In today’s episode we have the pleasure of Audun Fauchald Strand, Principal Software Engineer at NAV.no, Norway’s Labour & Welfare Administration. We will be talking about NAIS.io, the application platform that runs on-prem, as well as on the public cloud.
Imagine hundreds of developers shipping on an average day 300 changes into a system which processes $100,000,000 worth of transactions on a quiet week. If you think this is hard, consider the context: a government institution which must comply with all laws & regulations.
Featuring
Sponsors
Sourcegraph – Transform your code into a queryable database to create customizable visual dashboards in seconds. Sourcegraph recently launched Code Insights — now you can track what really matters to you and your team in your codebase. See how other teams are using this awesome feature at about.sourcegraph.com/code-insights
Raygun – Never miss another mission-critical issue again — Raygun Alerting is now available for Crash Reporting and Real User Monitoring, to make sure you are quickly notified of the errors, crashes, and front-end performance issues that matter most to you and your business. Set thresholds for your alert based on an increase in error count, a spike in load time, or new issues introduced in the latest deployment. Start your free 14-day trial at Raygun.com
Notes & Links
- NAIS.io - Application platform and DevEx toolbox for teams digitalizing NAV.no
- 🗂 docs.nais.io - references, step-by-step guides & some good YAML
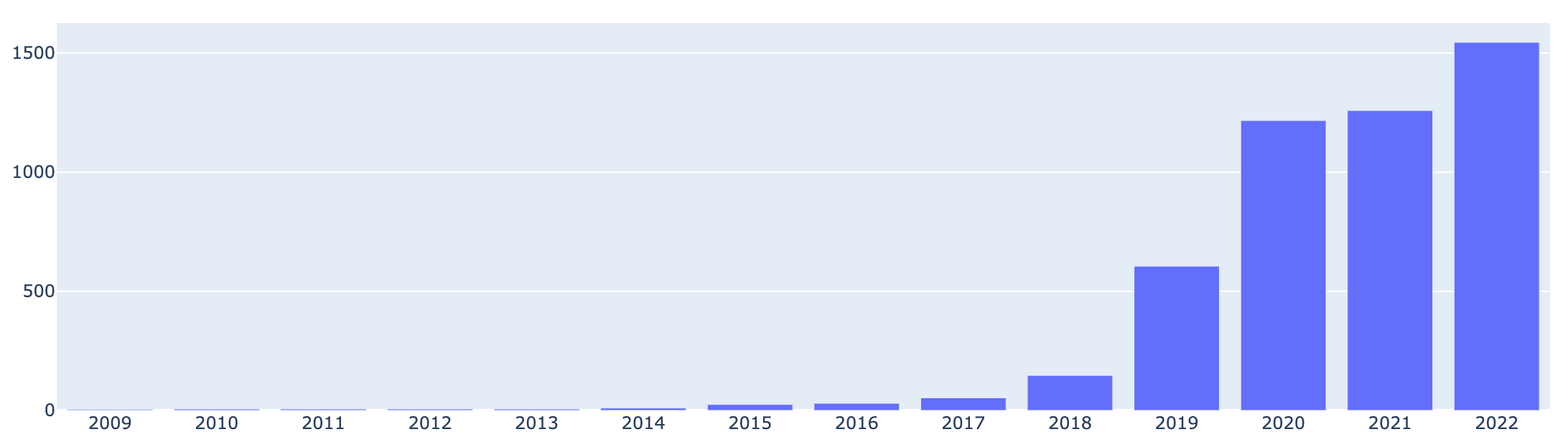
- 📊 NAV.no deployment stats, 2009 - 2022
- 🗺 NAV Teknisk retning (technical direction)
- Being NAIS at a distance - How we work in a hybrid world
- Do we need an internal technology platform? - The case for platforms at NAV
- Changing Service Mesh - How we swapped Istio with Linkerd with hardly any downtime
- NAIS @ GitHub
- 📃 How to Optimize for Fast Flow Using Alignment and Autonomy
- 🐦 Do you know what’s cool? Keeping your #kubernetes clusters secure.

Chapters
| Chapter Number | Chapter Start Time | Chapter Title | Chapter Duration |
| 1 | 00:00 | Welcome | 01:03 |
| 2 | 01:03 | Sponsor: Sourcegraph | 03:04 |
| 3 | 04:07 | Intro | 04:20 |
| 4 | 08:27 | NAV vs NAIS | 01:43 |
| 5 | 10:10 | What's good about having NAIS? | 04:03 |
| 6 | 14:13 | Why K8s? | 02:04 |
| 7 | 16:17 | Kollide, Unleash, how close are you? | 01:33 |
| 8 | 17:50 | Favorite NAIS tool | 02:38 |
| 9 | 20:29 | Kyverno | 03:19 |
| 10 | 23:48 | Sponsor: Raygun | 01:58 |
| 11 | 25:46 | How do you secure the data? | 01:17 |
| 12 | 27:02 | Cilium and eBPF? | 03:48 |
| 13 | 30:51 | How long has Audun been in tech? | 03:08 |
| 14 | 33:59 | Challenges from Covid | 06:33 |
| 15 | 40:31 | Success story | 02:26 |
| 16 | 42:58 | How big is NAIS? | 02:53 |
| 17 | 45:51 | GCP in practice | 01:12 |
| 18 | 47:03 | Missing from GCP | 02:08 |
| 19 | 49:11 | Migrating the older services | 02:22 |
| 20 | 51:33 | A good day for Audun | 02:23 |
| 21 | 53:56 | The SLSA model | 01:09 |
| 22 | 55:05 | Anything bigger? | 01:16 |
| 23 | 56:21 | Inspiration for NAV | 02:00 |
| 24 | 58:21 | Go listen to this talk | 01:16 |
| 25 | 59:37 | Wrap up | 01:31 |
| 26 | 1:01:08 | Outro | 00:46 |
Transcript
Play the audio to listen along while you enjoy the transcript. 🎧
I’ve heard about NAIS.io, an application infrastructure service built on Kubernetes from Vincent Ambo, our guest from episode 37. This application platform was built specifically to increase the rate of shipping code from a few times a week to hundreds of times each day. The surprising part is that this application platform is running Norway’s welfare payments. So we are talking about many billions of dollars worth of transactions every year. It’s huge. One of the masterminds behind it is joining us today to talk about it. Audun, welcome to Ship It.
Hi, thank you. Thanks for having me.
So who is the other mastermind behind this application platform? I know there’s two of you.
Well, actually, the application platform is – there’s a team, I think. So I think there’s two of us working as principal engineers at NAV, but the application platform is built by a team. I was a part of that team when I started, and then I worked there for two or three years full-time, and now I’m more like everywhere in the company, because there’s so much things to do, and the application platform work so well, we need to fix all the other stuff.
But there’s like you, and this other person… I’ve even seen like your talks that talk about that; you’re most like the public figures when it comes to this right? And the ones that have a lot to do with it. So who is your partner in crime?
Oh yeah, his name is Truls Jørgensen. We had this big change of strategy in our company, NAV, five years ago, where we went from fully outsource to try to in-source and hire on developers. And Truls was the first one, and I was the sixth or seventh one, I think… And now we are 300 or 400, it depends a bit on what you count as a developer. But if you say product developers, I think we’re up to 400 people.
That is a lot of people to be working on a lot of applications and a lot of code, and manage a lot of complexity. So before we started recording, you’ve described the two of you as Walldorf and Statler, the two angry old man from the Muppet Show that constantly complain about everything. What is the most recent thing that you complained about?
Well, today we had a discussion about GDPR [unintelligible 00:06:47.17] although it’s really important, sometimes it feels like there’s so much – the technology says something, and the lawyer says another thing, and the trick is to kind of balance the two out, and that’s always difficult, because a lot of the time one of the sides kind of says, “Well, everything has to be like I say”, but you have to balance the value of using cloud technology with the risk of privacy.
Yeah. And I’m assuming that running everything in-house is not an option.
Well, we used to have that when we started. The first iteration of NAIS was basically running on-prem. We have a strategy where we go quite slowly, both going from our old legacy systems, to NAIS, the Kubernetes platform, but at the same time also going quite slowly from on-prem to cloud. We don’t want to do lift and shift, we want to modernize our applications and to get the full value, both of using Kubernetes, but also using the cloud, because we don’t see – well, there’s not that much value to gain from just moving old stuff to new infrastructure. You need to modernize the applications and make better applications. We always say, none of the users of NAV care about our application platform. We’re not here to make better application platforms, we’re here to make better services. And better services come from better applications. And then the platform can of course help with that, but that’s not why NAV is NAV, to make application platforms… Although that would have been quite cool, actually… [laughs]
[00:08:25.25] Hm… So what is the difference between NAV and NAIS.io?
Well, NAV is the biggest governmental agency in Norway. As you mentioned, we pay out about a third of the federal budget in Norway. We have everything from age-related pensions, to parental benefits, to sickness benefits, and we also have the responsibility of helping people get back into work and kind of have the whole working system working as good as possible. So that’s NAV. And we used to be many different organizations, and then we had a big merger in 2006, where the politicians thought that if they’d just put all these different organizations into one organization, then everybody will start to cooperate, and data will flow between the different systems, and everything. It turns out that wasn’t as easy as just putting them into the same organization; there’s still monolithic software causing problems. Three monoliths are necessarily better than one monolith. So we still have that.
And so that’s NAV… And NAIS is basically our open source platform that we started building in 2017, which was kind of a kickstart of the whole in-sourcing process, where we thought that we should – because when we go from none, or almost none developers and we want to hire a lot, we needed to make it visible and clear that being a developer in our company is good. It’s possible to work with good technology, and have development speed, and have all the good things, so we kind of… We used it as a branding exercise as well as a technology platform to help us get developers in.
So five years – well, 2016; six years almost now, it will be since NAIS has been around… What are the benefits that you’ve seen in this time of having NAIS?
I think there’s multiple. Maybe the clearest one is what you said - before, we used to deploy at nighttime, and have manual testing periods, and so deployments was maybe something that happened… Well in 2005 or 2006 it was four times a year, and then it grew very slowly. But it was always coordinated, always the big releases. But what NAIS did was make it possible for the teams to handle this whole process themselves, and they didn’t have to do – there was no technical reason from the platform or infrastructure side that made it necessary for them to coordinate with anyone when they wanted to deploy. Of course, there might be dependencies between applications, but that’s a different thing to fix. So now we’re up to 1,500 releases a week, and we’ve been quite steady on that for a few years, I think. We have about 1,300-1,400 applications, so on average, there’s one deployment per application per week. But we have some data showing that most of deploys come from a smaller part of the applications. There’s a few application that change a lot, and some that hardly change at all. I think that’s a logical consequence of doing micro services, because some is more support, and some [unintelligible 00:11:37.07]
But the other side which has taken me a bit by surprise is the fact that we have this platform, which has very – you can say it has quite tight entry conditions… It’s only Docker containers, but we say you have to be stateless so we can deploy, because Kubernetes can move your application.
[00:12:00.25] And we do log collection this way, and metrics this way, and alerts this way. It’s quite unifying. We tried to do what Spotify called kind of making a golden path, to make it easy to do it the right way. And that works almost too well. Almost all the teams do almost everything the same way. So although we say there’s no real guardrails on programming language, for instance, or stuff like that, people copy from each other and learn from each other, so it’s quite unified how we do development. And we have a limited number of external services that are available to NAIS; we have Postgres and Kafka. And that means that Postgres and Kafka are basically the two most important architectural [unintelligible 00:12:47.12] That drives the technology development in a quite clear direction, I would say.
So we have a quite consistent architecture, and I thought that almost the opposite would happen, because you can do whatever programming language you want. The organization is so big, and there’s so many different problems to solve, I thought the diversity would almost be bigger. But it turns out it’s quite unified, our architecture. And I think that’s a good thing, although I’m always a bit scared of what that means. I don’t want us to relax either, I want us to be able to see when there’s new, interesting stuff happening that we need to use.
Yeah. Okay. So going back to how many deploys you do, there is data.nav.nl (and I’ll put a link in the show notes) that shows how these deploys have changed over the years. And I think it starts in 2009. So there’s a lot of data, 13 years’ worth of data, to see how many services you had, how often you deploy… That is so insightful. I was surprised that this data is public, by the way. This is amazing, for anyone to see just you know how big this platform is in terms of applications, in terms of deploys… That was really interesting. So I have to ask this - why Kubernetes? What drove you to Kubernetes?
Well, I think there’s two answers to this. When we look back on it, I think we want to use open source technology; we want to have – although it’s not important for us to use many clouds at the same time. We think that that probably costs more than it gives. But to use open source APIs as the main boundary between the application and the platform makes it easy to move and makes a better distinction between the application and the platform.
When I started to make applications platforms - I think it’s 2014 - Mesos was the thing. So we used Mesos and Marathon. I can’t even remember all the things we used, but it was kind of a completely different platform. And then we had the problems of – they weren’t really cooperating well. There was just a bunch of open source projects, and we had to spend a lot of time just updating everything and figuring out how to use them. And then, at that time, I think 0.8 or something Kubernetes was released, and someone in our team knew someone from Google and said, “Well, this is good.” So we looked at it, and it did all the things good that the Mesos universe did badly. Everything was one big package. You just had to figure out how this worked, and then it solved everything. So after that, it feels like Kubernetes basically won that space. And then all the cloud vendors came running, or offered that as a service as well.
[00:15:56.28] So I think the main – there doesn’t seem to be that many alternatives that are… As open source, you could go all the way to some kind of serverless thing, and then be more cloud-dependent, but I’m not sure I see that as a good move, at least not for organizations of our size.
Yeah, yeah. That’s right. Okay. So I’m looking at NAIS.io and I see a lot of great components there. Grafana, InfluxDB, Linkerd… A few that I do not recognize. There’s Kollide, OSquery, Unleash… How close are you to those components?
Well, they’re different things. Unleash is a feature toggle system. It was created initially in the company I worked for before NAV, a company called FINN, which is basically the Norwegian eBay, and it’s now a big open source project. It’s one of the two big players in the feature toggle system. So a lot of our teams need feature toggles to be able to have the deployment speed.
And then Kollide and OSquery are part of a feature we developed quite late in NAIS, where it’s more about handling controlling the laptops we use and how the laptops connect to our clusters. So we call that NAIS device, and Kollide is basically the it’s an hosted service that glues together OSquery, which is an agent that runs on the laptop and checks if everything is up to date and the laptop is sound, and handles the management of that, and how to communicate with users, telling them “Well, you need to update macOS”, or “You need to do a Chrome upgrade.” And then we build some gateways ourselves, kind of just the last bit, so we can control exactly how our laptops access our production environments.
Hmm, interesting. So which of these components do you use most often? Because there’s quite a few, and it’s not an exhaustive list. Is there something that you use on a daily basis? I’m assuming Kollide and OSquery, because that must be running on your laptop… But what else that is more like your hands-on, you’re much more aware that is there? Because I think Kollide and OSquery - you install them, they provide connectivity, and they just kind of get out of the way.
I would say my favorite tool of all the tools of NAIS is probably Grafana.
Really? Okay…
I used to be a backend developer, making applications, and just the sheer joy, and all the interesting things you get out of looking into what happens in production, and making graphs of everything, and trying to figure out why stuff is happening, and what does this mean when this goes up and this goes down.
Whenever I – at least when I was an application developer, whenever I didn’t know what to do, I could always find something to measure and try to get more insight into what’s actually happening in our application. Interestingly, we kind of - as a platform at least, or as a company, we moved a bit away, or we extended how we do that. Now we’re also more into getting the getting the data out of the databases as well, trying to think of that data as a product, and not just do the real-time monitoring, but also try to do more aggregated monitoring, or reports even. It’s kind of a sister platform of NAIS, our data platform called [unintelligible 00:19:23.15] which we tried to do that with… So it helped the teams to be even more conscious of all the data they have, and what they can learn from looking at the data.
Did you say Nada?
Yeah.
Like nothing? That means nothing. Okay… That’s an interesting name. [laughs]
The reason for that name - at least my version of the history of the reason for that name - is that we didn’t want the platform to own the data. Because traditionally, the data warehouse is a central team, and the data warehouse team owns both the platform and the data. But we wanted to do the same thing with NAIS, because NAIS doesn’t own the applications running on them, and we wanted a data platform that’s a platform; and the teams should own the data. The application teams should own the data. So basically, the Nada name is – also, it’s NAV Data, of course… But we wanted it to be clear that the platform is a platform, and the teams own the data.
[00:20:25.02] Okay. That’s a good one. So I know that’s you run other services, other components, as you call them, which are not listed on the NAIS.io website. There is a tweet which I noticed three hours ago, very recent… “Do you know what’s cool? Keeping your Kubernetes cluster secure. At NAV.no we use Kyverno to ensure no pod runs unchecked. And the question is, what is your best tip securing Kubernetes clusters? We want to hear.” I’ll put a link in the tweet. I mean, when this comes out, if you want to answer, it will be a few weeks later, but still, it will be around… What do you think about Kyverno, and how do you think about securing things? …because this must be a very important topic, considering the data and the transactions, and what is happening in your applications.
I would say, answering that question from more of a top-down perspective, first, I think the main thing with security… When you’re making an application platform and you want to help the team secure your applications, it’s really important to understand the needs of the developers, to make sure that any security feature you add is usable. Because in my experience, there’s been loads of security people that are so into security that they make this principle that is almost impossible to adhere to.
So at sometime in the process there will be something where the developer has to choose “Should I follow the principle, or should I deliver on time?” Most of the time, they will deliver on time. So you have to make the security things easy to use. In my experience, it’s more important that it’s usable, than it’s 100% secure. Because if you make all the principles and all the things that are needed to make it 100% secure, and the team doesn’t follow that because it’s impossible, then you have [unintelligible 00:22:13.19] when the people responsible for security think everything is okay, and the people in the team doesn’t want to tell the security team what they haven’t done.
For instance, we used service mesh before we used to have these network [unintelligible 00:22:30.10] in our on-prem architecture, where we had two [unintelligible 00:22:33.02] one for the internal applications and one for the external applications. And basically, perimeter safety. So if you came inside the firewall, you had access to everything. But instead, we used the service mesh and zero trust principles to basically put a small firewall around every application, and make it the team’s responsibility of configuring this firewall.
So the teams - and it’s a part of the configuration of the application, what applications can talk to you and what applications do you need to talk to. So instead of a central firewall, and some kind of person in the middle that always has too much to do, you make it a team’s responsibility to configure this, and then everything works better.
What about the data? How do you secure the stateful data that is persisted at REST, PostgreSQL for example, or anything else that you use for persistence? Flat files maybe, you have those as well… I don’t know.
Well, there isn’t one way we’re doing it, because we’re so big, and we have a gazillion different requirements. But for Postgres, we use – NAIS now runs on GCP. So we basically use the managed GCP service for Postgres. And we considered the bring-your-own-key architecture, but right now, it feels like that increases the risk of us losing the key more, and thus losing the data, than actually losing the data. So although that’s something we consistently rethink, right now we mostly use the normal features of GCP, and then have some extra backup things, because we want to ,ake sure we have everything running inside Norway as well, or have the data accessible inside Norway.
Right. Okay, that makes sense. Do you make use of anything like eBPF to secure or at least have visibility all the way down into system calls, bot just like network traffic?
I know the plan is for us to – I’m not entirely sure right now, but our plan is to go to Cilium as a service mesh, from Linkerd. We were first on Istio, and then Istio felt like it was a bit too much for our needs, and then we went to Linkerd, and now we’re looking at Cilium, which is eBPF. But that’s how we approached that problem.
That’s interesting. It’s great that using a platform that promotes open source, and has a very rich ecosystem - it allows you without too much investment to be able to go from one provider to another, from one solution to another, which by the way, there’s the open source versions software you can try out, there’s paid-for versions… So it’s nice that you can switch between these things. How did that work out for you in practice? How did it work out for you going from Istio to Linkerd? Was that, would you say, a seamless migration or transition, or were there complications that you couldn’t foresee?
[00:28:15.26] First of all, I just wanted to say we blogged about that; there’s a blog which I presume you can put in the show notes after… I wasn’t the main part of that process, but as far as I can tell, it wasn’t that difficult. It took some time, because you had to change something in all the applications… But we have a really good dev environment that we can do these things in. And as far as I remember, it was something you did in approximately one day, moving all the several hundred applications from one to another… But yeah.
That’s impressive.
And I think, more or less going all the way back to the question you had about why Kubernetes - one of the main reasons Kubernetes is so good is you have all this… You have this API which is incredibly well thought through. And they made this in 2015 or something, and it still kind of makes sense as an API, even though they changed a lot of the things behind it, and they made it extensible. But you have this API that’s so good, and it matches so well with what an application and an infrastructure does. So it makes it possible to create tools like a service mesh, and it makes it possible to change implementations even of the service mesh, or the implementation of the Docker runtime, or container runtime or whatever, with almost no disruptions to the actual uses of the platform.
I remember in the old days most of these things were almost impossible, and it took weeks and months to plan and do.
Yeah, that’s right. Yeah, I remember the pain. It was like hard. Like, you wouldn’t even think. Like “No, no, too expensive. Let’s just not do that.” And that’s how a lot of the great ideas would end up, because the implementation was just not worth it.
And now you can even buy it hosted. So most of the stuff you don’t even have to think about, like updating, or changing nodes, or increasing the capacity… It’s not even clicking a button. [laughs]
Yeah, that’s amazing. I love that part, too. So if anyone is curious to learn more about this platform, there’s some great content on docs.nais.io. There is references with diagrams, there’s step-by-step guides… There’s even 300 lines of YAML for the NAIS application example. There is a lot of Kubernetes YAML, best practices, and other content worth reading. I enjoyed digging into Deploy section. I was really surprised, there’s like so much good stuff there. So have a look if you’re curious. We’ll add a link in the show notes, but it’s docs.nais.io.
So before we change subjects, there’s something that I wanted to ask you since the beginning… I know that you’ve been in tech for quite a few decades. So how long has it been that you’ve been in tech? Do you remember when you started?
I left university in 2003, I think… So I’ve basically been working – I started as a consultant, and then I realized consultancy isn’t what I want to do; I want to be part of the company that owns the product. So - well, it’s almost 20 years… 20, yeah.
Okay. So in a few sentences, as a very brief summary, what were the last ten years in tech? What were your last ten years in tech? There was the Kubernetes part of it, but what else happened that brought you to where you are today, a principal engineer at NAV?
Well, I used to be a Java developer. I had really identified as a Java developer… And a bit by chance, I got the role as a lead developer for the infrastructure and operations team at one company, and then I realized I could use all the experience I had as a frustrated backend developer to make applications platforms. And basically, I’ve been doing a lot of that since then, just figuring out, doing all the things I learned, or I couldn’t do easily before, trying to make that possible.
[00:32:07.23] And then for last few years, it’s been more and more about making everything fit together, not just the application platform, but making the management understand what’s important, and why making software is completely different from doing other things that the Norwegian government doesn’t finance, for instance.
Yeah, yeah, that’s right. So if you were to write an application today, would you still pick Java?
No, I would probably do Kotlin. I don’t program as much as I want to anymore, but mostly I program in Kotlin and Golang. And I think programming in Kotlin is more fun, and I might think that and programming in Golang is a bit frustrating, but it feels like it will last longer, and be stable for longer…
I see.
So if it’s my decision, I would probably still go for Kotlin, because that’s more fun, and you can you can feel more clever when you write Kotlin than when you write Golang.
Okay, okay, that’s a good one. And if you were to choose where to run this application, what would your choice be?
At NAIS? Well, I mostly write things for NAV, and then the question is similar, but I’ve always thought – I mostly worked at big companies, with hundreds of developers, and I have this lingering thing in my head where maybe all the things I think is good for those companies might not be good for small companies. So I’d probably try to figure out some other ways of doing more serverless, or more higher-level abstractions from some of the cloud vendors, for instance, just to make sure… I have this suspicion that at some point in the future that’s going to be even easier, even for the big organizations, but I’m not necessarily sure we’re there yet. But it’s difficult to say.
Okay, so the last few years have been really challenging for governments around the world, especially welfare systems around the world… And obviously, we’re talking about COVID, about the pandemic… It’s been really, really tough. So what challenges did COVID bring for your platform for NAIS?
Well, the very first challenge was – I think this was the 10th or 11th of March in 2020.
That’s very specific… Okay, this is gonna be good. [laughs] Alright…
Because that’s when basically the prime minister of Norway said, “Well, everybody has to be stay-at-home”, unless you have a really good reason to; basically, if you’re a fireman or work at the hospital, or something, you have to work from home. Before that, most people went to the office on most days, and all the tech and all the infrastructure was basically built around that. So luckily, we had just enough – we had the necessary things to be able to start working from home, but it was kind of a challenge and we had to relearn how to communicate and how to work as a team, basically. And I think that was interesting. It worked quite well when everybody was at home, and I think it’s an even more interesting challenge now when some people want to stay home, and some people want to go to the office, because it’s much more difficult to solve this challenge when the teams are more hybrid.
But that wasn’t the most difficult thing that happened during the pandemic… Because of this order from the Prime Minister, we had a lot of – and I think the English word here is “furloughed.” We had a lot of workers in Norway - not at NAV, but in Norway, furloughed. And according to the rules of Norway, then you’re supposed to get the benefit. I think normally there’s around 1,000 of those applications a day, and now we have like several hundred thousand furloughed people in a week or so.
[00:35:57.13] We were still early in our transformation, and so most of those applications would normally be handled by manual caseworkers. So our estimates was this is going to take a year, for the current systems to handle all of these applications before everybody gets their money. And people needed money.
So the government in Norway tried to make some alternative ways of handling this. So they had a list of 12 different things, I think, and me, and the team, and Truls, and others started working on one of them, where wanted to kind of have a… At the same time, we wanted to make the laws describing this benefit as basically an advance of the normal unemployment benefit. So we had to make the law, and then we had to make a system that implemented that law. And we had to do it really quickly.
I still remember we had stand-up meetings at eight o’clock in the morning, four o’clock in the afternoon, and 10 o’clock at night. Every day for two weeks or something, where we tried to figure out what we could put in the law, because that was limited by what is marked within the law, and what we could implement. So we have to balance kind of what’s possible to implement in a week or so, and what’s necessary to put in the law ro reduce the risk of people misusing this opportunity.
That’s amazing. And this is a country we’re talking about. This is not like a big tech company. This is like – you’re dealing with the benefits of a whole country, right? Like, that’s like your responsibility. Wow, that is big.
So the law was ready on a Thursday, I think, and then we managed to build the system in basically three days. And I’m really proud to say we built that system using pair programming, and we had the user testing late Sunday night… And then we went live on – I can’t remember if it was the Monday or the Tuesday. And then we had a gradual rollout, using Unleash, actually, so we could make sure that the system kind of worked well. We had the increased pressure, and then in a week we had paid out one billion NOK. A week from when the law was ready to when we had a billion NOK paid out.
Okay. That was a good system. Why did you write it in, by any chance? Was it Kotlin?
This was Kotlin.
Really?
Kotlin running on NAIS and a Postgres database.
Wow…
But we actually – it was a lot of reuse. We had some strange components; we had the calculator that people used to figure out what they could get in a benefit if they needed to. But that calculator kind of had the functionality we needed to get the data, the data to calculate what people should get in these new benefits.
So basically, you used the calculator as an API. So we kind of grabbed things from everywhere, and the payment system had this old file-based interface that we used… So some of the integrations was like totally modern, with Kafka and asynchronous, and another one was writing files to disk, and a Bash script moving that file to another desk…
That’s crazy.
…and then the payment system picking up the file and putting it into making payments. So it was everything. We took whatever we could find, basically.
Lots of respect to the people that build that, because as cobbled together as it was, it worked, right? And we’re talking billions like with a big B. 1 billion NOK I’m pretty sure is at least as much as like $1 billion.
No, I think it’s a 10th. Yeah, I think $1 is 10 NOK. But still, it’s loads of money in Norway.
Right. So just 100 million, right? Like, in a week; just $100 million. That’s okay. Like, some Bash scripts, and some Kotlin, and some Postgres, some Kafka… That’s just amazing. And it all worked. Okay. And how long have you been using that system for?
Well, of course, when we built it, we said, “Well, this isn’t going to last long”, and I think we turned it off a few months ago.
[00:40:09.24] Okay. It served its purpose. It served its purpose. Wow. Okay. Sometimes it’s just like you have to make it work, and that’s all the time that you have. So it’s not like “We’ll ship it next week.” It’s not an option. Especially if like the Prime Minister says, “Okay, a week from now those payments will start going out.” You have to deliver. Wow, that’s amazing. Do you imagine that being a success story, if you didn’t have the platform that you had at the time? Can you imagine like making it work without it?
Not in that timeframe, and maybe not as secure, because we could probably make something like that to work quickly, but then we’d have to build even more stuff. And in that timeframe, the less you have to build, the better, because you’re bound to make mistakes and cut corners and everything when you have to do things that quickly… So the more things you could use that are hardened, and works, the better. So I think the security part is probably what we got from using the platform.
Hm… How many people were involved in his project in that one week?
I think we were maybe 20 people. I think we had around 10 developers, and lawyers, and everything.
Wow. Okay. That’s amazing.
And we had – this was one of the things I had to make… I think Norway had a 12-point plan, or something, and I’ve implemented a few of them, and then other parts of the government implemented the rest of them.
So today how many developers are working on the platform and using the platform? I think you mentioned 400, roughly?
Well, yeah, we have 400 in-source developers, and then we have a few hundred consultants as well. So I think we’re up to 600-700 product developers at NAV. I think we have 800 seats on GitHub.
Wow… That’s a big org. Okay. And how are they structured? How many teams do you have? Or do you even have teams?
Yeah, we have teams. We have – well, it kinda depends. I think we have about 100 actual teams doing product development, and then we have some management structures, and everything; that’s kind of our teams, but not that kind of teams. And as we got big, we tried to organize even more, so we have what we call product areas, where we kind of divide NAV into – some teams work with the work stuff, and some people work with the health stuff, and some people work with the family benefits. So we need to split NAV up into smaller parts for it to be comprehensible.
Okay, it makes sense. I mean, there’s like a lot of people obviously organizing that, and being aware of what everyone does, and not duplicating efforts, like “I did it this way, and you did it that way. Okay, we have to reconcile” and all that good stuff. I’m wondering just how big is this platform in terms of resources? I’m thinking CPUs, memory… Things like that.
Well, at least our production cluster running in GCP has 50 nodes; it has a total of almost 800 virtual CPUs and 1.6 terabytes of memory.
Wow. That is a big cluster. Okay…
And our architecture is one big cluster instead of multiple small ones. It’s kind of a religious question, I think.
How are you finding that configuration, having one big cluster versus a couple of smaller ones?
Well, of course, we do divide it; so we have namespaces for each teams, and stuff. The question is probably “Do you want to have more separation?” But I find that it’s easier to manage one cluster, although lately, we’ve been working more on making it possible to make more clusters, because we’re experimenting with providing NAIS clusters to other governmental agencies as well in Norway. And to be able to do that, we have to mean automate, or making it more robust and more automated, the process of making new clusters, because we want different other companies to have their own clusters, and other setups.
[00:44:09.17] One thing which I remember when we were using Kubernetes - again, the scale was very different, but upgrades sometimes wouldn’t go as smoothly. And then what do you do? What do you do if you have a single cluster that you do an in-place upgrade, that doesn’t go out too smoothly? You know, know some component doesn’t interact well with other components… What do you do then? Did you have any such problems in the past?
We had more problems – or maybe not problems… It was more work when it was on-prem. But this, I think, is one of the good things of the managed service. Google does everything for us. So either we decide when to do it manually, which is probably for major upgrades; and for minor upgrades, it’s just a maintenance window, and it kind of happens.
One of the reasons it’s important for us to modernize the applications before we migrate to Kubernetes is these kinds of operations become easier as well… Because if the application is robust enough to be able to handle that, and the node dies, because it’s moved to another node, and then upgrading the cluster is also much easier.
Okay, I see. That makes sense, especially if the applications are stateless, and you can run more than one instance, then, we have reduced capacity for a while. But then if you have NAIS – you’re basically draining a node, the application knows to spin extra instances somewhere else, and that’s okay. It’s like minimal disruption. It’s no different to scale-up, in a way.
No different to a deployment, or whatever. So I think that’s one of the – again, the value for this, for our sake, is better applications. That’s the core value of doing all of this.
So you’ve been using GCP for a few years now… How was it like in practice to use them?
Well, I think before we went too far into the cloud journey, we kind of had a rather small – we checked the different cloud vendors, at least three big ones. We realized Alibaba isn’t for us right now, so it’s basically…
[laughs] That’s a good one.
…so it’s basically S3, AWS or GCP. We looked a bit at the offerings, and we focused mostly on hosted Kubernetes, because we knew that was the big thing we had… And especially at the time - I think this was 2019 - the difference in quality was quite big. I think they’re closer now, and I probably think it would be a more different or more difficult comparison now. But at that time, it felt like Google had the by far the best hosted Kubernetes… Which kind of makes sense, because they’re the most, they’re the biggest – they’re the fathers of Kubernetes.
Yeah, I know what you mean. Do you feel like there’s something missing in GCP? Something that you would want to have?
Well, we are quite conservative in what we use. So I’m not really sure we… As I said, we want to focus on using open source components, or at least APIs of open source components. There seems to be a trend where the cloud vendor will say, “Well, this database is Postgres-compatible, but we won’t tell you what’s behind…” And that’s kind of okay. But as long as we want to use open source APIs and open source components, the number of services we use are quite small.
So I’m not really sure… We could probably get – Kafka, for instance, we’re buying from a different vendor; we’re running it on GCP, but we’re buying it from a company called Aiven, which is a Finnish company hosting open source databases. So yeah. That’s really a problem, but we’re quite conservative in the technologies we use, so I’m not really sure I can answer what I need, other than more open source… Well, Elastic, and Kafka, and everything. But Aiven gives us that.
[00:48:07.29] I think that’s a good strategy, right? The boring technology is what you would want to have, considering the stability that you require, right? You don’t want to be on the cutting edge, you don’t be trying things out; you want to go with a proven, tested, reliable software, that is open source preferably, so that if you want to or if you need to make a change, you can contribute that… And something that you can trust that will be around for the next 10-20 years, ideally, at least.
Yeah. Because we’re no startup, and basically, we’re not in a competitive marketplace. We’re part of the nation. So we have systems, not running on NAIS, but mainframe systems that are 40 years old. I’m not necessarily sure that the code we write now will run for 40 years, but the problem we’re solving is going to be needed to be solved for many, many decades to come. So it’s better to spend some more time doing it properly now, than trying to redo everything every fifth year because we hurried when we started.
That’s right. So are there any migration plans for the older services that have been around for decades?
Yeah. But then again, we’re basically rewriting everything… Well, that’s not true; for some of the systems, we’re rewriting them. For some of them, we’re looking into more different migration strategies. I didn’t know this was possible before, but you can take COBOL code and translate it into Java. Really strange… I looked at the Java, it looks really strange; it looks like COBOL, but it is Java. And then you can run it on normal servers. And then you can reduce the cost of the infrastructure quite a lot, because mainframes are really expensive, and Linux servers aren’t. But of course, there’s risks involved, because we have systems that has to work, and you’re making them run on the new technology. But our main strategy is to basically recreate the products that run on the old systems, on new architecture, and build them again with teams… Basically we try to frame the problems within an organization that can live as long as the problems need to be solved. Because I think the biggest thing is to have the teams knowing the domain, not having the systems being able to solve it, because of the timeframe we’re working in.
And what would a COBOL job ad even look like these days? Where would you find those people? [laughs] That’d be really, really hard. Okay…
As far as I understand, there’s loads of important stuff running on COBOL in the world. And a lot of the people who wrote them and know COBOL is getting old, and ready for retirement. So at some point, I presume it’s going to be very lucrative to learn COBOL, because not everybody has the opportunities we have to modernize, so…
Yeah, that’s true. That’s a good point. Okay. COBOL-owned Kubernetes. That is a startup idea right there… [laughs]
Well, when we started introducing Kubernetes, I think I had the argument, at least five different times, of how Kubernetes is basically exactly like the mainframe. There’s obvious similarities, but it’s also the clear differences.
Okay. What does a good day for Audun look like?
Yeah, that’s a really good question. [laughs] I had a really good summer holiday… The funniest thing in the world is to code. But then again, whenever I’m coding, I realize, at least most of the time, there’s bigger problems that need to be solved to make it fun to code. I spend a lot of my time trying to fix the big problems, and then hoping at some point we can code again.
[00:52:06.18] But of course, it’s also important to code, so I try to – or me and Truls and a few other people, we try to code a bit every week. And then the important thing is to find the things you can make that are important. That’s valuable, but not important, because sometimes we haven’t got the time to deliver… We can’t promise when anything will be finished, but it’s fun to make things that people like.
So trying to find kind of the small things… Right now we are working on trying to take the application configuration in NAIS, the NAIS YAML file, which basically says “What applications do you need access to, and what applications have access to you, and what Kafka topics do you need to write the [unintelligible 00:52:50.29] to?” And take this information out of the cluster and make a visualization of all the applications and who talks to who. And that’s fun, and I think it’s going to be useful, but no one’s asked for it, so no one no one can tell us we’re late.
Well, as you know, a lot of the time it’s the ideas or the things that no one asks for that prove to be the game-changing one’s. No one needs this until like “How did we live without it? Like, everyone needs that.”
Yeah… And the other thing that’s part of a really good day is when we manage to get all the other disciplines of NAV to understand – or that we learn something that’s important, from the lawyers, or the management, or whatever, and they also understand a bit more about what’s important to do, what’s the important frameworks to have in place to do modern software development? That’s not necessarily the same as running other parts of the government, because the soft part of software makes everything a bit different.
Yeah, for sure. So talking about frameworks, I know that you mentioned security few times… I’ve seen a blog post about SLSA… Where do you stand on the whole supply chain security, the SLSA model, things like that?
Well, I think at least for us it was an important next step. You’re kind of building blocks from kind of the basic stuff, and then you go further up, and you realize there’s always more problems to solve. When we open-source, and when we trust the teams as much as we do, it’s important to make the systems that can basically prove that the trust we’ve given them was okay; that we can say, “Well, we can see that this happened from that team”, and we know that this is okay.
For instance, when Log4Shell came, and although we’ve managed to get a handle on it, it was obvious that we could have responded even quicker by saying, “Well, what applications are affected by this?” and to automate that. This kind of feels like the next big thing, or the next thing, at least. One of the next things; there’s always multiple things.
So is there something more significant than this that you’re working on in the context of NAV? Something that is important to you?
Well, the one thing I mentioned - trying to see if we can make NAIS a platform for more than NAV… Because I think we are one of the biggest organizations in Norway, and we have 25 people working on platforms; some of the smaller governmental agencies maybe have 10 developers. And there is no reason to believe that they have the capacity to make as good a platform, or think through enough of the security aspect as good as we do. So if we can manage to make that possible for them, and help them as well, I think that’s really good for Norway.
I know the UK had something similar with go.uk. They had this platform-as-a-service, I think they had almost 30 different organizations running on this central platform…
[00:56:01.20] Yes, that’s right. Alpha Gov, I remember that. Yeah, I haven’t checked it recently to see where they are at now, but I remember that. That was a very interesting model. I know that the US government was doing something similar, and that was a reference at the time. It was many years ago - five, six, maybe more. Okay. Was that by any chance an inspiration for NAV?
Well, it’s something – one thing we really learned from gov.uk was the open sourcing. I remember reading their principles on open sourcing from gob.uk, and basically… Well, we started to translate, and then realized we could just link to it, and say, “We agree totally with this.”
Yeah.
And basically, because of that, we open-source almost all the code we write; not just the application platform, but everything we write at NAV, almost everything is open source, except for fraud detection, and some experiments with the laws that aren’t finished yet… And of course, some security aspects, like passwords, and everything. Most of the code we write now is open source.
Do you find that other people contribute to that, or comment? What is the interaction with that open source code from the public?
Most of the interaction and most of the use of the open source platform is kind of obscure libraries. We have one small Kubernetes operator that talks to [unintelligible 00:57:28.03] which is used by multiple companies. And then we have a Kafka testing library that someone used… But it turns out that there aren’t much of a market for open source unemployment benefit systems, for instance… [laughs]
Right. I see what you mean. Okay. So not much competition there… Okay.
No. It’s more about openness than about people. And we think that people should – we implement the laws that are public, so the code should be open and public as well.
Yeah, that’s right. Do you find it helps when it comes to hiring, when it comes to recruiting?
Yeah, absolutely. It feels like a valid proposition that software developers really like that we say, “Well, we code open.”
You’re attracting a certain type of developer that I think it’s very good to have. Okay, okay. Are there any talks that you or someone else from your team gave recently that you would like us to link in the show notes?
Well, Truls and I was at QCon in London in May, talking about NAIS and how we do technical governance, basically… That’s probably the best one from an international audience.
Is it public, the talk?
I think so. [unintelligible 00:58:45.04] If it isn’t public, I think it’s going to be public at some point, but I’m not entirely sure when.
Okay, I’ll check it out. I know that you have a very good blog, the NAIS.io blog. There’s a post on SLSA, there’s a few others… I think you mentioned about service meshes, there’s a post there, too… I really like it. I mean, there’s not too many posts there, so it doesn’t feel overwhelming… But what is there is very compressed, it’s very good… “The learnings from this” or “This is what we’re thinking about that.” And there’s not a lot, but it’s very valuable. I’ve found it just like browsing through it.
The newest post is about Elm as a frontend platform, the frontend framework. So the application platform concept is kind of a bit stretched now…
Okay. So as we are preparing to wrap this conversation up, is there a takeaway that you’d like our listeners to have from today?
For big organizations, I think an application platform is really valuable. And I think the main thing to think about when you make application platforms is to treat the intern developers of your company as users, and basically make an application platform the same way as you make an application. Do experiments, and think of the product, and try to figure out how can you solve the problems of your users, and then solve them.
Yeah. And write good docs. The docs on NAIS.io - they’re really, really good. There’s so much good stuff there. I really like that. Okay…
I haven’t written any of it, because I’m not a good writer… I think I one chapter somewhere in there, but most of it is written by other people. But I agree, it’s really good.
Alright, any shout-outs that you want to give to anyone from NAIS, from NAV, people that you work with that are doing amazing work and you want to give a shout-out to them?
No, the shout-out could maybe go to our /navikt GitHub profile, where you see all the other open source code, not just NAIS. I think that’s a good place to start.
Okay. Excellent. Alright, Audun. Well, I had a lot of fun today. Thank you very much for sharing so many amazing things with us, and I’m looking forward to next time. Thank you.
Thank you.
Our transcripts are open source on GitHub. Improvements are welcome. 💚