Panelists Suz Hinton and Nick Nisi discuss TensorFlow.js and Machine Learning in JavaScript with special guest Paige Bailey, TensorFlow mom and developer Advocate for Google AI.
Featuring
Sponsors
Rollbar – We move fast and fix things because of Rollbar. Resolve errors in minutes. Deploy with confidence. Learn more at rollbar.com/changelog.
Raygun – Unblock your biggest app performance bottlenecks with Raygun APM. Smarter application performance monitoring (APM) that lets you understand and take action on software issues affecting your customers.
OneMonth.com – One of the best places to learn how to code…in just one month. If you’re interested in taking your career to the next level head to OneMonth.com/jsparty and get 10% off any coding course.
Linode – Our cloud server of choice. Deploy a fast, efficient, native SSD cloud server for only $5/month. Get 4 months free using the code changelog2018. Start your server - head to linode.com/changelog
Notes & Links
- TensorFlow.js
- Google AI
ml5.js - Friendly Machine Learning for the Web - Machine Learning Glossary
- TensorFlow tutorials
- Tero Parviainen on CodePen
- tfjs-layers - High-level machine learning model API
- tfjs-models - Pre-trained TensorFlow.js models
- tfma-slicing-metrics-browser.gif 📷
- TensorFlow Model Analysis (TFMA) - a library for evaluating TensorFlow models
- What-If Tool - Building effective machine learning systems means asking a lot of questions. It’s not enough to train a model and walk away. Instead, good practitioners act as detectives, probing to understand their model better.
- EthicalMachineLearning.ipynb
- TensorBoard: Visualizing Learning
- TensorBoard: Graph Visualization
- People + AI Research (PAIR) - Human-centered research and design to make AI partnerships productive, enjoyable, and fair.
- Distill - Clear explanations of machine learning
- Book: Technically Wrong: Sexist Apps, Biased Algorithms, and Other Threats of Toxic Tech
- Book: Weapons of Math Destruction: How Big Data Increases Inequality and Threatens Democracy
- A new course to teach people about fairness in machine learning
- List of cognitive biases
- CleverHans - a Python library to benchmark machine learning systems’ vulnerability to adversarial examples
- CleverHans paper
- Breaking linear classifiers on ImageNet
- CV Dazzle - explores how fashion can be used as camouflage from face-detection technology, the first step in automated face recognition
{kind=link}
Transcript
Play the audio to listen along while you enjoy the transcript. 🎧
Good day! You’re listening to JS Party. This is another episode where we consider JavaScript to be a party. Thank you so much for joining us. We actually have some really exciting stuff to talk about this particular episode. We have our regular panelist - Nick, it’s great to see you!
Yeah, good seeing you, too!
And we have a very special guest joining us today to talk about a very exciting topic, machine learning. I am very excited to welcome Paige Bailey.
Hey, friends! Hello! Delighted to be here and to talk to you all about JavaScript and about TensorFlow.js.
Paige, you currently work at Google, and you’re a senior technical advocate for TensorFlow, is that right?
Yeah, I am on the dev rel team for TensorFlow, which is embedded within our research and machine intelligence org. Google has a whole bunch of developer advocates, you probably follow a lot of them on Twitter, or whatever your favorite flavor of social media is… But our org is a little bit different, in that it’s embedded outside of cloud, and right with the TensorFlow team. So it’s kind of rad that if something is broke, I can literally look over my desk and yell at somebody to fix it… So it’s kind of awesome.
That sounds very cool. So we’re gonna back up a little bit, because I know that in the JavaScript community some of us will have heard of just the term TensorFlow, or the actual tool, but not everybody knows what it is, so…
Me!
[laughs]
Nick’s definitely interested in finding this out too, so… How does TensorFlow fit into machine learning and what exactly is it?
Awesome. So TensorFlow is a library intended for numerical computation of all sorts. It’s not just for deep learning. You can also do traditional machine learning. If you have familiarity with things like decision trees, or random forests, or boosted trees, or super-vector machines, or logistic regression - all that stuff is supported with TensorFlow as well. So just think of it as like a numerical computing library.
If you have experience using Python, you might have used something called NumPy before, and TensorFlow can be almost used as a replacement for NumPy. But what it’s intended to be is a collection of tools, a very expansive API that gives you the ability to do these complex numerical tasks in a more straightforward way that can also scale. So not just on small amounts of data, but on any sort of data size that you have available and on a variety of data types; everything from text, to csv files, to video, to audio, to pictures… All sorts of stuff.
[04:20] TensorFlow got a whole bunch of press around 2015 when it was first released, because it created this really first robust end-to-end machine learning framework for doing these complex deep neural nets. And it had been used at Google historically for years and years under a different name, but Jeff Dean, who’s kind of a baller, was like, “Hey man, we’re gonna open source this…” (it’s true!), and then they did, and they’ve just been open sourcing more and more of it since then.
So that is kind of a long-winded example to what TensorFlow is. The TL;DR version is it’s tools that help you do predictive models, and also any sort of complex numerical computation… Usually with Python, but it’s grown to be a collection of languages, lots and lots of additional products. Now we have Swift for TensorFlow, we have TensorFlow.js, we have TensorFlow Lite if you wanna put TensorFlow on a phone, we have TensorFlow Extended if you wanna build these end-to-end machine learning pipelines, we have… Oh god, we’ve got TensorBoard to visualize machine learning, we’ve got JAX and XLA, and… The last time I checked, there were like 77 sub-projects under the TensorFlow organization repo on GitHub. So it’s a big honking thing. Does that help clarify it a little bit, or should I give tangible examples of stuff you can do with TensorFlow?
I’m obviously very new to machine learning and looking into all of this, but when I look for YouTube videos and such and the topic of machine learning comes up - maybe I’m just drawn to the cool name, but “neural networks” is the thing that comes to mind… So is TensorFlow a way to build neural networks, or is neural networks just a generic term for all of the computational things that you can do with TensorFlow, or what’s the relationship between those two.
That’s a great question. Neural networks are one kind of algorithm, or one kind of implementation that you can have for machine learning models. TensorFlow certainly helps you build those, and with the newer versions of TensorFlow, since Keras - which is a high-level API - has been embedded, you can build complex neural networks, train them, fit them, use them to predict things, with less than 10 lines of code of Python. And the same goes for TensorFlow.js - you can build complex neural network architectures capable of analyzing billions of images, or very massive input data, without having to think too hard about it. That’s the idea - you shouldn’t have to have a Ph.D. in machine learning, you shouldn’t have to understand the intricacies of linear algebra and ordinary differential equations and all the rest of it to be able to implement a neural network.
Can I ask what is the Hello World of a neural network, or what’s the Hello World that you would normally do in TensorFlow when you were first getting started?
[07:52] The Hello World of TensorFlow is probably the mnist example. Mnist is – if you’ve been doing machine learning, it is horrifically painful, because the dataset is used everywhere… It’s basically being able to take in images of integers, so handwritten digits from 0 to 9, and being able to classify them as to what digit they actually are. I am going in the Changelog Slack channel, I am going to put in the Python code that is sort of all that you would need to do in order to implement that model; it really is just a few lines… And what it’s doing, if you take a look at the chat window, is that you import the TensorFlow library, you import the dataset, you divide it into Training and Testing…
So you would take a portion of your data to build the model off of, and then you would hold out a little bit to make sure that whatever prediction you made was accurate, so data that your model hadn’t seen before, so it couldn’t cheat, you know? Then you would build out a model, and here we have a dense layer, a dropout layer and another dense layer. You would compile it with a loss function called “sparse categorical crossentropy” and an optimizer called the AdamOptimizer. There are lots of different kinds for losses and optimizers, and you can have a lot of different metrics that you would care about, but those are just the ones that you would use there. You run model.fit and say how many epochs you want, how many times you wanna cycle completely through the data, and then you would use model.evaluate to get the answer of how right or how wrong you are. But that’s all it is.
All machine learning models and all machine learning projects really follow that same pattern, in that you have training data, you have test data, you build some sort of model architecture, you run it on your training data, and then you test how accurate you were.
The intro to words that are used in TensorFlow glossary - I love it, yes! So we have a thing at Google called The Machine Learning Crash Course, and we have a machine learning glossary associated with the Machine Learning Crash Course. It is also a lot of words, but the words are explained, and you actually end up with some terms that are kind of cool, like crash blossom. Crash blossom should totally be the name of a band, but what it means is that it’s a sentence of phrase with an ambiguous meaning. You see those a lot in newspaper headlines; I think that the version that they mention on the website is “Red tape holds up skyscraper”, because it’s like “Wait, what? What does that actually mean?” But I love it; they cause a lot of problems in natural language understanding tasks, because of ambiguous meanings.
This is a Hello World example, but it’s actually being applied to lots of different real-world cases, for like at least a decade or two, right? For example, recognizing handwritten numbers is very useful when you’re trying to cash a check by taking a photo of the check. Is that sort of what that would be used for?
[11:52] Absolutely. You are spot on. Also, I think the first use case that it was used for was back in the ‘90s… Whenever the U.S. postal service, whenever people still sent mail, they would use it to detect the zip codes on envelopes, and automatically sort them based on that. So it’s sort of a very useful application; everybody loves being able to automatically transcribe something that they take a picture of, but it’s also straightforward in that it’s less than ten lines of code to do a thing.
For that last layer you might notice that it says “activation = tf.nn.softmax”, and then there’s also a 10 there. What the 10 means is that you have 10 different options for things that it could classify… So 0, 1, 2, 3, 4, 5, 6, 7, 8, 9, and then softmax just means that it would be a classification problem. So you’re picking one of those ten things, as opposed to giving a numeric value, like 9.2 or 12.5 as an estimate.
So this Hello World example with TensorFlow - is this specifically a neural network?
That is a neural network, yeah. It’s using the higher-level API that I was telling you about before, Keras… And that’s one example of a neural network. And let me also link the tutorials page.
I actually watched a video on this beforehand, as research on this specific problem, and I think that this is actually doing the same thing, because I see 28 by 28 in there for input shape, and I’m assuming that that’s the pixels of the image that you’re trying to classify.
Yeah, you are 100% spot on.
Yeah, so it’s turning that into just like an array of pixel values for zeros or ones, or values that represent whether the pixel is colored or not, and then it’s taking that from – I forgot how many that is… I can’t remember exactly how many are in a 28 by 28 array, but taking that and then boiling it down to a number 0 through 9.
Yup. And the mentality behind… So the idea behind Keras and behind the super high-level APIs is that developers – so if you’re building a web application and you wanna be able to do image classification, or if you want to be able to do text classification or something of that nature, you shouldn’t have to… I mean, it’s cool to understand the internals of a neural network, and to understand that when you select this particular kind of loss, it’s applying this sort of transformation, or if you select an atom optimizer, it’s putting this much tweaking the numbers and turning the knobs and dials in this way in order to help better predict whatever value that you’re trying to… But the idea is that if you’re a web application developer, you shouldn’t have to know all of the internals of how a neural network works in order to deploy a model to production. But it’s good to know, and it’s especially good to know about the ethics of models and about how data can influence model decisions, but in terms of having to know the linear algebra - that shouldn’t be a prerequisite for being able to do cool things with machine learning.
[15:57] You mentioned web developers, and you mentioned also before that TensorFlow.js is a thing; theoretically, is this just me running a library called TensorFlow.js in the browser, and then would I be able to actually load something like a model that is doing like the mnist dataset to figure out what the handwritten number is - is that something that you could practically run in the browser, and is the browser powerful enough to do that?
Oh yeah, absolutely. Yes, the browser is 100% powerful enough to run TensorFlow.js, and they also recently released Node bindings…
Uuh…
Yeah, so that allows the same JavaScript code to work in both the browser and Node.js, while binding to the underlying C implementation. That’s pretty rad… And there’s also – so being able to use the GPU that you have in your laptop to train, even though you’re running and creating this model in the browser, is really nifty. Does that sort of answer the question?
You can do a lot of really interesting – most of my favorite TensorFlow examples, actually, are all created with TensorFlow.js. You can do pose detection in the browser - so if you’re standing in front of your webcam and you’re sort of flailing your arms around, or doing a jumping jack or something, it’s able to detect where your limbs happen to be, it’s able to do eye-tracking, able to do basic object segmentation, so it’s able to detect that I am a human and draw a little line around me…
There’s this guy named Tero; let me also put a link to his work… His handle on CodePen is @teropa, but he does the most awesome CodePens for experimental drum machines using neural networks, and sort of manipulating harmonics using deep learning. So the idea is that you can create a melody with the guitar, and then automatically have a drum accompaniment, or a bass accompaniment created for you. I’m enchanted by the creativity that folks have been showing with the TensorFlow.js examples.
These examples - are they using a pre-trained model, and then just applying that in real-time in JS?
Yes. I think the examples that you’re playing with on the website - they’re using a pre-trained model. But you would also be able to train your own models in the browser, if you wanted to. If you wanted to do object detection on custom images or custom entities, you could use transfer learning on top of the existing model to make those modifications. I love the pose detection, that’s interesting.
Would there be a time that you would train something in the browser and a time that you would not train stuff in the browser? Is there sort of performance considerations to take in account when deciding whether or not you actually need to train something in the TensorFlow.js environment?
[19:56] That is a great, great question. I personally prefer – hm, let me back-track… So if you have a very, very large model, you should probably be training it using TensorFlow Core, and then exporting it as a saved model to TensorFlow.js. The friendly 10 lines of code syntax that I showed you before - that works to export as a saved model.
If you have a small machine learning problem, it’s fine to train it in TensorFlow.js. You might not see as high of accuracy as you would expect from a TensorFlow Core model, but it will still be good enough to solve the task. And then also the slowness factor… So if you train in a browser, using TensorFlow.js, it will probably be a bit slower to train than if you use TensorFlow Core… And especially for large-scale models. So the small-scale stuff - it will still train in a reasonable amount of time; the large-scale stuff - it might be 10 to 15 times slower.
I think that there’s a benchmark on the website as well, to kind of give an idea… Yeah, let me send a link over to that guide. So the idea is that, for the most part, you can train lots of models using TensorFlow.js. They’re creating a models repo… Let me pull up the link for that one as well. But the idea for that is sort of a model garden where, again, you don’t have to know everything in the world about neural networks and machine learning in order to implement and to use the things that researchers have created. So that link right there is a link to tfjs models on GitHub. You can see mobilenet, so classifying images with labels, posenet, so the real-time pose detection that you can see in the browser, object detection, speech commands, k-nearest neighbors, and they’re growing out this repo pretty substantially and very, very quickly. You can use off-the-shelf, state of the art models without having to understand the machine learning internals.
That’s really cool. So I can just pick a model based on the problem I want, whether it’s trying to translate speech, or trying to find edges of things, or digits, like in that example… Is there a way to take a pre-made model like this and manipulate it a little bit, to change it for a slightly different problem set?
Yes, and that’s something called transfer learning. What transfer learning does is it takes a model that’s been trained on sort of a large-scale dataset, or maybe with some very powerful architecture over a long period of time. It takes the insight that was gained from that model, and then it adds a couple of additional layers to the top.
[23:28] For example, the image detection model - it can detect a lot of different entities out of the box. It can detect dogs, it can detect cats, it can detect coffee mugs potentially, and people… But if you wanted it to recognize specific people or specific kinds of dogs… So to say like “This is a Chihuahua, and that is a Dachshund, and that is a Boston Terrier”, you would be able to build off all of the information that the model has already learned about “Oh yeah, that’s a dog”, provide maybe five to ten examples of what a Boston Terrier looks like, and five to ten examples of what a Chihuahua looks like, and five to ten examples of what whatever your favorite breed of dog is, and then that model would be able to re-train… It wouldn’t take nearly as long, because you would have much less data, and it would have this entire, big, long history of things it’s already learned to pull from, but it would be able to understand “Okay, I see an image, and that is a Chihuahua. And that is a Boston Terrier etc.” for that task.
That was an image example, but it works the same way for text - though text is a little bit trickier to apply in multiple domains - to video and to audio.
I actually think that I’ve done this with audio, now that I think of it.
What use case?
Oh my Twitch stream I wanted to have automated closed-captions, because I couldn’t pull together a budget to have live, human-made captions… So I took a regular American English conversational model and then I created a dataset of my own speaking, the words that I was saying on Twitch stream, obviously my accent and any background noise, and I used that along with some subtitle files in order to try and generate an additional layer on top to make it slightly more accurate. Is that the same as what you’ve just said?
Absolutely, that’s transfer learning. It’s taking all of the information that it’s used to understand English from a variety of different speakers, and then it’s sort of specially tuning to your voice. So it already understands what specific words are, and now it understands what those words sound like when Suz says them. So yeah, you used transfer learning. Congratulations! [laughs]
Yay! It did actually push the accuracy up. It didn’t push it up enough for me… Like, still one in ten words is wrong, which sounds really great, but it does sort of go on a weird chain if one word is wrong, for example… But it was really exciting to see that that works, and that I didn’t have to do the hard work of having to create that existing model in the first place, which is really cool.
Yeah. And having to source all of the data, that’s the other big thing. Because to train models to really high accuracies you need a massive amount of data, and also really high-powered hardware, so clusters of GPUs, or things like TPUs… Or if you wanted to roll your own [unintelligible 00:26:54.04] but sort of those high-end architectures that are also pretty pricey… And a lot of people, myself included - I don’t have access to massive amounts of data, so being able to take the models that other folks have created and to build off them with my much smaller datasets, but still achieve high accuracy… It’s pretty nifty.
So we talked about the fact that you can run models and also train models in the browser, but one thing that we sort of haven’t really touched on is why are we trying to do this in the browser itself; what kind of advantages does that give us?
That’s a great question. I think one of the reasons that TensorFlow.js started was because not everybody has access to high-end computational power. Browsers are kind of ubiquitous. If you wanna hit everybody, you probably would want to implement it in the browser, as opposed to making somebody use Python, or making somebody use something like C++. So having machine learning in the browser was a natural choice, in that it’s where you can impact the most developers, and give them the tools to create these impactful projects.
Another reason I think is because you have so many additional sort of – like webcams, and being able to use posenet or object detection from the webcam on your laptop… That’s also an amazing tool. And being able to open up a browser from a phone is also pretty rad. That was kind of the motivation - we wanna do machine learning for everybody. If we’re wanting to do it for everybody, it can’t just be Python; let’s put it in the browser, too.
That’s really cool.
If it can be written in JavaScript, it eventually will be. [laughter]
SkyNet’s gonna be written in JavaScript, right? That’s the thing…
For sure. We touched on this a little bit at the break, but could you maybe summarize what some production examples of TensorFlow might be?
Oh, absolutely. This is one of my favorite topics - machine learning sounds great, but I don’t really care about hot dog/not hot dog… [laughter] Or I don’t think that there’s a use case for determining if something is a cat or not. That seems kind of silly… And I agree, I agree 100%. But some tangible use cases that you could have, for example, would be - imagine how cool it would be if you were typing an email and you were typing a sentence that might be taken offensively, without recognizing it… Because it’s the middle of the day, you haven’t had coffee maybe; everybody feels kind of stressed at work… Think about how cool it would be if you had an automatic typo-looking suggestion pop-up saying “Hey, this term might be taken in a bad way. Maybe try these other words instead, that might be a little bit less aggressive.” Or maybe “This sentence could be taken multiple ways. Maybe you should include an emoji to make sure that folks know that you’re not being angry, you’re just being playful”, or something of that nature.
[32:09] Another great use case is Amazon - whenever it makes recommendations of what products you should buy, or Netflix, whenever it makes recommendations that “Hey, you should watch Black Mirror.” It’s because it’s looking at all of the other viewing patterns of people similar to you, analyzing all of them, doing something called Market Basket Analysis, or matrix factorization even. Market Basket Analysis is kind of computationally-intensive, but that’s a rabbit hole.
So just think of it as it’s looking at a lot of people who have interests similar to yours, and it’s saying “Well, Jane, who also liked A, B and C, watched D, so maybe Suz would also like D.” That’s another example.
The other use case that we talk about a lot at Google is a mobile application that’s able to detect diseases in plants. This is being used in Africa, where Wi-Fi connectivity is kind of spotty. The model has actually been exported, so it doesn’t have to rely on internet connectivity. Farmers can take a picture of a plant leaf, and based on a corpus of data that it’s been trained against, the model can tell them what kind of disease that plant leaf has, and then also how they would go about treating it. Those kinds of specific use cases.
I feel like the machine learning community latches on to some of the more playful aspects and the more fun examples, but in reality there are so many impactful ways that machine learning can help businesses, and they aren’t quite as sexy as the Silicon Valley examples, but they are really cool. And TensorFlow.js and TensorFlow are more than capable of taking care of any machine learning task.
That’s really cool. And given that this is being used in production, and it’s becoming really popular, of course another big topic in machine learning too is things like machine learning ethics, and where the data is actually coming from to train these models, and things like that… And then you even look at things like adversarial machine learning attacks as well. I wanted to leave enough time to talk about that as well, just so that people are aware of some of the gotcha’s to look out for… But let’s talk about maybe first some of the more foundational parts of machine learning ethics and data sources, and things like that. Can you introduce us to where machine learning can sometimes go wrong?
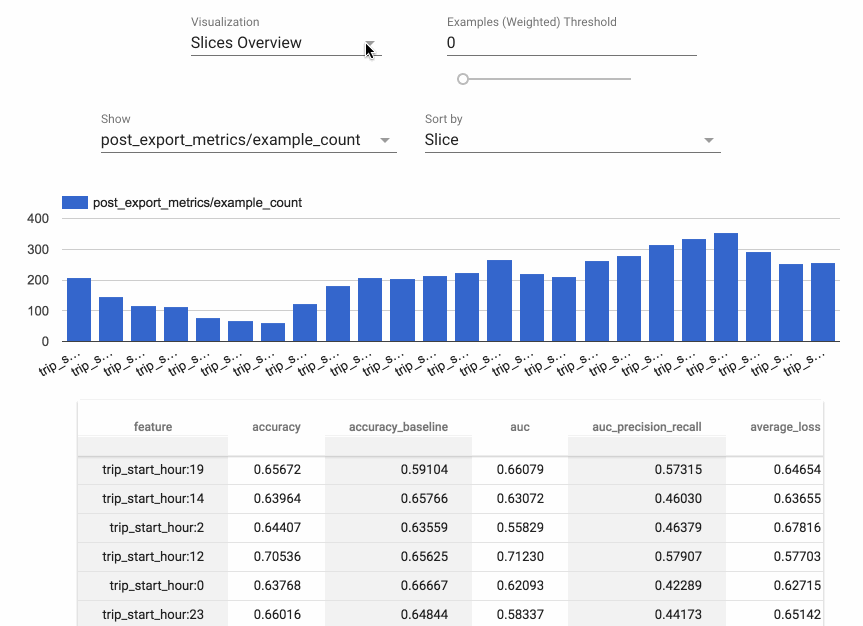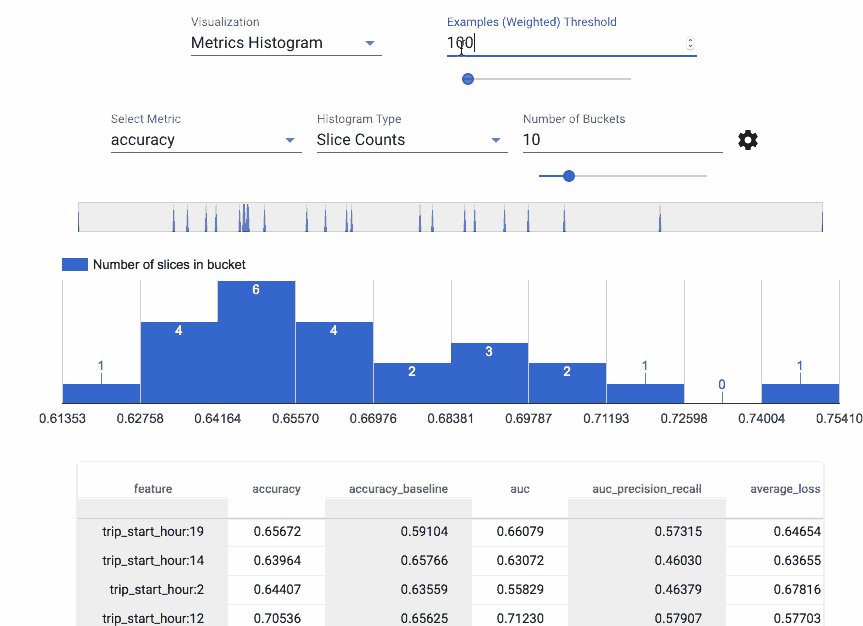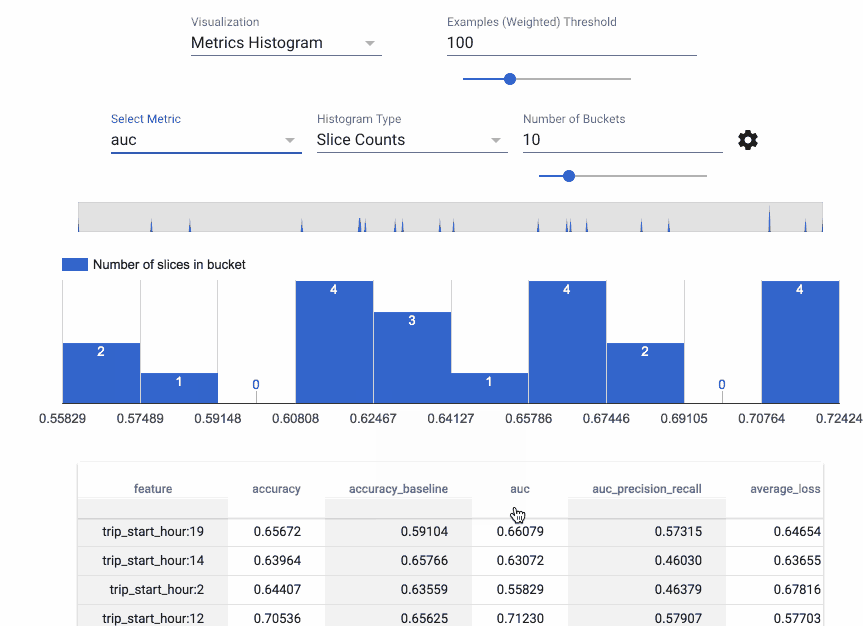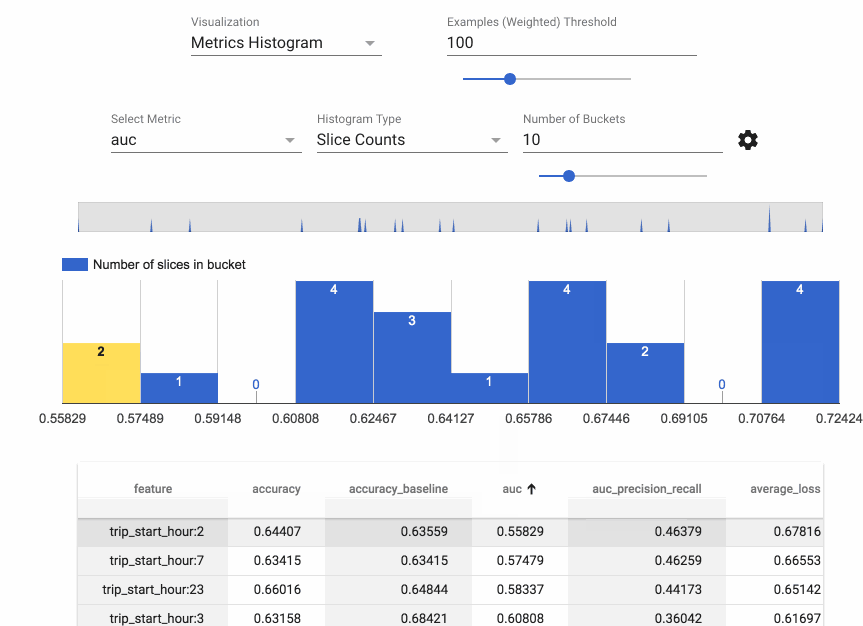
Absolutely. I’m also going to – I hope Slack supports GIFs. Let me put that in there. This is something called TensorFlow model analysis. Oh man, it didn’t do it; gosh darn! Let me put the link there, and then also the link to the GitHub repo. There’s that, and the what-if tool as well. So machine learning models - they’re only as good as the data that you put into them. That is not a debatable topic.
[36:00] If you have a child that you’re teaching how to recognize squares and triangles and circles and all the rest of it, if you haven’t been teaching the child what a circle looks like, there’s no way that he/she would be able to understand that shape.
Or say you’re talking about dogs in a country that only has five particular breeds, and you go to a different country that has a dog that’s not one of those five breeds - you probably wouldn’t be able to accurately classify it, because you had never seen that data before. That’s kind of a fumbled example of your data is incredibly impactful. And what you see whenever you have data that’s biased being used to create machine learning models, is that groups that are marginalized or groups that are excluded from the dataset, or included in the dataset but in a negative way, just have those stereotypes perpetuated. And what does that mean?
A lot of people have heard about – so there’s a test that incarcerated individuals take towards the end of their prison sentence, that determines whether or not they would be eligible for a parole. This test includes a lot of questions like “Was anybody in your family also incarcerated?” or “Were your parents divorced?” or “Did you go to college?” A lot of questions that really have nothing to do with the person themselves, and are completely out of control of the person. You don’t have any control over whether or not your parents get divorced; you don’t have any control over whether or not people in your family have gone to prison. And those questions - they negatively impact people in already marginalized groups, so people of color, and people who come from lower economic backgrounds. And what they’ve found is that this test was preferentially granting early release of prison or early parole to white males who came from wealthier backgrounds, and it was negatively impacting men of color who came from impoverished backgrounds. And that was entirely due to the fact that the machine learning model that was created to predict whether or not people would have recidivism, whether or not they would start doing crime, was being built on this corpus of data that was sort of pointing towards men of color being especially likely to do that, when that is not the case at all.
So building models on data that is already biased means that you’re going to have a biased model, and it’s really difficult to understand where some of those biases could arise in data, which is why we have built tools as part of TensorFlow, to help understand datasets and to spot those nuanced differences and features.
So here you have two links - one is the model analysis tool, and the other one is the what-if tool from our Google research entity called PAIR, which is People in AI Research What it does is it sort of guides you towards questions that would be useful to ask as you’re creating your model, to say like “Well, if we look at the distributions for marginalized groups, what does this mean?” And also it helps sport related feature types; for example, zip code and race are very commonly related, and that might not necessarily be straightforward if you didn’t have experience working with census data. Does that make sense?
[40:17] It does, and I’m really glad that there are these frameworks coming out for you to ask those questions… And I even remember referring to one of your resources that you made (I think) at least a year ago, which was very helpful for me to understand where things can go wrong.
Yeah, the one from rOpenSci. I can link to that as well. If you’re a researcher, nobody ever wants to hurt anybody; “assume no harm” should be the first thought for all of us. If people aren’t given insight into the questions that they should be asking, it’s really hard for them to understand where things could go wrong.
The resource that Suz is mentioning was a collection of questions that can be asked throughout the entire model-building process about where is your data sourced, how is it refreshed, how are you intending to keep it up to date, what would be one of the ways that the ethical machine learning vignette, and it was for rOpenSci Unconf. It was very focused on spotting and preventing proxy biases in machine learning, and I used the example of race and zip code when predicting [unintelligible 00:41:55.12]
Very cool. We’ll make sure to provide all of these in the show notes for the episode. It makes me wonder if we can eventually get meta with this kind of problem, because as you mentioned, there’s so many problems out there that are already using machine learning to, you know, figure out what I wanna buy next on Amazon, or watch next on Netflix, or whatever, but then all of these models that might have been created that do have these biases in them - I’m wondering if machine learning can help you predict if your model is going to have bias, eventually.
Yeah, I would love to see that… Or at least being able to better understand data sources, and to be able to spot when you might have unintentional bias in your data. That’s a great idea.
And just on that topic, if you’re not really in the machine learning field and you’re actually trying to choose a model to use for yourself, but you don’t have a lot of that background knowledge, given that models can really be a black box, is there any way for you to be able to somehow judge if it’s going to be a model that isn’t biased in negative ways? What kind of questions can you ask yourself when you’re on that side and you’re not actually the person developing the model?
Gotcha. It’s always really hard to understand what data goes into a model if you don’t have a direct influence on that model’s creation process… But there are tools – I’m thinking in particular of TensorBoard, which is… Let me put a link to that as well, and then also a link to the TensorBoard GIF, which is probably the best description of it. It allows you to look at model architectures and to understand what decisions are being made, where and when.
[44:02] For example, one study that was done a while back - it’s kind of notorious in the machine learning community - is that they had a collection of photos of people, just potrait photos of folks, and the research question was something to the effect of “Can I detect whether or not this person is gay?” Detecting whether or not a person was gay, based solely on a photo… Which is ridiculous. That is one of the silliest research questions that I have ever heard in my entire life. But an academic published a paper saying “Yes, absolutely they could, and here’s how, with machine learning.”
So a group of researchers at Stanford challenged that assertion and said “I don’t think that you are able to accurately gauge whether or not a person is gay based on a photo.” And they’ve found by highlighting the pixels that were being used to make those assessments during the machine learning process that what the model was picking up on wasn’t anything about the human themselves; it was detecting piercings on the face, so people with alternative sexualities or people who prefer – for whatever reason, the sourced images had preferentially more piercings that people who were heterosexual, and the model was picking up on that. It would detect a piercing, and it was using that as a proxy to say “This person is gay”, which again, is ridiculous.
And then there was the other aspect, that often the photos of people who were gay were taken from a different perspective, from looking up into the camera, as opposed to looking straight on, and that was also being picked up by the machine learning model… And it has nothing to do with the person themselves, just the sort of way that the photo was taken. It’s very unnerving to think that that was a paper that was published, peer-reviewed before published, and that nobody challenged throughout that process.
Yeah, that’s crazy.
Yeah, and I can hunt down a link for the PDF of that guy as well… But it was awful. I see a question from David, “AI leading to inadvertent discrimination is really interesting” and that is 100% true. Tiny input differences do have massively different outputs over time.
The other thing is that if the models aren’t kind of checked and QC-ed, they just perpetuate the bad assessments that they were making before, you know what I mean? So they will preferentially not give loans to people of color who come from low economic backgrounds, or they will preferentially not allow people of color to be able to be up for parole in a reasonable amount of time… Unless you are actively asking questions to challenge the model’s assessments.
[47:57] As an industry, I think that it’s on all of us, if you’re doing anything with machine learning, to ask these questions if something smells fishy… Again, it doesn’t matter if you have a Ph.D. If it sounds like it a model assessment might be wrong or biased in some way, absolutely challenge the data science team that’s being used to create it.
The entity that I was mentioning before, PAIR at Google, People in AI Research, is a human-centered research and design initiative to make AI partnerships fair, and to make sure that we have tools that will be able to help spot these biases. TensorBoard is one of them, the what-if tool is one of them, the visualizations that happen through this publication called Distill.pub - and that’s supposed to be a link, but I guess it didn’t go… But it’s this beautiful publication that goes into what is actually happening whenever a machine learning model makes its assessment, and how can we really understand the mathematics behind it, because it’s so dang complicated; it’s more complicated than a human could possibly understand… But how can we shine a light onto these decisions.
This is great… And I wanted to also throw in a couple of recommendations for myself, if you’re trying to understand this topic at a higher level - I found two books that really helped me: Technically Wrong, and also Weapons of Math Destruction, which was a really clever title, but it was also very helpful. So if you were looking to get a high-level grasp of the topics before diving into some of these more technical resources, then I would definitely recommend those two books.
Absolutely. And then there’s also like a little one-hour ethics extension to Google’s Machine Learning crash course - 60 minutes, self-paced, and it goes through a lot of biases that you experience in machine learning, but it’s also interesting in that those biases are expressed in everyday life as well. So if it can fool a human, it can also fool a model. It’s really interesting to see.
I am so excited to talk to you about this topic… [laughter] So Paige…
I know what you’re gonna ask, and I’m super-jacked about it! [laughter]
For those who are listening, Paige and I actually still work together, and one particular topic that I got excited about, that I know that Paige is really excited about, that I couldn’t not mention - Paige can you talk to us about the topic of adversarial machine learning? What is that? And it does actually tie into the ethics a little bit too, from the previous segment.
Absolutely, and I just posted a link in the Slack channel about a library called CleverHans, which doesn’t get nearly enough love, but which is something that I vitally enjoy. One of my colleagues, Ian Goodfellow, is the lead. Think of it as the Red Team from machine learning. The Red Team for security is like “Okay, you’ve built this enchanting ivory tower system… I’m gonna see if I can bring it down.” CleverHans is like the Red Team for machine learning.
Uuh…!
Yeah, right…? So a question - you have machine learning models, you have this great pipeline where you can input some sort of data, and then get back some sort of predictive assessments with some sort of confidence level, so “I think that this is a dog with 85% confidence”, how would you go about breaking that? And the answer is that it is exceedingly fragile to be able to manipulate these systems in ways that would bring them down catastrophically. What do I mean by that?
There’s this great example - and I’ll send a link to the paper; it’s probably listed on the CleverHans GitHub as well - there was a research team that was looking at a classification model for pandas and for gibbons (monkeys), so it was looking at various animal types… And you would have an image that was very clearly a panda; the machine learning model would correctly assess that it was a panda, with pretty good confidence, and then the question was made of “Well, what if I introduce a small amount of noise into this image?” What if I take just random noise, apply it – here we go… I found the tweet from – because everything I do, I tweet. And eventually, I will be an old lady and I will be delighted, because I will have this complete timeline of my life. But there we go.
So it has a panda, with 57.7% confidence. You introduce a very small amount of random noise to the image. To a human, it still looks exactly like a panda, it looks exactly the same, but suddenly your neural network thinks that it’s a gibbon, a monkey, with 99.3% confidence - a massive amount of certainty that this is a gibbon, when in reality it is totally a panda.
You probably also saw the example a while back where you had a turtle that was painted in such a way that a neural network thought that it was a gun… And there are stickers that can be placed on street signs, so that neural networks that are used for self-driving cars might not be able to detect that those are street signs that they should stop at.
[56:08] There are ways that you can put on make-up, that make it so that the facial recognition networks don’t recognize who you are… It’s amazing – well, not amazing; it’s terrifying, and awesome, that these systems have been so optimized for particular tasks that they just break if you show them something that’s completely outside of the realm of their experience.
I like to talk about over-fitting the same way that I talk about learning things in school. Everybody went to school with the kids that were super-great at memorizing stuff. You gave them a list of terms, and they were able to spit back out exactly the definition; or if you gave them a math problem that they’d already seen, they were able to regurgitate the answer without thinking too hard about it. But if you showed them something new, so if you gave them something that they had never seen before, a problem that required some sort of creativity, that required them to apply what they had learned previously to a new situation, they just weren’t able to do it… And that is over-fitting a machine learning model - it’s very good at making assessments on data that it’s already seen before, and then when you show it something that’s just a little bit new, it’s unable to generalize to this new situation.
And yes, the answer – David, you were 100% spot on. Imagine if you had a system that was tasked with determining whether or not there would be a missile location in a satellite image, and you had a nefarious actor that was working either internally or externally, that decided to manipulate images with random noise, in the hopes that your system would think that there was some sort of missile location in a place that was completely innocuous. Or to be able to obfuscate a missile location from the satellite image itself.
You also see things like deep fakes, which is outside the realm of adversarial machine learning, but is also very troubling. The tooling that we build - again, things like the what-if tool, things like model analysis, things like TensorBoard, being able to spot these changes in data, being able to spot images that have been altered in some way… This is going to be huge.
And again, it’s all of our responsibility to make sure that we push companies to be doing this work, because again, it’s just so easy for these fragile models to be compromised.
Definitely some good food for thought. Thank you so much for covering that. I don’t know about you, but I’m probably not gonna sleep as tight tonight, thinking about this kind of stuff… [laughter] But it’s really important to share how exciting machine learning is, but obviously the gotcha’s and the sort of Spiderman “Great power, great responsibility”, so I really appreciate you being able to talk about such a massive breadth of what machine learning actually involves. This is awesome, thank you so much.
Yeah, thank you very much.
[01:00:16.13] Thank you for inviting me. This was fun, and I highly encourage everybody to try out TensorFlow.js. If something breaks, please yell at me on Twitter, or yell at me via email. My address is webpaige@google.com. Also, again, just to reiterate, you don’t have to have a Ph.D. to challenge what a model is assessing. If something doesn’t strike you as being particularly fair, or if something strikes you as being biased, definitely speak up and make those concerns known, because it’s all of our responsibility to be the watchmen for this stuff.
I have huge optimism for what machine learning can do for society and for businesses and for people, but also a very healthy respect for how much it’s going to take all of us working together to make sure that that reality is the reality that happens.
Oh, Paige, that was the perfect last sentence to take us out. Thanks. I’m gonna stop it right there. [laughter]
Our transcripts are open source on GitHub. Improvements are welcome. 💚