
Seth Vargo, the Director of Technical Advocacy at HashiCorp, joined the show to talk about managing secrets with their open source product called Vault which lets you centrally secure, store, and tightly control access to secrets across distributed infrastructure and applications. We talked about Seth’s back story into open source, use cases, what problem it solves, key features like Data Encryption, why they choose to write it in Go, and how they build tooling around the open core model.
Featuring
Sponsors
GoCD – GoCD is an on-premise open source continuous delivery server created by ThoughtWorks that lets you automate and streamline your build-test-release cycle for reliable, continuous delivery of your product.
Toptal – Scale your team and hire from the top 3% of developers and designers with Toptal. Email adam@changelog.com for a personal introduction.
Notes & Links
JS Party goes live February 24 at Noon PT / 3pm ET.
Click here to subscribe or submit an issue to suggest topics for future episodes.
- Carnegie Mellon University
- CustomInk
- Thanks to @DerfOh (Fredrick) for submitting issue #605 to suggest this topic
- Vault by HashiCorp
- Vault on GitHub
- Vault docs
- Terraform
- The Tao of HashiCorp is the foundation that guides HashiCorp’s vision, roadmap, and product design.
- HashiCorp Releases
- Shamir’s Secret Sharing
- HashiConf
Transcript
Play the audio to listen along while you enjoy the transcript. 🎧
Welcome back everyone, this is the Changelog and I am your host, Adam Stacoviak. This is episode #239, and today on the show we’re joined by Seth Vargo. Seth is the Director of Technical Advocacy and employee number four at HashiCorp. We talked about his back-story into open source, their open source product called Vault, which lets you centrally secure, store and tightly control access to secrets across distributed infrastructures.
We talked about the use cases, the problems it solves, key features like data encryption, why they chose to write it in Go, and how they built tooling around the open core model.
We’ve got two sponsors today - GoCD and Toptal.
[01:10] to [\00:01:40.25]
Alright everybody, we’re back. We’ve got Seth Vargo joining us today. Jerod is not here, he’s AFK for the week, so I’m here solo with Seth, talking about security, keeping secrets, developer advocacy, all that fun stuff. Seth, welcome to the show, man.
Hey, Adam. Thanks for having me, I’m super excited to be here.
From what I understand, you also are from Pittsburgh. The audience don’t know this because I don’t often say it, but I’m originally from Pittsburgh. I live in Houston, Texas, but Pittsburgh is my growing up stomping grounds, man.
Yeah, I’m from Pennsylvania, but I moved to Pittsburg in 2009, did my undergrad here at Carnegie Mellon, I kind of fell in love with the city, and… I can’t say I haven’t left since, because I flew 300,000 miles last year, but I pay rent here. It’s a beautiful city, I love the culture, the food, the sports teams, the whole nine yards.
Pittsburgh Steelers fan, I’m sure, right?
For sure.
Penguins? Hockey’s your thing, or no?
Soccer’s actually my thing. The Riverhounds are pretty good. You’ve probably never heard of them, but that’s okay.
Since I’ve left, I haven’t been… I don’t know, I’m not familiar with that team,
They’re pretty good, but yeah, the Penguins, Steelers, Pirates… I try to get to as many games as I can.
I love Pittsburgh, man. It’s an awesome city and a beautiful place to be in the fall, that’s for sure. The change of season is to die for, that’s for sure.
Definitely.
Well, this show was actually kicked off by a friend of the show, Frederick Paulin, aka DerfOh on GitHub. In issue 615 (we’ll link it up in the show notes) he said Vault is a lightweight tool written in Go, which we love, of course… We have a show called GoTime; if you haven’t heard of it, go to GoTime.fm. So he asked us to kick off a conversation with you, you responded back on GitHub, and next thing you know we’ve got an email kicking this thing off - that was about 20 days ago - so here we are, talking about Vault, which is an interesting tool from HashiCorp.
You’ve been there for a couple years now… This is an open source tool from you all that helps manage secrets in the DevOps space. It’s a lot of fun there - passwords, API keys, encryption - lots of fun stuff around that. But one thing we like to do is kick of the show with getting into the back-story of the person who comes on the show.
[04:03] We know you work at HashiCorp, we know that you’re the Director of Technical Advocacy there, which I’m not even sure what that is, but I’d love to hear about it from you… But help us with your back-story, Seth. What got you into the position you’re in now. Not so much where you’re at, but what’s your story? How did you get into open source, how did you get to HashiCorp?
Sure. Like I said, I did my undergrad at CMU, which is what brought me to Pittsburgh. One of the programs that I was in - the information systems program there - was super into open source. They encouraged all their students to not only consume open source, but also author open source. [unintelligible 00:04:38.04] one of the first repos I wrote was this Ruby tool that pulled some data from the international book database, and that was basically all encouraged and my professors helped me get that out there. Since then, I kind of fell in love with open source.
After that I graduated, I worked for a company called Custom Ink; they make T-shirts, but I worked on the web operations team there. I was introduced to a configuration management tool called Chef; I worked with some really great and bright people. Custom Ink has a really interesting technology platform for online ordering. You can design your T-shirt and everything online, and that’s supported by some of the smartest tech people I’ve ever worked with, building that and maintaining that.
The team I was on was responsible for making sure it was always up and running, so this is where I got exposed to the DevOps space a little bit more, cloud technologies, configuration management… Then I left Custom Ink and went to work for Chef, the company that makes Chef. I was at Chef for about two years, where I worked on a number of the different ecosystem parts. I wrote the book Learning Chef published by O’Reilly, and worked on the community tools like ChefSpec and Test Kitchen and Berkshelf. I worked on the release engineering team and the community teams at Chef as well. That’s where I started getting more into the advocacy, public speaking, doing meetups and blog posts and podcasts like this.
Then I joined HashiCorp about two and a half years ago. I kind of started as an engineer. I was employee number four; when you’re a four-person startup, you kind of do a little bit of everything. You’re the accountant and the engineer, and…
Sales…
…all of the VPs at once. But as we grew, people started specializing. HashiCorp are really dedicated to open source; we’re an open source company, everything we do is open source, and we’re really committed to that mission. Part of that is the evangelization and the technical advocacy part. My role is largely engaging with the community directly, through Twitter and GitHub issues and one-on-one at conferences and meetup groups, and then indirectly through things like podcasts and blog posts, videos and conference talks and trainings.
It’s funny that you were employee number four - well, not funny, I guess, but just funny happenstance, because we’ve kind of been chronically into (some degree) Mitchell Hashimoto’s work, who started HashiCorp. It wasn’t even HashiCorp at first, it was just simply Vagrant. It was this open source tool and they blogged about it when we were simply just a blog and also a podcast. Then we had him on the show in 2012, which I believe is roughly when HashiCorp took off, or it was in its infancy, basically. So you were employee number four - that’s cool.
Yeah, it’s great to see how we’ve grown. Mitchell and Armon, the two founders of the company… Obviously, they’ve been around since 2012, but even though the company was called HashiCorp, a lot of people thought of it as “the Vagrant company”, or “the company that makes Vagrant”. We came out with a ton of open source tools since then, all popular in their own veins, targeting different segments of the market.
We still have Vagrant, it’s still very popular. We have Packer, a tool for building automated machine images; Consul, which is a tool for service discovery; Terraform, which is a tool for provisioning infrastructure; Vault, which we’ll talk about today, is a tool for secret management. And Nomad, which is our distributed application scheduler. If you’re familiar with Kubernetes or Mesos, it lives in that same space there.
[08:04] And it’s very interesting, because Vault obviously targets more of the security space, Consul targets more of the operations, Vagrant is more in the developer space… So we span this very horizontal line across most organizations.
Yeah. I’m a big fan of the work you’ve done. It’s kind of interesting too to think that you were first known as the company that created Vagrant, which was essentially the claim to fame, but since then you’ve obviously [unintelligible 00:08:29.03], as you mentioned, in this horizontal way… All these tools that really help developers be a lot better at what they do in terms of DevOps and provisioning servers, managing cluster and all that fun stuff, and now obviously into this more of a security space.
Anything else we should mention about your back-story before we kind of dive into a bit more of the details around Vault and the fun stuff that you’re doing over there?
No, I think that pretty much covers it. I’m Seth Vargo on the internet, so if you need to find anything more about me, it’s all over the place.
The only question I’d like to really know about before we move away from your personal story is what was your a-ha moment? What was it that made you fall in love with this piece? You mentioned CMU, the information systems program there and then touching open source… This show has always been about lifting up and shining a light into areas of open source that don’t get enough recognition and thought process put around, and I’m just kind of curious what it was that hooked you.
That’s always a tough question. I think seeing how people interact in open source is always more exciting to me than the code being open. I think there’s two definitions of open source - there’s the puritan Britannica definition, which is “the code that’s publicly available.” To me, I don’t consider that open source; I consider that freely available code that has a license. I think what makes open source open source is the community that surrounds it. It’s the issues on GitHub or GitLab, the engagement with the authors and the people who are writing these tools and using them on a day-to-day basis and contributing features back, and that’s really what keeps me in the game.
Anybody can write code and put it on the internet, but what makes the community and what makes an open source project successful is the engagement from the engineers and the people who are working on it all the time. The community is a vital part of any open source project. If you don’t have a community, it’s not really an open source project, in my opinion. I think that’s what keeps me going - all of these people who get paid by another company or they’re doing this in their spare time because it’s interesting to them… That’s awesome to me - the inspiration that you can put into other people just by making an open source project and building a community around it.
Yeah, I totally agree with that. We produce another show called Request For Commits - you can find that at rfc.fm… It’s about 11-ish episodes in, 12 if you count the behind the scenes look at that, and that show there is definitely a humanized look at the way open source operates. It’s beyond the code, it’s not simply about the code; it’s about the people, it’s about the businesses that get propped up beside and around, as HashiCorp has done over their open source, and how you actually create a sustainable ecosystem of communities and people and software and the fun things people can build because of it.
I totally agree with you on that being what sticks you in there, what keeps you in the game, as you said. What keeps me in the game is the people; I love that. You are self-professed as being automation-obsessed; that’s in your own words of course, because you say that on your awesome website, which is sethvargo.com. But you work at HashiCorp in the advocacy position, so you get to go out and talk quite a bit about Vault. Before we go into the first break, give us the elevator pitch to Vault; let’s get an understanding of what we’re talking about here before we dive deep into what it is.
[11:56] Sure. Vault is a tool for managing secrets, which is a really broad definition, because…
What’s a secret, right?
Yeah, and a Notepad app also manages secrets.
Right, but not very well.
I have some sticky notes in front of me too, and I can put them in a folder and they’re also managing secrets… It’s a tool that operates in a server/client model. So there’s a centralized server that securely manages not only the storage of secrets, but also the distribution. I’d just like to give a really concrete example that separates Vault from most other tools on the market. If I need a database password - I need to talk to Postgres, or Cassandra, or MySQL or something, the way that you normally do that is you google “How do I make a MySQL user”, you copy and paste some code from Stack Overflow and then you put that in a text file or save it somewhere in a password manager.
There’s a lot of problems with that in that you’re copying random code from the internet, and there’s a human seeing this password that’s actually for an application, it gets reused over and over again… What Vault does is it abstracts away that process. Vault actually has the ability to make an API call to those databases that I mentioned before and generate that user programmatically. Then, as a human or a machine, I just ask Vault for a MySQL credential; it handles all of the authentication authorization for me and just gives me back a username and password to connect to the database.
So it really changes the way we generate credentials, and also it puts a lifetime on them. If you’re familiar with DNS or DHCP, when you get an IP address, that IP address has a TTL associated with it. You don’t get to keep that forever; the DHCP server says, “Here, you can have this IP for eight days.” After eight days, you have to tell the DHCP server, “Hey, I’m still using this IP” or else it will get recycled and assigned to another client; it gets added back to the pool.
Vault behaves very similarly, but with secrets. So you don’t have these credentials that live on forever. They have a lifetime, and Vault manages that lifetime, which reduces the surface area for an attack.
Yeah. That certainly tees up the conversation to be had, for sure. I love that overarching view, especially the use case examples there. Let’s pause here; we’ll take a break and when we come back we’ll dive deeper into the details of Vault and we’ll have some fun. We’ll be right back.
[14:13] to [\00:15:04.11]
Alright, we’re back with Seth and we’re talking about Vault. Managing secrets - you mentioned that you can keep a secret in Notepad, you can keep a secret in any plain text file, but that doesn’t mean it’s actually secure. Obviously, if it’s a secret, you wanna keep it secure; you wanna make sure that you can manage who has access to it, manage how often they have access to it, whether or not that access is revoked…
I guess what I’m asking here in this overarching theme here of this tool is what other things out there do this? You’ve got consumer-based applications like OnePassword… I know for us here at Changelog we use LastPass; there’s also KeyPass and several other things that are actually baked into tools like Chef and what not. So what was the problem that you all faced at HashiCorp to make you even think, “Well, we should make Vault”?
[15:51] Yeah, that’s a great question. If you look at consumer-facing products - things you’ve mentioned: OnePassword, KeyPass, LastPass… We don’t actually view those as competitors to Vault.
They certainly help frame the conversation though, because people use those every day.
Exactly, so I think it’s helpful to try to understand where do we draw that line. Vault is designed for the systems’ side of things - computers, databases, machines, engineers. Your tools like OnePassword and LastPass are still very useful at an organizational level. We don’t expect people in the finance department or the marketing department to have to understand how to authenticate the vault so that they can get a Photoshop API key, or something like that. That use case still belongs in password managers. Particularly, any kind of shared password that’s not related to infrastructure belongs in a password manager - things like Wi-Fi passwords and things like that should probably be in the password manager where they’re more easily accessible. Those tools have graphical user interfaces and mobile applications where you can very quickly search and access those secrets. That’s not really Vault’s target.
Then you take the flipside of that - things like Chef and Puppet have these notions of like encrypted (Chef calls them) data-bags, which are like encrypted JSON files and they’re for storing database passwords or API keys that get dropped onto a system, so that that machine or application can communicate with other machines or applications or third party services. That’s really where Vault’s target market is.
The difference between Vault and the existing solutions out there is those solutions are great, but they just do encryption. They rely on a human to go create a credential and put it in a text file and run the encryption process to generate it and then commit it somewhere or save it somewhere, and then they rely on the machines to decrypt it… Whereas Vault tries to eliminate that human aspect as much as possible. By being an HTTP API server - so everything’s an API, everything’s just one curl call away, as I like to say - applications and machines can request credentials without human intervention. After the Vault is configured, we don’t have to rely on humans to provision these machines and provision all of these secrets that go across them.
The additional advantage there is every instance of an application - say you have a typical blog that has three frontend instances that are fronted by a load balancer, they can each have their own backend database password, because they programmatically generate that at boot time or runtime. So if an attacker is able to somehow compromise one of those instances, we can revoke exactly one of those credentials and not affect the other two instances, not cause downtime for the people who are trying to come to the blog.
Additionally, because there is this one-to-one relationship, if you’re familiar with ERD as in database modeling, we have a one-to-one relationship between credentials in Vault and the requester, the thing that created it. We have this notion of provenance, which allows us to say, “Okay, this instance of a machine is compromised. We’re just going to revoke every credential that that machine had access to.” As a result, nothing else is affected in the system. That’s only enabled by the fact that these are dynamically generated and there’s really minimal human involvement. Machine-to-machine communication is very important in Vault, and that’s ultimately what we’re doing - we’re reducing the human interaction by adding automation and technology, but it’s the same process… The same way that you would log into Postgres and type commands to generate a user, Vault is doing that at an API layer. So it’s still performing those same operations, but it’s doing so and it’s fronting that with an HTTP API server, so you can automate a lot of these things that would normally be manual processes.
It’s written in Go, which is an interesting thing. Obviously, I mentioned GoTime; Go is a phenomenal language and I think HashiCorp is kind of centered around it. I think it began mostly in the Ruby space with Vagrant, but has kind of curbed into Go. Why is Go a language that makes this kind of tool what it is?
[19:57] Definitely a great question. Almost all of our tools, with the exception of Vagrant, are written in Go. The reason Go is a great choice for a tool like Vault is the concurrency model. As I said before, Vault is a client-server relationship, so clients are making requests to Vault, so we need something that’s highly available and can handle tens of thousands of requests per second if you’re in a large enterprise setup. We get amazing performance out of Vault. We’ve done our own internal benchmarks, I’ve done my own benchmarks… I can push about 25,000 requests per second through a single Vault instance, which is insane when you think about it, considering it was running on a t2.micro on Amazon. So really great performance out of the tool.
What we also get out of it is the ability to statically compile across different architectures without the need for a complex build pipeline. I’ll explain that a little bit more. Go has native cross-compiling. What that means is you write your code - you write Ruby, you write C, you write Python - but then whenever you wanna distribute that to Windows and Mac and Linux and FreeBSD and Raspberry Pi’s and Arduinos and Android phones, you often have to have one of those to build.
I’ll take Chef as an example - when I worked at Chef, we had a very complex build pipeline where we had a Red Hat box, and a Debian box, and an Ubuntu box, because that was the only way to build packages for those systems. When we look at Go, go has this really great build toolchain where on my local Mac I can build static binaries for Windows, down to Android phone if I want to, in a single command. And it’s all on my Mac. It’s not relying on cloud services, I can do it completely without the internet… It’s actually built into the tool itself.
When you go to download Vault, you can download Vault for everything from OS X, we support all of the BSDs (FreeBSD, NetBSD, OpenBSD), Windows, Linux. We don’t personally publish the mobile stuff, but you could build it yourself from source. Go gives us this really great build toolchain where – a lot of people still run Windows and they have hybrid environments where some servers are Linux and some are Red Hat, some are Debian… Things are all over the map; it’s very rare that you walk into an organization today that has like “We are 100% the latest version of Debian.” There’s a mixture everywhere, so being able to support that without basically any overhead is really one of the great things from a post-production standpoint.
The way anyone at HashiCorp can cut a release of any tool from their local laptop - which is great, because we reduce single points of failure, we’re not relying on this huge centralized build system that has a huge backup of queues… We build stuff and we can push it out into production very fast. Most of our tools build in under 2-3 minutes, and that’s across the entire fleet, with all of the binaries ready to go. And they’re single static binaries, so you don’t have to worry about putting a whole bunch of files in place. You download it, you unpack/unarchive it and then you put it in your path and it’s ready to Go.
Let’s talk about how Vault is used. You mentioned removing the human scenario around that; you still might generate a password, but it’s stored in Vault. Can you talk to me about some of the processes that happen to secure, for example, a server, or launching a new server on Linode, or something like that, how the team operates around Vault being able to not only generate passwords and things like that, but also access them. Is it something that the developers end up using, or is it simply machine-based where it’s about automation?
That’s a great question. It’s actually horizontal across developers’ operations, security and machines. Developers need access to things like AWS, Google Cloud credentials; you need your IAM keys to be able to do stuff, and you might need access to be able to read some data from the database, so that you can see the columns and the query and do some analysis of the production database. With Vault, you configure that. The Vault administrator would configure the developer’s login to Vault - and I’ll talk about what that process of logging in means in a minute… They log into Vault, and then they can request those things that they’ve been given permission to do.
[24:16] The security team is obviously a lot focused on a higher level; they might be managing things like the TLS communication between services. If you’re in a microservices-oriented architecture and you have two internal apps that talk to each other, you want them to talk over an SSL connection, an HTTPS or a TLS connection.
Managing those certificates and making sure those certificates have really short [unintelligible 00:24:39.08] and really short lifetimes, but are also always valid, so that you can communicate between services, allows the security team to sleep at night, because it means even if an attacker is able to penetrate your outermost firewall, they can’t sniff traffic between the services, because all of the traffic between services is encrypted.
We have the operations team. They might be responsible for doing things like building images or doing maintenance, so they also need access to API keys and databases and the whole nine yards. This process of authentication or “logging into Vault” is really important, because Vault is a dynamic secret acquisition engine, but the way you dynamically acquire a secret is based off of your permissions in Vault. When you log into Vault, there are a number of ways to authenticate who you are.
Let’s just stop talking about Vault for one second. If I were to log into a website, I’d type in my username and password and I click Sign In. From there - I don’t know if most of the viewers are familiar with it, but you’re assigned a token or a session ID from that application, that website. Your browser stores that in a cookie - it might be encrypted, it might not be - and that’s how you’re identified moving forward in the system.
It would be pretty annoying if every time you went to Facebook or GitHub you had to type your username and password in, just to like a post or comment on an issue. So that’s how you get identified as you move through the system, and your browser handles that carrying of that session ID along with you, and it has an expiration. Also, you may be familiar with things like OAuth, where you might be able to sign in with Facebook, sign in with GitHub, sign in with Twitter, in which case you supply your Twitter login or your Facebook login to authenticate to a third-party application. That’s something called OmniAuth or OAuth.
Vault has a very similar process. It’s not OAuth, it’s not a traditional website login, but you can think of them metaphorically as the same. As a human, you can authenticate to Vault with GitHub; you supply a GitHub API token, an administrator at Vault configures Vault and says, “Hey, anyone who is a member of this GitHub team has these permissions in Vault.” You can say, “Anyone who’s a member of the engineers team on the GitHub organization HashiCorp has read-only access to all of the production data.” We don’t actually have that, I’m just giving you a hypothetical…
You can also say, “Anyone in the accounting team has the ability to SSH - because Vault can actually manage SSH for you - into some service that runs some accounting procedure”, or something like that. There’s also the ability to log in with a generic username and password; you can log in via Okta - I don’t know if you’re familiar with Okta… It’s a very popular enterprise Single Sign-On. RADIUS, another very popular Single Sign-On. LDAP, including Active Directory. So Vault doesn’t actually manage the authentication for you, it generally delegates the authentication to a third-party service that the Vault administrators have configured. That’s the authentication, typically called AuthN. Vault does manage the AuthZ, which I’ll talk about in a second.
[27:49] On the machine side of things, machines also need to authenticate. If any machine in the Vault cluster could just request credentials, that wouldn’t be very fruitful, so there’s a number of ways for machines to authenticate. They can authenticate via a token - maybe they’re supplied that token at boot time; there are ways for machines to authenticate on the cloud providers, so we have authentication for EC2 instances, and there are ways for applications to authenticate as well - things like app-id and app-role allow applications like your frontend web app to be able to supply information it’s given at boot time, and Vault will in turn validate that and give it back a token. You can think of it as username and password, but instead of human-friendly things it’s all UUIDs and special characters all over the place.
Long strings that are really hard to decrypt.
Yeah, very high entropy UUIDs. So those are the different ways you authenticate to Vault, but it all ends up the same. You can think of it as a big funnel that’s all going into this thing called a token. So whether you put a username and password in or you log in with GitHub or LDAP, the thing that happens is you get back a token, and that’s very similar to a session ID on a website. That token is how you authenticate moving forward in the system. You don’t ever supply your username and password again, or your GitHub login again - it’s all that token moving forward, and that token has permissions assigned to it. Vault manages those permissions based on the authorization (AuthZ) and it manages all of that internally through a really verbose policy system.
Everything in Vault is based on a policy. Just because you can authenticate to Vault doesn’t mean you’re authorized to do anything. It would be like logging into a website and the very first page you get is access denied. You were successful in logging in, but you don’t actually have permission to see anything in the system. What Vault administrators, in collaboration with the security teams do is they generate policies that map authentications to permissions in the system.
Here’s some examples before of like anyone in the engineers team can do certain things in Vault, and that’s really where Vault’s power is. Because as new people join the company, they just get added to the team on GitHub and they automatically inherit permissions for all of these things. As a new person joins – say you’re a large enterprise or a really big company that has a massive Active Director installation, and you have an employee who moves from one team to another team… All you do is change their OU in LDAP from Team1 to Team2, and automatically their permissions are updated throughout the system. They might lose permission to things they had before and gain permission to new things in the system, and that’s all handled out of band, because you’re already managing an Active Directory server that’s already part of your company culture and company technology, so we’re just integrating with those technologies to give you authorization to different resources in the system.
You mentioned that Vault doesn’t do the authentication, it’s handled externally. Is that right? So like LDAP, or in this case using a GitHub team, or a group, or something like that. Is that correct? You’re using inclusion in a certain external interface or an external application to say you can have access to Vault, if that’s part of the Vault cluster, as you mentioned.
Yeah, you can think of it as like delegating. Vault has its own internal mechanisms; username and password is internal to Vault, but for the ones that most organizations will use, the authentication is delegated to something like LDAP or GitHub. Vault makes a request to LDAP and says, “Is this username and password valid?” and LDAP says yes or no, and as a result, the data that comes back is used to map back on to the policy and permission.
It certainly makes maintaining your GitHub teams a lot more of a security issue. Using it in this mechanism… Not many people out there are probably using their GitHub teams or the groups that they have on GitHub in their organizations. They use them for groups, but it’s mostly like external, to say “who’s on our open source teams” or “Here’s who’s involved in projects, or whatever”, or having access to certain repos, of course, but… That’s obviously authentication, because you’re authenticating the certain – you’re allowing some of the access to a repo or push/commit to a repo or read/write access to a repo, for example.
But taking that one step further and using that same feature set to access a server certainly puts a lot more pressure on making sure that you manage your teams well.
[32:08] Definitely, and I’ll just plug real quick… If you’re looking for a way to manage all of your GitHub teams and the memberships of those teams and the repository permissions, one of our other open source tools - Terraform - actually has the ability to do that. In a single text file you can describe what you want your entire GitHub organization layout to be, who has permission to what repositories, what are your teams, what are your memberships, and it will actually just go out to GitHub when you run Terraform and it will figure all of that out for you and apply that in a very declarative syntax.
Terraform is fairly new, isn’t it? It’s maybe a year old, roughly?
It’s hard for me to say, because we used Terraform internally before we made it open source, so the lines between when it was public and when it wasn’t are always a little bit blurred for me. I wanna say it’s over a year old at this point. We’re quickly approaching a 1.0. It’s on 0.8 right now, and I think 0.9 is slated to come out in the next couple of weeks.
I think it’s a little bit older than that, and I know we did run a version of it internally before we made it public. It’s the same thing we do with Consul too, which is another open source tool. We tend to run these things internally a bit before we even release the 0.1 to the open source community.
This feature with GitHub though is just one of the many things it does.
Correct.
Okay. And it’s an installable application, so you’ve got access to a Mac version, FreeBSD, as you mentioned, Linux, OpenBSD, Windows - you can use it on all of those.
Yeah. All of the things in there – we don’t compile them, because as a company we don’t actually support them, but there are people who are running Vault on things like Raspberry Pi’s and Arduino boards.
Certainly you’ve gotta go back and listen to the episode we just recently published - I think I mentioned it in the pre-show… It was episode #237 - secure software. That would certainly apply there, because if you’re using it on a Raspberry Pi, you might wanna make sure that it’s a reproducible build from the original Terraform source code. Enough of a little tangent there… Certainly we’ll link up Terraform in the show notes.
Getting back to Vault, I’m kind of curious… You mentioned that this tool is for developers, for machines, it’s for the security personnel that are securing microservices or [unintelligible 00:34:17.22] I’m curious about the interface. From what I can tell so far, it’s mainly a command line GUI, or sort of like focused on a developer point of view. What’s the current state of like an interface engine? I know you have an API for machines, obviously, but what’s the common way for people to work with Vault and manage machine clusters, credentials, manage and revoke access - how does that work primarily? What’s the GUI for that? What’s the interface for that?
The primary interface for the open source tool is the command line in the API. The command line itself is actually just a very thin wrapper around the API; it’s just gonna do some basic text formatting and some parsing of the output and error handling for you. HashiCorp are an open source company, so we have to make money somehow; one of the ways we make money is offering these enterprise product versions and professional product versions.
Vault Pro (Vault Professional) and Vault Enterprise include a web-based user interface where you can list secrets, insert secrets, generate credentials, interact with the various secret backends (I mentioned MySQL and Postgres) and kind of visualize the cluster. It all uses the open source API, so there’s nothing that really stops you from that internally, but…
Why would you, right?
Yeah, that’s one of the things that we offer as a paid product, to help us fund the work we do in open source.
That’s cool, it’s like Vault++. If you’ve used Vault in its open sourced state where you’re primarily focused on a command line GUI for interfacing with Vault, accessing and revoking machines and passwords and key phrases and all that stuff, but you wanna go one step further to a web GUI or even further to something that supports better enterprise scenarios. That’s HashiCorp’s business model, right? That’s what Vagrant was built on - it was built on this open source tool that then I think Mitchell got a call from VMware; he wanted to do something with VMware and you’re like, “Well, that’s something I can actually release as AP plugin or something like that and actually make money from it, so I can sustain this and build this.” If he hadn’t made that choice or learned that early on in the early days of HashiCorp, then we wouldn’t be talking right now about Vault.
[36:31] Exactly. If you look at the market, there’s two open source business models that are popular. First is what we do at HashiCorp, which is open core - we build as much as we can in the open source community, and then the features that we think appeal to enterprise markets are enterprise features. The other is the paid support model, where everything is open source, but you have to pay for support anytime you want help. I’ve seen this pattern emerge a number of times. We had conversations internally where it’s like, “Okay, that kind of works, but it actually encourages you to make software that’s difficult to use”, because your entire baseline is based off of the fact that people need help.
One of the things we get praised for a lot in the community is how good our documentation is and how thorough it is, and I feel like if we had taken the support model… You’re almost de-incentivized to make good documentation, because you need people to reach out to you to buy support contracts to fund your work.
Yeah, because if you’re doing good docs, then why would they call you or need your help?
Exactly. So what we do for Vault Enterprise is if you need a UI, if you want a fool-proof backup and restore strategy, if you want integration, you want the 24/7 SLA, you want integration with a hardware security module - all of that is what we consider an “enterprise” feature. Everything else is open source; everything I’ve talked about is open source, and there’s a ton of other features that are available straight up in the open source offering. You don’t even have to give us your email to download it. The code’s on GitHub, you can download the compiled binary straight from the website.
I love the idea of open core. I think I’ve heard that term before, but for some reason it’s blaring at me right now, this idea of open core. Now, having this conversation with you and having the history that we have with what is now HashiCorp, [unintelligible 00:38:19.10] to some degree your company and your open source offerings over the years, and knowing that there’s a base part of each product you deliver that has an open core availability that doesn’t require them to give you an email address to access it; it’s open source, they can contribute, they can list PRs, star it and watch on GitHub and participate and give feedback… That’s an interesting concept. How much have you all talked about this idea of open core? Is this something new I’ve just finally heard about, or is this something you guys have coined?
We’ve thrown that term around a lot. I’m not sure who coined it or where it came from, but it’s really ingrained in our principles. We have this thing called the Tao of HashiCorp, which lists the seven pillars of the company. Open source is one of the things we build, it’s why we’re here; the community, the contributors - it’s the reason we’re here. It is a core pillar of HashiCorp as a company, and we wouldn’t be here without it.
I think more and more we’re seeing traditional software vendors, like Microsoft even, starting to embrace this more open core model, because that’s what organizations are looking for. Like I said before, open source isn’t just the code, it’s the people, and I think larger organizations are slowly starting to realize that by betting on open source not only do you have free access to the code, but you’re also betting on highly available engineers, you’re betting on people who like to engage with you, as opposed to people who are forced to work in a support queue and they want nothing to do with you. You get faster bug fixes, higher prioritization, you get to see the roadmap, it’s very public; all of the work is being done out in the open, and I think that’s what’s most exciting to me.
Yeah, there’s certainly something about the open source way, so to speak. As you mentioned, it is very much focused on the people of the code, not so much just the code itself, and applying those principles to lots of different things - doing things in the open, doing things with transparency, inclusiveness, including people in the process, even if they’re not part of the inside team or a co-founder of the company or the fourth person to join the company to make it what it is today… They still have – maybe not the same level of a voice, but they still have a voice in the future and where things go. To me, that’s a fantastic recipe that obviously gets results, which is why open source is eating the world.
[40:43] Let’s curveball back into the subject of Vault. I wanna go over some of the key features - you’ve got secure secret storage, that’s one of the features; I wanna go through each of these features and kind of break some of them down. That makes sense, so stop me wherever you need to. Secure secret storage, dynamic secrets, data encryption. We talked a bit about some of these, lease, renew and revocation, where you can actually revoke a secret or access to something, as we’ve talked about before. What I’m really interested in is 1) it stores some secrets, but then it can also actually encrypt data and store it elsewhere. Can we talk about that one a bit, or should we go in order, do you think, to these features?
Yeah, we can definitely chat about that first.
That one seems to stand out most to me, because it seems like – you know, you mentioned earlier the human element, which is why I thought that feature would be first to talk about, even though it’s out of order, is because I can take this key and throw it through an encryption and then put it on the server and then Vault is managing it. But in this case, it’s actually [unintelligible 00:41:43.07] encryption for you too, so it’s probably making some wise choices for you on which algorithm to use, which are less likely to get hacked recently or decrypted… So maybe that’s a good place to start.
Definitely. In terms of the storage, all of the data in Vault is encrypted with 256-bit AES CBC encryption in transit and at rest. We rely on the TLS SSL on the front, and then all of the data is encrypted. When it’s written to the file system or wherever you’re persisting the data, the durable storage, that’s where all the static data is written.
Vault also has this backend - you can think of a backend as like a secret plugin. It’s a plugin that either generates secrets or stores them. One of those backends is called Transit. The reason it’s called Transit is that it provides encryption in transit. You can think of the piece of data as kind of moving on a vehicle through an encryption pipeline, and it comes out encrypted on the other end. It’s still the same vehicle, it’s just in a different format, and that’s why we call it Transit.
The difference between, say, like the generic secret backend, where you just store data in Vault - you say, “Hey Vault, here’s password 12345. Please save this for me”, and the transit backend is where the data lives. When you give Vault a generic secret, it encrypts it and stores it in its own backend. When you use the Transit encryption service, what you’re really getting is Encryption as a Service. You’re giving Vault plain text values and Vault gives you back encrypted data, never storing any of that data. So this is really great if you have large things, like PDFs, or large volumes of things, like multiple rows in a database where you’re encrypting social security numbers or passports or credit cards, and you want to encrypt that data but you don’t want it stored anywhere; you actually wanna encrypt it and store it right back in the database. Then, whenever you wanna decrypt that data you give it back to Vault, Vault makes sure that you’re authorized and authenticated to be able to decrypt that data, and then decrypts you and gives you back the plain text value. All of this happens in transit, so none of that data is ever stored on the Vault server.
If you’re familiar with any of the major cloud providers, like Amazon, Google, Azure, they all have this notion of like a key management service, where they will provide Encryption as a Service for you. Vault does that with a ton of additional features, not to mention all of the other secret backends, like the dynamic secret acquisition from Postgres and MySQL that we talked about earlier.
[44:17] The advantage of using the Transit backend is that it has built-in support for key rotation, automatic key upgrading, and the ability to specify a list of cipher suites that you want. So by default, when you post something to a particular endpoint in the Transit backend in Vault, it will generate an encryption key, very high entropy… Vault has been audited a number of times by different agencies, so we know it’s cryptographically secure. It’ll generate a high entropy key, it will manage that key for you, never disclosing it to the application. So even if an attacker is able to compromise your database, for example, they don’t have the encryption key; they have to compromise Vault in order to get that encryption key, and it’s actually possible to tell Vault to never divulge that encryption key. It just doesn’t ever give it away.
If you’re FIPS compliant or HIPAA compliant or any of the PCI compliances out there, you have to rotate encryption keys on a regular basis; I think every three months is the minimum. You have to be able to prove that you’ve rotated them, you have to be able to prove that you’ve upgraded and audited the data upgrade. And the Transit backend has built-in support for all of this, and it just does it automatically with one API call. If you’re ready to rotate, you just rotate the key and Vault does an automatic, completely online upgrade. As new data comes in, it uses the new key. Any old data that’s decrypted, it decrypts it with the old key and re-encrypts it with the new key when you get it back.
Then there’s a built-in process for re-encrypting all of the data, we call it re-wrapping. If you wanna force upgrade all of the keys to the newest version, you can run one command and give it all of the data you want to re-encrypt, and it will give you back the new encrypted data. So it really supports this really broad set of features that allow you to do what we call Encryption as a Service.
Instead of rolling your own encryption and getting the cipher suite and everything right, we’ve done all of that heavy lifting and we give you an API. All you do is give data to the API and it gives you a response back. Very similar to how you’d interact with the GitHub API, or the Facebook graph API. It’s just a JSON request and a JSON response. In terms of the integrations, there are client libraries that exist for Ruby, Python, Node, Go… All of the major programming languages have the ability to interact with Vault. And if they don’t, it’s just an HTTP request; you can [unintelligible 00:46:37.01] or do whatever you need to do to make that HTTP request.
It seems like this tool is really unified, no matter what angle you need to store secrets - whether you’re the developer, whether you’re the machine, whether you’re on the security team and you need to do things like revocation and stuff like that… It seems to me like you’ve built this perfect tool for literally managing secrets and being able to scale - if you need to move beyond the open source tool, then you can; you have other options, like the pro version, the enterprise version that you can upgrade to. It seems like this is the best unified way to encrypt, and then actually authenticate or get access to certain service or certain databases, or encrypt data, things like that.
Is there anything else out there like this? I know it’s built into other tools, but this one, unified way, as you’d mentioned, this tool has been audited by external agencies to confirm its security. Is there anything else out there like this?
[47:40] We haven’t been able to find one. I guess one of the things that’s important to mention is that at HashiCorp we build solutions. We’re builders, we’re engineers at heart, so when we identify a problem, we have the problem, too. One of the reasons we built Vault is because one of our enterprise offerings involves you giving us cloud credentials, like Amazon keys and Linode keys. So if you give us cloud credentials, we have to have a really good way and a really good promise that they’re secure. That was kind of how Vault started coming up, and we did a huge exploration of the space.
You’re right, there are tools that do some of this, but Vault’s goal and its tagline is “A tool for managing secrets” and it’s intentionally very generic, because Vault’s surface area is effectively infinite. If it has an API to generate secrets, Vault can generate secrets for it. That’s really what we’re shooting for - it should be the one-stop-shop for secrets in your organization. It doesn’t matter how big or small you are - if you’re a 2-3 person startup, Vault can help you. If you’re a massive enterprise, Vault can help you, too. You might be using different pieces, different components, different backends, different plugins, but ultimately the goal is the same - you want this centralized tool to manage credentials and secrets for you. By putting everything in the centralized system, you reduce secret sprawl, you reduce the attack surface… If you’re in a situation where you have an intruder in your network or someone’s downloading your database, you have separation of concerns for all of this data and you can quickly revoke things in the event that a system is compromised.
That’s what’s great… The corollary to that - I’m sure there are a lot of listeners who do work at a startup or medium-sized companies, and I’d just like to throw out this hypothetical question, which is “How many of you have a production credential on your local laptop right now?” I know some of you might be driving in a car…
My hand’s up. It’s actually an old server, but it’s still – I’ve done it before.
Exactly, I’ve done it, too. I’m not pointing the finger by any means.
…and it’s in a plain text file. [laughter] It’s actually in a markdown file, because it was instructions back to me on how to get access… So I just told whomever could circumvent my computer and get access to it how to get access to my stuff.
Exactly, and that’s super common. I’m definitely not pointing the finger, I’ve done it… But what Vault does is when you adopt Vault early on - again, it’s open source, so there’s basically zero risk in doing so - you eliminate that, because the secrets have a lifetime, so if you’re not using it, it’s gonna expire, at which point, so what? It’s on your laptop, but it’s not valid anymore… But also, you have this centralized source of an audit log, so you can see which credential is being used for what, and where, and how, and you can try to understand what the rollout effect is - “If I revoke this credential, what happens? What breaks in the system? What services are depending on this?”, and that’s really important.
The other thing I ask is every once in a while you have people who are like, “Nope, no production credentials on my laptop.” Then I say, “Well, can you clone the production application from GitHub or GitLab? Can you download production code and can you commit production code?” Like, “Yeah, I have an SSH key.” I’m like, “Isn’t that a production credential then?” They’re like, “Oh, it’s just for GitHub.” But you have access to code that runs in production, so you have a production credential, and Vault can manage that, too. Vault manages SSH keys, it can manage the whole lifecycle there, and that’s what’s really awesome. It is truly the one-stop-shop for secrets, and it doesn’t matter whether you’re a massive enterprise or a tiny little startup.
That’s definitely a good place to pause, because when we come back from this break I wanna get into those first steps - getting started; maybe the smaller teams are just rolling out what you might prescribe as a good initial rollout as a test… So let’s take this break and when we come back we’ll dive into that and we’ll go from there. We’ll be right back.
[51:31] to [\00:54:10.08]
Alright, we’re back with Seth and we’re talking about Vault, and a more important subject here, which is like they’ve seen the light, they understand that they’ve got production credentials, they’ve got unsecure passwords on their local laptops - I’m talking to the developers out there - they’ve got these things and they’re realizing, “Man, I’m in an unsecure situation with my startup, my business, my employer… We are at risk.” And here comes Vault. We’ve talked about all the different features of it that truly make sense, and they can scale with you if you needed to scale, from pro to enterprise.
But maybe the first question is getting started. What are some of the first steps that a small team or an intro team can take to begin to use Vault? Where are the first steps best to take?
Yeah, definitely a great question. Let’s say you’re skeptical; I’m on the show, I’m trying to get you to use this open source project, but I’m basically a salesperson.
You’re pretty sketchy.
Yeah, you know… I do some sketch diagrams, I have some hanging on the wall. But you know, let’s say you’re not buying what I’m saying, and you wanna try it out for yourself. Zero risk, you can launch an in-the-cloud Vault environment with an interactive tutorial right from Vault’s website.
VaultProject.io - there’s a big ol’ button, really hard to miss, it says “Launch Interactive Tutorial.” If you’re not driving, you can actually pull out your phone and do it now, it works on mobile. It will walk you through some really common Vault commands, and it actually launches your own Vault instance in the background. HashiCorp funds that, so that people can try out Vault zero risk, no installation; all you need is a modern browser with some JavaScript enabled.
Once you’ve bought into the idea - because you will fall in love with it, trust me - the next thing you wanna do is actually download it. Before you put it in production, you’re gonna wanna download it locally.
[55:51] I run it on a Mac locally; I know that’s very common for software engineers. So you can head on over to that same website, VaultProject.io, download the Mac binary - you’re gonna want the 64-bit one, because if you have a 32-bit Mac I feel bad for you.
Download the 64-bit one. That’s gonna give you a single static binary that you can run, it’s just a Vault. That single static binary is the client and the server - it can run as the client, or the server, or both. If you wanna ever try something out locally - and I still do this myself; there are times when I forget an API or I wanna see what a response is - most of our tools have this thing called -dev flag (dev is short for development). So locally you can just spin up a Vault server by running vault server -dev. That will give you a fully ready to go, ready to accept request Vault server that you can do some sample commands against. The same thing that you are running in the cloud, but it’s all local on your laptop. And you can really abuse that; you can do a lot more to that than you can do to the cloud instance. You can [unintelligible 00:56:45.26] around with different configuration, you can see all the different log output.
Then, once you’re satisfied with that, you’re ready to put it in production. From there, there’s actually a number of techniques. You have to make a few decisions. If you’re a tiny startup, it might be best just o start with a single Vault instance. Don’t worry about high availability, especially if this is a beta test. Just get it in production, make sure you’re comfortable using it. It’s senseless to invest a ton of time and energy into a tool that you’re not a hundred percent sold on yet. If you’re in a cloud environment or bare metal, spin up a server, use your automation tooling (Chef, Puppet, Bash) typing things in the terminal, and install it.
The tools are really easy to install. We have a server called the HashiCorp Releases Service; if you head on over to releases.hashicorp.com, you can browse any version of any product we’ve ever published and you can download it right to a machine. It’s a single static binary, the same that you downloaded for your Mac earlier. So you put it on the server and then you run it. Maybe you use SystemD or init, or Upstart or whatever your init system is. You have it running on the system, and from there you can hit it publicly. You might give it a public IP or put it within your private subnet, and you can start addressing it from other applications and really see how it behaves. Give it a trial, but you’re not ready to invest yet. You’re just kind of really feeling the waters out in a production or a staging environment.
Once you’re sold on it, you’re gonna wanna automate the process of standing up a Vault cluster, and you’re gonna wanna move to a highly available environment. And again, this is all completely open source, so you don’t need to pay for Pro to have high availability. High availability is built right into Vault. What you do is you spin up multiple Vault clusters, and Terraform is a great tool for doing this. You spin up these Vault servers, you connect them to each other; they all talk to each other, they do a leader election algorithm, one of them gets the leader, the other one goes into standby mode, and from there you can make requests against Vault. If one of those servers goes down - there’s an outage, or someone pulls the plug or it just dies, the other two will pick up the work. So you run in that high availability mode, which is something that’s really important, as this becomes a crucial piece of the secret management, the credential management in the organization.
So that’s the best way to get started. That’s my recommended path. You should try it on the internet before you download it, you should download it locally before you put it on a staging server, and then once you’re ready into production, we have a couple guides that published that are kind of like best architecture practices.
Once it’s running in the staging environment - that step before production - I think it’s important that the organization takes a step back and thinks about “How are we gonna manage this thing? Who’s gonna be responsible for it? Who’s gonna be setting up a policy? What’s the backup strategy?” Because that’s ultimately gonna be important. Systems fail, it happens all the time, so “How do we plan for that? What’s our recovery strategy?”
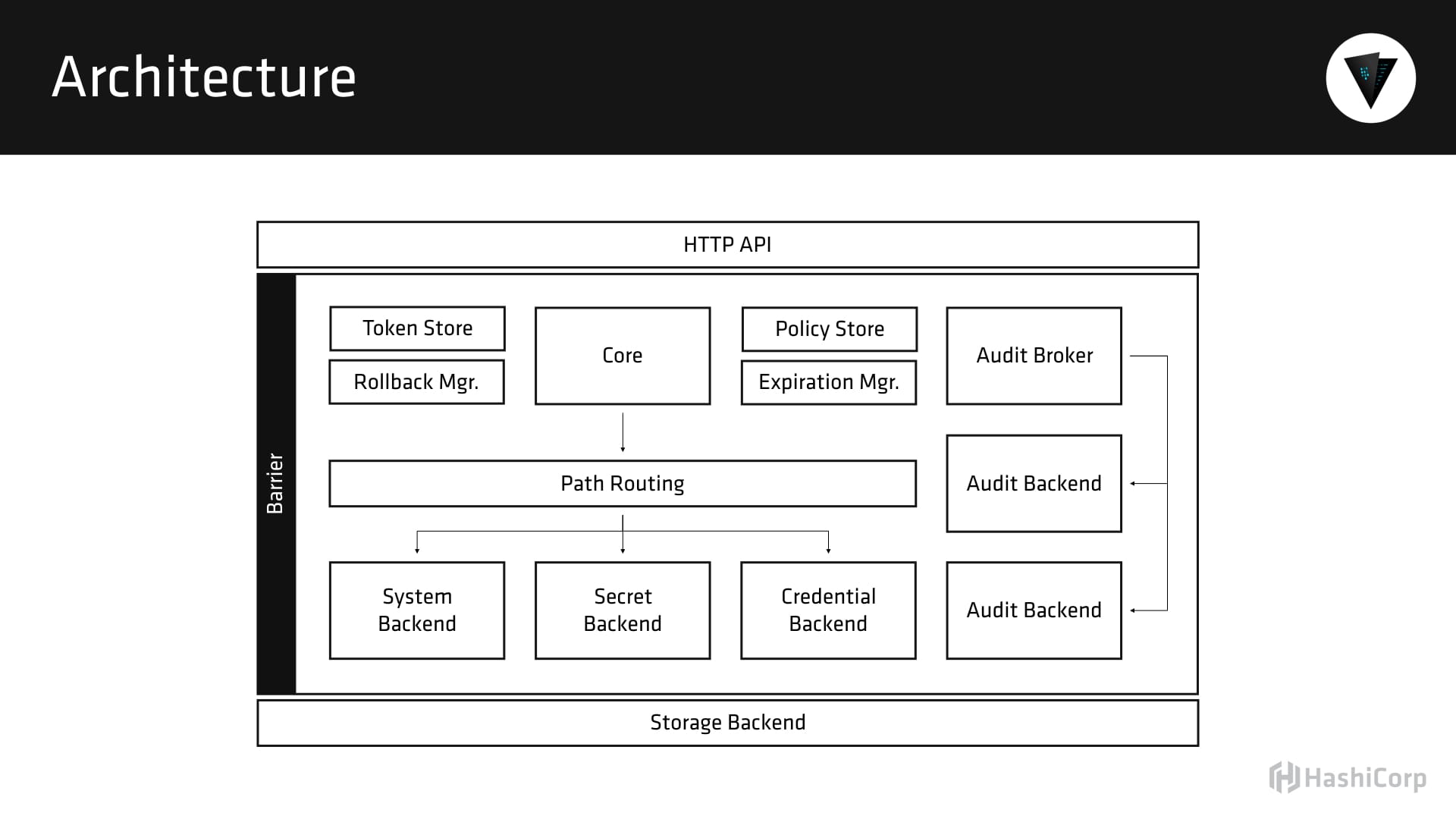
Vault’s internals are also gonna become important at that point. I’ve talked a lot about it here on the podcast, but we have a whole section of the documentation online that’s devoted to Vault’s internals - the architecture, the high availability model, the security model, the threat model, how you do telemetry; are you pushing things into Graphite and monitoring? The process of key rotation, online upgrades, the whole nine years - those are things that whoever is responsible for managing the Vault cluster, they’re gonna wanna familiarize themselves with those things before you move into a production scenario.
Those are details that if you are just getting started, you don’t need. You can read them if you want to, but they’re kind of dry, they’re very academic in nature, but they are crucial if you’re gonna run this in production. You should really understand the internals and the architecture and how it’s working, so that if something does go wrong, you have a better picture of how information is flowing through this system.
[01:00:17.00] This is certainly standing on the shoulders of the security giants. To me, it seems like hearing you share the getting started story and best practices and paths to getting it into a staging environment, testing it and then putting the right person in place to do these things, and obviously all the documentation available to someone for Vault is like, you’ve done all the thinking about how best to secure infrastructure and how best to revoke and provide access to that infrastructure. To me, that’s like – you can’t put value on that. That’s immensely valuable. But I do have one question for you that I thought was kind of a ha-ha thing, so take it like that.
When I was playing with the interactive tool at VaultProject.io as you mentioned, it told me that I couldn’t access my Vault unless I had the key1, which I believe that is that initial root token. So if I lost key1, I could not unseal, as the terminology is. I wanted to talk a little bit about lexicon, so remind me about that if we forget. But if I lost key1, where do I store key1 to get access to Vault? Do I store that somewhere else, like OnePassword, or where do I keep these keys at to be able to unseal my Vault?
Okay, that brings up a bit of a broader topic, so I have to take a step back for a second. We talked about these things called tokens, and those tokens are not what you’re talking about. What you’re talking about right now is this thing called an unseal key. When Vault is started - aside from that development mode that I mentioned earlier - it comes up in what is called an uninitialized and sealed state. Initialization is easy to describe; that’s just the process of preparing the storage backend. So if I’m storing my data in the file system, initialization is the process by which we do [unintelligible 01:02:08.10] to set up the file system to actually receive the encrypted data.
Sealing and unsealing is a little bit more challenging to explain. One of the pillars/principles of Vault is that no one person has complete access of the system. The reason that’s challenging is if you think about a physical bank vault - you walk into your bank around the corner, and whoever has the key to the vault can go inside and take money out. If you go to a larger bank, sometimes the manager and another employee both have to insert their key and turn them at the same time in order to open the vault.
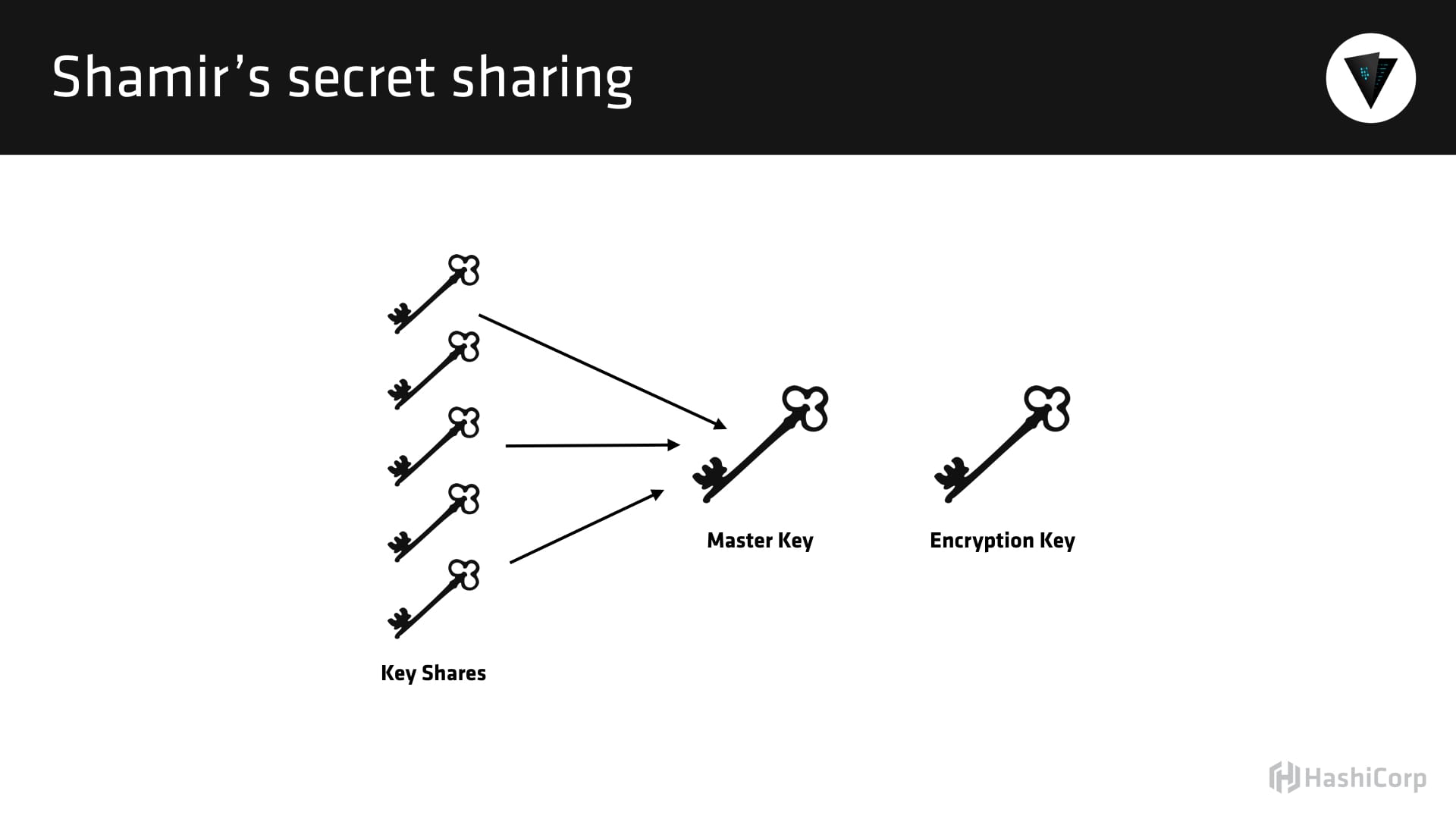
We took that principle a step further, did a lot of research and we discovered this thing called Shamir’s Secret Sharing algorithm, which is actually borrowed from mathematics. We can link to this in the show notes for those who are more interested. Shamir’s Secret Sharing algorithm allows you to generate a key - a string, let’s say, for easy argument, and split that string into a number of parts. So if I took a string and I cut it into five pieces, I could distribute that string to five people, such that those five people can come back together and regenerate the string. That’s easy; we can model that in our head… If I take a string and I give it to five people, they can come together in the same order and generate that string.
What Shamir’s Secret Sharing algorithm does is it allows us to take that a step further, and it says, “Okay, let’s cut this string into five pieces”, but mathematically any three of them can come together in any order to regenerate that same holistic string. It’s kind of hard to think about it in the physical world. I can’t take a string, cut it into five pieces and then regenerate that same string. But mathematically, it’s possible, where we can take a string, we can split it into sub-strings, give it out to a certain number of people, configurable - we’ll call that N, which is the number of people/shares. Then we have this thing called a threshold, which is the minimum required to come back together. We’ll call that T, which is the minimum that have to regenerate that original key.
[01:04:09.29] All of that is a bunch of background into explaining, when Vault starts up, there’s two keys. There’s the encryption key, which is what the data is actually encrypted with, and that supports rotation, and the whole nine yards. Then there’s this thing called the master key. The master key is what encrypts the encryption key, because the encryption key lives on disk, but it can’t be encrypted with itself - that would be senseless - so instead it’s encrypted with the master key. That master key never actually exists beyond memory. So when the Vault is initialized, the master key is created and it’s split out into a configurable number of shares. Those shares are then distributed to people in the organization, and they have to come together to generate that master key so that they can decrypt the encryption key in order to unseal the vault.
So it’s a little bit complicated, and I can share a graphic that we might be able to link to in the show notes that makes this a little bit clearer, but we have the separation of concerns, where no one person has complete access to this system. So in order to unseal the vault, which is just a one-time operation whenever the vault first boots, it remains unsealed, unless it dies or someone comes along and seals it. We need more than one person to come along and put their unseal key in… Kind of like we need more than one person at the bank to insert their key to unseal the vault, we need more than one person to supply their key to unseal the Vault.
Gotcha.
That prevents one employee from going totally rogue. So if you have a bad employee who just wants to disclose all of your information, you can seal the Vault, which is what we call the “break glass procedure” (In case of emergency, break the glass). But if that one person could just unseal the vault, that would be senseless. So we rely on this system of checks and balances, where multiple people have to interact with the system to perform these really sensitive operations, and that’s based on that Shamir’s Secret Sharing algorithm; I used five and three as an example, because those are the default numbers, but they’re totally customizable. We have some companies that do upwards of 20 key shares. Both the number of key shares and the threshold of people who have to come together are configurable.
So that step there of unsealing it - I believe it’s step three in this interactive demo… It was just kind of scary language, like “Vault does not store the master key” as you mentioned, without at least one key, which is they give you the key1 - it’s one single key, because that’s what you said to do in the init process, which was “How many key shares you said equals one in this demo?” You could have said five or three, as you mentioned in your example there, but it was kind of scary when it said, “Your Vault remained permanently sealed.” I was just thinking, “Where do I keep these keys?” Sure, I can break them up into shares and give you one, give Jerod one, give other people one that maybe are part of my organization, to have access to Vault, to seal or unseal it. But I was thinking, so this primary key, since in this case in the init process was just one single share - there’s only one key, so where do I keep that?
Yeah, that’s a great question.
Because you don’t want me to put it in that .md file I told you about earlier, with the instructions I had to unseal and seal Vault, right? You want me to put that somewhere more safe. So that was really meant to be a ha-ha thing, but it was a great, complex, deep example, which I think was very valuable… But I was really meaning it to be a slight joke, but you didn’t laugh that much
No, most definitely a sticky note… Definitely the place where you [unintelligible 01:07:25.14]
Sticky note for sure, right?
I mean, I do think that’s a good question… It really depends on the size of your tinfoil hat. Those of you that aren’t familiar with it – people who are really security-conscious are often referred to as tin foil hats, because the government can read their thoughts otherwise.
Right.
So there are some people who are very security conscious who actually print out that key on a physical piece of paper and place it in a physical safe.
Wow.
[01:07:53.07] The justification there is like, if an EMP came by, it would destroy that key and then they wouldn’t be able to help contribute to an unsealing process. Other people are like, “I’m gonna put it on a thumb drive, so it’s on a completely separate medium”, or on something like a Yubikey. That’s personally what two people at HashiCorp do - they mount an encrypted DMG volume on a thumb drive that they bring with them to places, but they only plug it into their laptop whenever they need to get their unseal key.
Me personally, I have GPG-encrypted my own seal key and I store the GPG encrypted version in OnePassword. So we use OnePassword internally at HashiCorp, because as I said earlier at the beginning of the show, they’re really different targets. I stole my unseal key, the GPG encrypted version in OnePassword. My GPG key is not stored in OnePassword, so an attacker would have to compromise my entire laptop, OnePassword servers and my GPG key in order to get my unseal key, at which point it’s one unseal key. Even if an attacker gets an unseal key, they have to have a quorum of them; they have to meet that threshold in order to do any damage in the system, and that threshold internally at HashiCorp is rather high. So the risk value is low; it’s still there, obviously… There’s still risk value of the physical safe, too. Someone could rip it out of the wall.
You’re never truly secure, it’s just measures of security… Layers of security, so to speak.
It’s all onions, and that’s where Vault is different - in Vault, we treat security as the onion layer, the whole nine yards, but also there’s a lifetime associated with it. Because if you give someone ten years to get to the core of an onion, they’re gonna make it there. But if every 30 days or 15 hours or 30 minutes the core of that onion is changing, they’re never gonna make it on time with modern computing. And as computing evolves, we can just make our things faster, as well.
That makes a lot of sense, I love it. The seal/unseal process is simply, like you said, a break glass. Even if you do it on the init state to unseal it, so that you can put things in it, and then you’re gonna only seal it again if it’s that break glass in case of emergency in a situation where you wanna completely shut down your Vault, or stop it from interacting with the various services or whatever to essentially revoke all access to Vault, not simply just a secret you have inside of it.
Right.
Cool. So we’ll have a link to that Getting Started in the show notes. You mentioned a graphic - we’ll get that from you after this show. We might even try to actually put that into the show notes; not just link to it, but if we can actually embed it into the show notes like an image. You can put the image tag on a piece of document on the web and it shows up. We’re gonna do that, we’re gonna try our best.
#html, man.
[laughs] #html, that’s right, Seth. Seth, this is closing out - what else should we share with the audience about either yourself, HashiCorp, the future, where you guys are going, Vault, that we haven’t shared well enough in this show?
I think the only other thing I would like to mention is if you’re already a HashiCorp fan or you wanna be one, we have a number of events around the world - we call them HUGs (HashiCorp User Groups); they’re kind of our meetups. They’re sponsored by us, but they’re run by the community. There’s probably one in a town near you. If you happen to be near New York City, London or Austin… In New York City and London this year we’re hosting these things called Hashi Days; they’re one-day events where you can come hang out with the HashiCorp engineers and the people who work on these tools, the customers who are using them at large scale, and ask them questions and get answers to your things.
If you wanna come to the big shebang, HashiConf, that’s gonna be in Austin this year, and we’re gonna be announcing the dates shortly. That’s where you’re gonna hear from all the major players in the industry talking about how HashiCorp is changing the way that they’re working, and we might have a new product announcement or two.
The dates are announced, man. 18th - 20th September this year.
Yeah, nice. The dates are announced.
HashiConf.com. I don’t know if it’s actually been announced, but it’s at least on your website, so I’m trusting that.
Yeah, I think the dates for HashiConf have been announced, but we haven’t announced the dates for the HashiDays yet.
Oh, gotcha.
[01:12:06.12] Those are gonna be in New York City and London, later this year.
Listeners, if you’re listening to this, we like to make announcements [unintelligible 01:12:13.00] Changelog Weekly. If you don’t subscribe to that, you should check it out. I’m gonna encourage Seth and his team to share things like this with us so that we can share with you when HashiDays is coming around or when HashiConf has got their dates up, which they do. So if you’re listening, HashiConf.com, check that out. And is it HashiDays.com, or is it some other URL that you’re aware of?
It’s gonna live on HashiCorp.com whenever we get it up.
That’s a super cool name, I love that. I love the way that you all have extended the last name of Mitchell to great extents. It’s a phenomenal brand name, I love it; I love HUGs - I literally love hugs, and I also love HUGs (HashiCorp User Groups)… That’s super cool, I love it.
Seth, thank you so much for joining us on the show today, man. It’s been a blast having you
Awesome, thank you for having me.
Our transcripts are open source on GitHub. Improvements are welcome. 💚