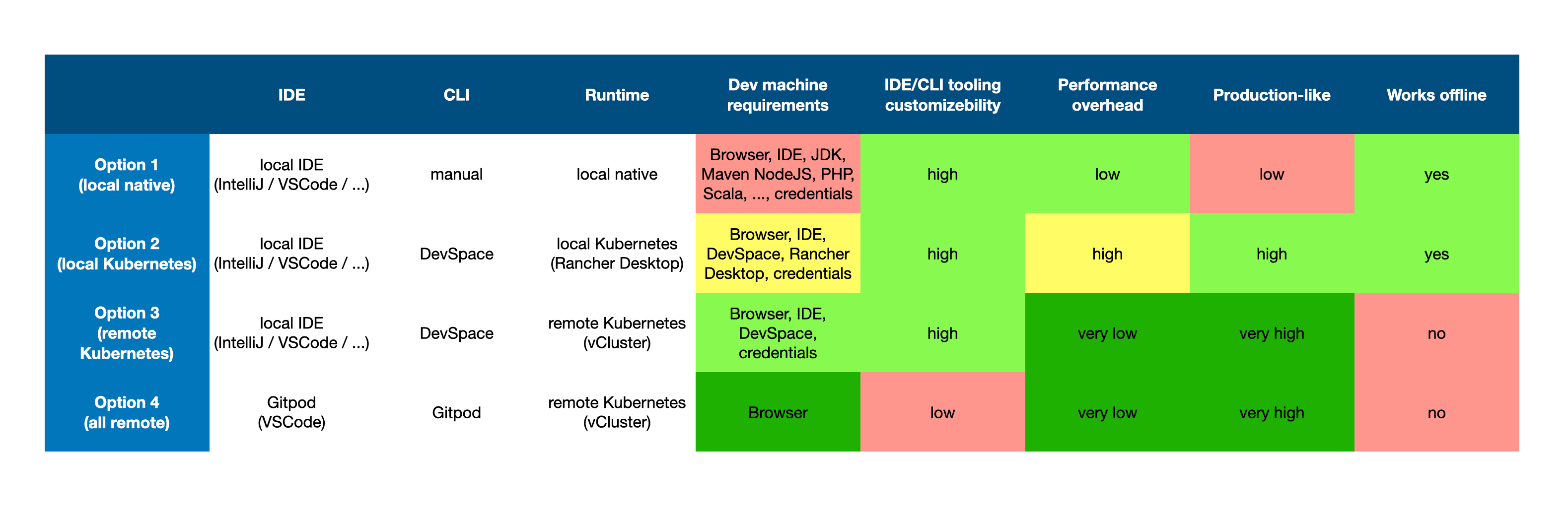
So I shared with you that matrix for environments…
Yes.
…and it's the third option.
So for our listeners, let's go through what this is. We will put it in the show notes, for sure. We have four options. Option one, local native. Option two, local Kubernetes. Option three, the one that you're talking about, Maikel, is remote Kubernetes, and option four is all remote. So Gitpod, GitHub Codespaces would be all remote, option four.
Yeah.
Option three is a local IDE. It's using DevSpace for the CLI, and there's a remote Kubernetes, VCluster. Nice. So are you using VCluster to provision Kubernetes clusters for every single developer? Is that how that works?
For now, I'm only [unintelligible 00:49:18.16] But for the future, that's the plan, to use VCluster. So everybody has their own cluster for toying around.
And all of this runs in a single, big development cluster. Not big, as much as like an actual Kubernetes cluster. But the users - they get virtual clusters.
Yeah.
Okay. And they use local IDE and DevSpace synchronizes the files. Okay, that's interesting.
So the difference between option three and four is that your files are in your local IDE, and not in remote. Because like I said, people want to have a custom environment on the laptop, using Vim or another editor… So that's the benefit of using option three.
Okay. And does it work on an iPad? Can you use the DevSpac CLI on an iPad?
I didn't try it… But yeah, I wonder.
Okay, I wonder too, because I know people that use iPads for development. They're great battery-wise, very portable, and the code runs elsewhere. So Gitpod - I think there's something like that for Gitpod.
Yeah. Option four definitely runs on an iPad. Because what's the benefit of using option three on an iPad if you also need an IDE for it? I don't think that would work.
Unless there's a good IDE for iPads, which I don't know.
Yeah, indeed.
Alright. You're right, I think in that case it's all remote. Everything runs remote, even the IDE. Okay. So how long have you been using this option three, where you use DevSpace to synchronize files, so this remote Kubernetes where everything runs - how long have you been using this?
I've been playing around with it for a year now. Actually, it came from – at the previous company I worked for we were using Docker Compose for local development. So all projects were set up using Docker. With Docker Compose all your files changes are synchronized, but the con of that is that in the end, for example, you have an NGINX configuration in front of your project, and with Docker Compose – and you would set it up in the Helm charts. But when using Docker Compose you're not having an actual representation of your production environment. So DevSpace is like the Docker Compose in your Kubernetes story.
[52:02] Okay. I haven't tried DevSpace out, but this conversation makes me want to go and check it out and see how well it works. Did you blog about this, or do you have more details about how you use it, and what works well, and your setup?
I'm going to blog about it. I don't yet have a blog about it.
Okay. I think that will be good to read. So do others within your company use the same approach, or do they use something else?
Most of my current colleagues use option one. They have just a local IDE with local tools. There's a lot of time going into setting up all that.
I see. Yeah, the machine installing all the dependencies, everything for development. I can see that being a huge time-sink for many, for sure.
And also, the differences between all those laptops - it's a potential risk.
Yeah. Okay. Have you seen any issues because of those differences?
In my previous company we had some differences between the Node dependencies, yeah.
Interesting. Okay. But if the Node dependencies were configured correctly, would it still be a problem, do you think?
[unintelligible 00:53:10.09]
Yeah.
I have friends who work for other companies who also use just option one, and they had issues. They couldn't reproduce an error which happened in production, and by the time [unintelligible 00:53:30.06] they found it was an environment change.
So the version that they were running of the runtime, or – yeah, okay.
Yeah.
I remember we had one of those, and it was around PostgreSQL. I think Jerod was using version 14 or 13, and I was using version (I don't know) 9 or 10. Production was version 12, so everything was all over the place. And the CI upgraded automatically, because we were unpinning it, and when that happened, a bunch of stuff started failing, because the way the indexes were being built differed, and then things were out of order… So there was like a couple of issues. And finding those things always takes a long time, and you think "If I only had these pinned locally in my CI and in production, I wouldn't see these things." But it only happened once.
But they were major versions.
They were major versions, yes. Huge differences, yeah. Node.js I think it's a bit like that. I forget what version it's currently running at, but I know some people use 16, or 12, or… They're all over the place, so you don't know what people end up using… And it works, so… You know.
Yeah, yeah.
As we are approaching the end of our conversation, I'm wondering what are the key takeaways that we would like our listeners to have?
I would say that it's very important to align with your team, and your setup with your team, so that everyone has the same base they are building upon. So have a good CI system set up, use proper formatting, and go about how you use Git, for example, in your team.
Also, I've learned from another podcast a while back - oh, from GitLab - that if you have a discussion over Slack or something, with someone, just don't hesitate to create a call, to create a meeting to discuss it fast. So don't have the whole morning chatting away, while you also could have a quick talk with each other.
So you mean typed when you talk via Slack messages, or GitLab comments in this case, and pull requests - I imagine it works the same way…
Yeah, yeah.
Versus just calling them and hashing it out much quicker than you would have with that ping-pong. Commenting ping-pong, we all know how fun that is. And then three hours later, "Why didn't you call me?"
Yeah, indeed.
Okay. Alright, Maikel… Well, thank you very much for joining me today. There's a couple of tools which I definitely want to check out. There's a few blog posts from you, or at least a diagram that I'm looking forward to you sharing, and also trying to understand myself especially how GitLab can upgrade itself without any downtime, and Argo CD as well. I've found that really interesting… And I'm very curious to see what happens in, let's say, six months from now, for you, for your team; how do they upgrade, or move towards this new world that you're imagining… And you see people using remote Kubernetes and having setups which are closer to production; that's something which I'm a big fan of.
I'm wondering how I can use those tools myself to change things slightly, how I do things. Because Vim - yeah, "From my cold, dead hands". I think that's the expression that I'm looking for… Vim forever. And how can I use my local code editor with a setup which is remote, and it's as close to production as possible. That's cool.
Yeah. It's going to be a great [unintelligible 00:57:16.02] for all of us, I think.
Thank you for joining me today, Maikel. Until next time.
Our transcripts are open source on GitHub. Improvements are welcome. 💚