This is our 5th Kaizen where we talk about the next improvement to changelog.com: we are now running on Fly.io and our PostgreSQL is managed. This is a migration that many were curious about, including Simmy de Klerk, the person that requested this episode.
After migrating all our media files to AWS S3 (check episode 40), we thought that this part was going to be easy. Plan met reality. Pull request 407 has all the details.
We want to emphasise the type of partner relationships that we seek at Changelog & why they are important to us, as well as to our listeners. Honeycomb & Fly embody the principles that we care about, and Gerhard thinks that we are currently missing a Kubernetes partner.
Featuring
Sponsors
Sentry – Working code means happy customers. That’s exactly why teams choose Sentry. From error tracking to performance monitoring, Sentry helps teams see what actually matters, resolve problems quicker, and learn continuously about their applications - from the frontend to the backend. Use the code SHIPIT and get the team plan free for three months.
FireHydrant – The reliability platform for every developer. Incidents impact everyone, not just SREs. FireHydrant gives teams the tools to maintain service catalogs, respond to incidents, communicate through status pages, and learn with retrospectives. Small teams up to 10 people can get started for free with all FireHydrant features included. No credit card required to sign up. Learn more at firehydrant.io
Chronosphere – Chronosphere is the observability platform for cloud-native teams operating at scale. When it comes to observability, teams need a reliable, scalable, and efficient solution so they can know about issues well before their customers do. Teams choose Chronosphere to help them move faster than the competition. Learn more and get a demo at chronosphere.io.
OpenZiti by NetFoundry – Programmable network overlay and associated edge components for application-embedded, zero-trust networking. Check it out at netfoundry.io/changelog
Notes & Links
Transcript
Play the audio to listen along while you enjoy the transcript. 🎧
We’ve made it. 50 episodes. Not close enough, but we’ve made 50, which means we made it one year, right? Minus the Christmas; I think there’s one more, like 52 would be exactly one calendar year… So 50 for us marks the year.
Well, 50 is the number we’re shooting for, right? You wanna take two weeks off in a year, so we optimize for every show who is a weekly show to do 50 episodes in a year. One, that’s consistency, and two, that’s congratulations, right? To keep a podcast consistent –
Well played, Gerhard. Well played, sir.
…and hitting the mark - it’s a feat of nature. Most podcasts die. Yours did not, so… Congratulations.
Okay. I survived. [laughs] Is this like the Squid Game sort of thing? I survived this round…
How many podcasts have we produced, Jerod, that did die, because of burnout? None, right? I mean, Request for Commits ended –
Not because of burnout, I guess… But we have some shows that didn’t make it to 50.
That’s true. Away From Keyboard didn’t…
Brain Science, 20 episodes…
Brain Science didn’t.
Request for Commits, 20 episodes…
But 50 episodes is a big deal.
Spotlight I think got to like 15, and then we merged it back into the Changelog, and started doing Backstage, which I think is at like 23 episodes. And that’s been going on for years, so… Gerhard’s killing Backstage.
Yeah. Long story short, congratulations, to you Gerhard, and the listeners for sticking around. It’s one thing to put your faith in a brand new show, it’s another to keep coming back. And based on the listens, based on the traction of the show, you’ve found your audience, which is awesome.
Yeah.
I’m really enjoying it, I have to say. It’s been a year and it doesn’t feel that it’s been a year, which is really weird. I was looking at – because every year I try to look at the themes… Like, what is still relevant, what is still with us. And looking back at the first episodes, I realized “Wow, some of those - it’s been a year?!” It was like yesterday, it felt like, some of those conversations. Like, is it too soon to have some of those people back?
[04:05] So this is one for the audience… In the 50 episodes, if there was one that you really enjoyed and you want that person to be back, or those people to be back, let us know I’ll be more than happy to have them back, and I know that they will enjoy it too, because we had so much fun in every single episode.
And the easy way to do that is go to Changelog.com/request. You can do that for every show, not just this show. But in particular, Changelog.com/request. So request a be-back, as we call them. Who should be back?
Yeah, that’s a great one. Also, this episode, initially, when we intended it – like, we knew it was going to come, the next kaizen. I really like that regularity; I like that every ten we’re back with a kaizen… But this one was actually a request, and it just worked out that way. So this one was a request from Simey de Klerk at the end of February.
Ah, Simey.
Yeah, Simey was asking – so he wrote “The Changelog DevOps seems complicated, yet a lot of past providers want us to believe we can just slap in all of their services and only worry about scaling much later.” So he was wondering if Changelog just ran on Heroku? How much of the current setup is necessary to support the current scale, and how much of it is over-engineering and nerding out? So we get to answer your question, Simey, in this episode.
Hm… The plot thickens.
Yes.
How so? Are we on Heroku now?
We’re on a PaaS… So - spoiler, “We’re on a PaaS.” It’s not Heroku, it’s Fly.io.
We’re on a PaaS!
Hence we are flying. We’re literally flying. And figuratively. But literally, the app is flying. In the last kaizen episode, 40, we talked about migrating all our static assets to AWS S3, and that was one of the steps in this direction. And the background story is in pull request 400; you can check the code. And we even did some kaizen-driven development during the recording. Jerod was adding some CDN shielding live on the show, as you do… Why not? To shield the S3 origin, to keep the AWS costs under control… And that was a really fun one. I was not expecting that. It was literally not planned out, it just happened. I love that.
Well, that’s how we roll. We turn it on and we let it alone until mid-show, when - I think it was Adam that asked about the cost, and I was like “Maybe I should check that real quick…” Because we set it and forget - I think it was like 6-7 days later. One listener I think kind of called us out for bad DevOps practices there. That’s my bad, I’ll take full ownership. And we found out - yeah, we’re paying 1,900% more on our AWS bill than the previous month, which was never a fun surprise, but one that you wanna have sooner rather than later. So props on Adam for triggering me. And then I guess props to me for turning shielding on really fast… Which cut it down immediately to about half. But we were still overpaying, for a couple of reasons. So I spent a few hours over the next couple of days making sure that we’re holding S3, which was a combination of the shielding changes inside Fastly, like we said, as well as setting the proper surrogate cache control keys inside our applications when we upload to S3. Because S3 has to signal to Fastly how often to break the cache and do the full request again.
And then we also can tell Fastly how long we could do it. So there’s multiple layers of caching here, and as we all know, cache invalidation is one of the hard problems of computer science… But we’re just layering them on. It took a few days, but we ended up getting it fixed. I think in January we paid around $600 for S3, and that was the month that we turned it on, at the end of the month. So we were pacing to spend about 2k a month on S3. And then after the changes in February we paid $92.85, and March it’s down to $44.20. And we don’t have April’s bill yet. So we’re expecting around $50 a month for S3, which is totally reasonable and sustainable. Whereas $2,000/month, for the size of our business, was not.
[08:09] I would say thanks for kaizen too, because if we didn’t have this kaizen kind of ritual, I would even say like a constraint, we would have asked that question when we got the bill.
Yeah, we would have.
Which could have been enormous. So thank you for kaizen.
From my perspective there’s just a few manual things that you have to do, that I didn’t expect you’d have to do with S3, specifically setting those cache headers, which you have to go out of your way with the command line tools and with the way they were uploading the static assets to S3. So our uploads were getting the correct surrogate control header set, but our static assets, which we’ve just switched, were not… And there was just way more to it than I had ever had to do before, I guess because I have not used S3 on a website that gets the amount of traffic that we get, specifically to our mp3s.
I wanna mention a couple of things. First of all, I don’t think many people realize just how big of a scale Changelog is. So if you had to guess how many gigabytes we serve per day, how many would you say it is? Maybe, Jerod, if you already know, I’m not going to ask you; but maybe Adam… I mean, I’m not sure when you looked last, but I checked this before the show. So how many gigabytes do you think we serve per day?
I’m gonna guess, for real. I would say, knowing the size of our content and how much throughput we have, it’s probably close to a terabyte, I would say. It’s probably still in gigs, but close to a terabyte, I would say, per day.
Okay. Jerod?
Am I way off?
No, I’m not looking at it, but I have looked at it, and I think that’s high. Am I right? Is that high?
It’s actually 1.5 terabytes on a regular day, and it spikes to 2 terabytes, 3 terabytes on a busy day.
Yeah.
Wow.
So we are averaging 1.6 terabytes per day.
Well, if that were Price is Right, I’d win.
Yeah. Adam wins, for sure. Adam wins this one. So can you imagine if our caching wasn’t right, how expensive our S3 bill would be, per day, based on how much stuff we serve, and how slow it would be if our CDN didn’t work correctly? So big props to Fastly, as complicated, and – you know, sometimes we pick on it, and we’ll pick on it this episode as well; sorry about that… But just to say something nice, which is also true… [laughter] Fastly really fronts a lot of traffic from all over the world.
Wow. Yeah.
Like, Asia gets a lot of traffic, Taiwan especially…
Taiwan all of a sudden, yeah. Which is somewhat new for us, I think.
Yeah. For some reason, Ship It - Jerod mentioned it, too - is really popular in Taiwan.
Big in Taiwan.
Yeah. Not big in Japan - I was a bit disappointed - but big in Taiwan. So it’s okay… [laughter]
Come on, Japan… Ship It.
So if we average that from 1.5 a day to 30 - there’s 30 day in a month; so you’re saying that on a given day, even weekends, it’s still 1.5? Would it be fair to average 1,5, or…? What would a good daily average be, to extrapolate that?
Let’s see… I had this open before, so we’ll need to figure this one out.
What I’m trying to really get to is what’s the total then? So is the total like 45 terabytes a month?
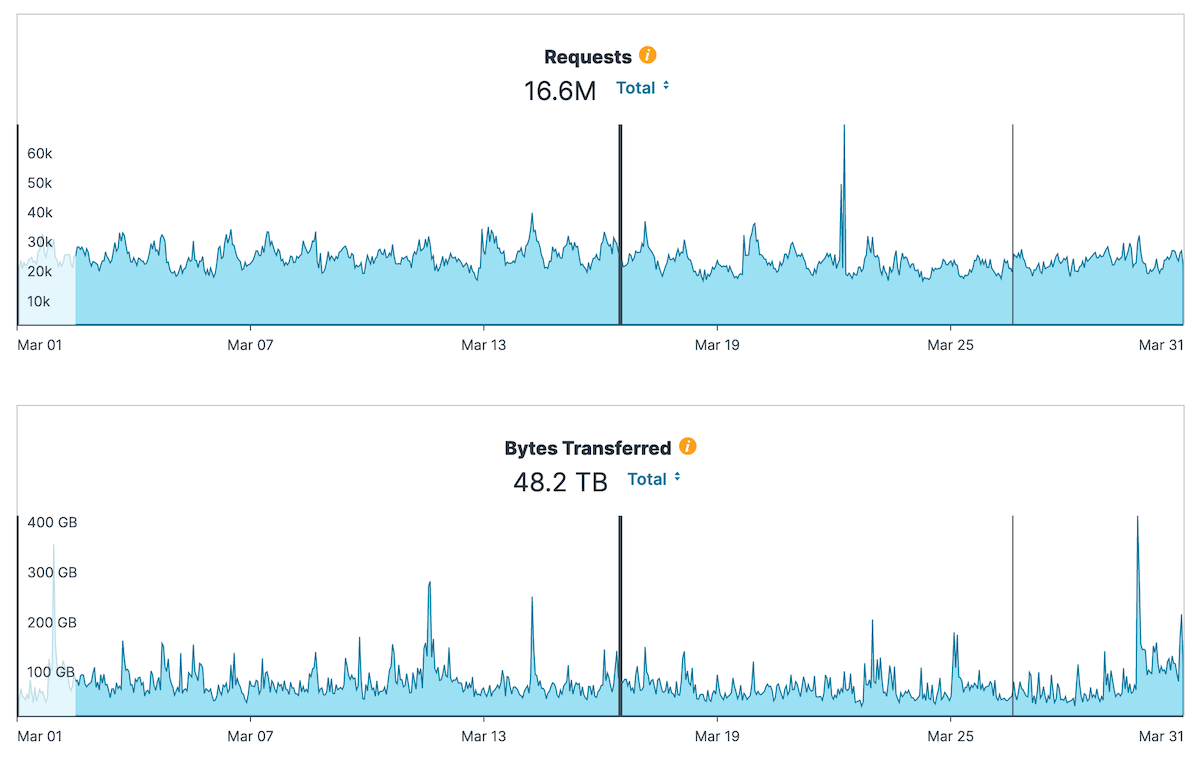
In all of March we had 45.6 terabytes, in all of March.
That’s serious, man…
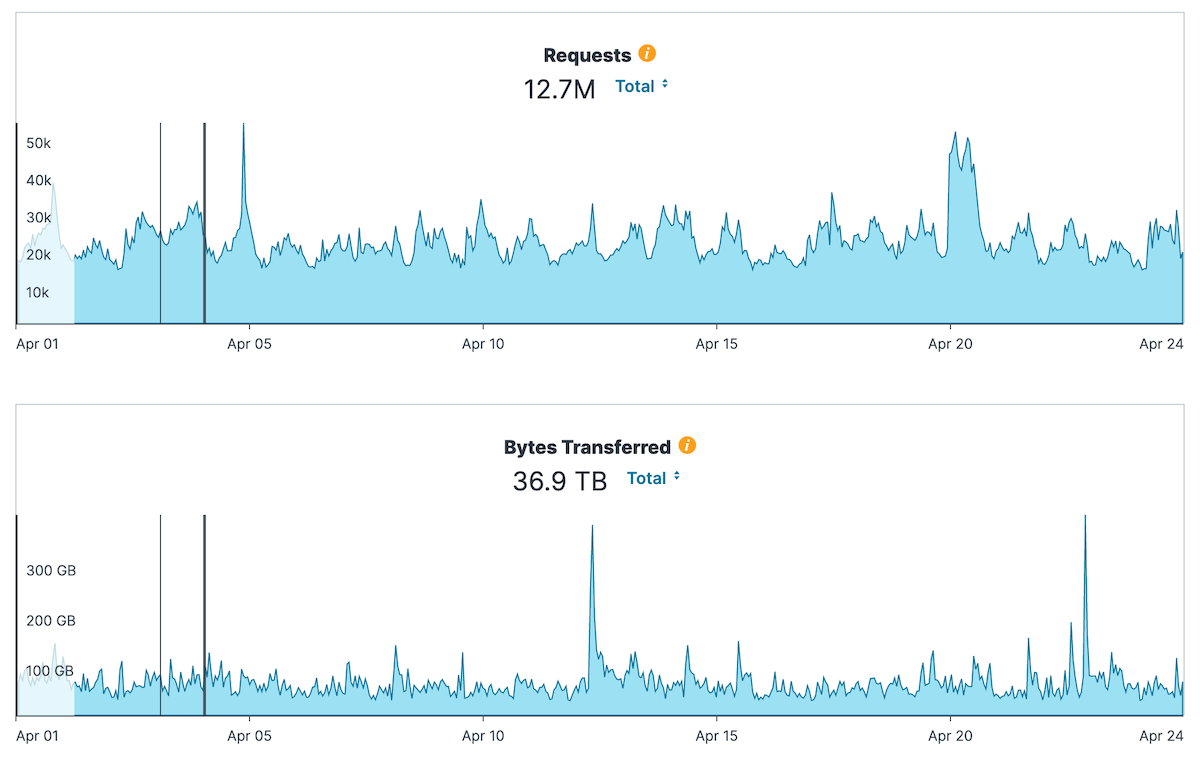
It’s some serious traffic, exactly. We have some serious traffic, is what I’m trying to say. But I can check this out… Anyways. Maybe we’ll do like a screenshot later.
Sure. For context, our episodes range from 40 megabytes on the low end, to maybe 100 megabytes on the high end. So these are larger than images, but these are not video-sized files, by any means.
And a lot of the times ranges are being server; so not full episodes. For example, I tend to listen to an episode, and I listened to your, the episode with Brian Kernighan, I think like four times now, as I was walking to the post office, because I had a couple of trips… So I listened like five minutes here, ten minutes there… I’m still halfway through it, but I’ve been working on it for about a week now.
[laughs]
And I imagine that many people do the same thing. And that’s why there’s a lot of ranges being served. But still, it’s a serious amount of traffic. So if we were holding the CDN wrong, we would really see that, as we did in the case of S3, where we were holding S3 wrong. I forget which one. Anyways, we were holding something wrong, or at least one thing wrong. So there’s that.
[12:16] Well, we’re holding it right now, so that feels good.
So we switched to Fly.io. That’s our new origin. There’s a nice story there. But I’m curious, when we did this migration from LKE to Fly.io, did you notice any change, Adam? Did the app behave any different? Do you push changes differently? What did you notice?
I haven’t shipped any changes to the codebase since the move, so on that front the answer is no, because I haven’t yet… I assume I’ll just ship the master, as I did before, and the same build pipeline is planned…
In terms of the app, I haven’t hit any errors. I haven’t noticed anything really necessarily positive or negative. And I think that’s probably the best thing you want, right? If you do make a major change, there’s no bumps or hurdles. The site was always fast. That’s one thing. So I haven’t noticed anything, really, which I think is a positive.
It is a positive. That’s why this work is called invisible. If you do your job right, you don’t see anything. So there’s all these big changes, but nothing changes from the perspective of users. Users see the same thing. No downtime, nothing like that. Well, we did have some downtime, but anyways… We will leave that for a little bit later.
But nobody noticed… [laughs]
Yeah, nobody noticed, and there’s a good reason why. It’s been designed that way. But what about you, Jerod? Because you work a lot closer. Did you notice any changes?
Oh, yeah. So from my end user perspective using the application, or from a developer perspective?
You can start with whichever you want?
So end user perspective it was pretty similar; of course, no surprise there, because Fastly is fronting every request, for the most part. On the admin however, we by-pass Fastly. We still send through Fastly, but we don’t actually let Fastly cache anything. And I would say slight, just anecdotal speed improvements on the backend, from my perspective.
Okay…
We did have the robots.txt issue which came out of this, which was problematic, and we dug into, and I fixed that one… We can talk the details if you want to on that one, or skip over it… Either way, that was the biggest, I think, technical bug that cropped up due to the switch.
Do you know how I’ve found that? I randomly just searched us, Changelog Media, on Google, and I’m like, “Whoa! That looks weird.”
Yeah.
So I think I was telling somebody our full business name, and I was like, “What are they gonna find if they go google this, Changelog Media, versus just Changelog?” And obviously, the results were weird-looking.
Yeah. And that was the result – just a little bit of detail there… So basically, our robots.txt is dynamically-served, which I wouldn’t do normally. But we want the ability to have these limitless sub-domains for testing, and previews, and migrations… Gerhard likes 21.changelog.com, 22.changelog.com etc. There’s a www which gets redirected… Stuff like that. And if it was me, I would redirect all those to the apex domain and say “You can’t do that. No, don’t do that.” But Gerhard wants that, and I’m like, “Alright”, especially if we’re having previews, and stuff, I understand the reasoning. But unfortunately, Google was starting to index some of those subdomains; and they had the same exact content as the main domain, and that’s not great for SEO. And the way our canonical stuff works, I just didn’t wanna have it. So we have dynamic robots.txt, which if detects changelog.com, it’s going to serve the one that we’re used to, which is like allow everything except for – like, ignore the admin, ignore some stuff, even though you have to be signed in… Whatever. There’s a few ignores, but mostly just allow.
And then if it detects not that, then it’s like “Hey, just allow all. Don’t index 22.changelog.com.” And the way that dynamic robots.txt works requires the host header to sniff the origin domain; and we lost that in transition over to Fly, because we had to switch to – do you remember what it was, the key? There was another exported header, something like that… Exported host, maybe?
[16:07] Yeah. Exported host, that’s right.
And so we began, after the Fly migration, to block Google from indexing our entire website. So that’s not good… [laughs] And it didn’t actually affect our search traffic for a while. I think maybe Google just takes a while to actually do its thing… And then eventually, Adam noticed that it did, and I dug in there and got that fixed. So that was not great… And I almost think that it’s the way I coded it. If I could code it open by default, but then closed if you detect the abnormal circumstance, I think it would have been fine. But that’s a lot harder, because then we had to have a list of domains, of subdomains that we detect, and the way I did it was like “Closed by default, but open if I detect the right origin”, and that busted. So… Fixed, but that was definitely like a –
That was a big one.
“Holy cow, get the text editor out and fix it right away” kind of a thing. It’s not like “Oh, no big deal.” That was bad.
It’s stuff like that, which unless you make these big changes, you forget that they even exist, and the problem is you have quite a few of those in your codebase, especially if it’s more complicated. If you have many people touching it, making changes, basically… And in our case, because we make these changes fairly frequently, at least once a year, we’re migrating from one Kubernetes to another - but this time, we changed platforms. And because we changed platforms, we are using the Fly.dev domain, so we have all traffic coming to www or the apex changelog.com goes through Fastly. That is the entry point. But then we have those origins, which if you want to by-pass Fastly, you can go directly to the origin. So we had 22.changelog.com and that used to resolve to a Linode node balancer which would be provisioned via LKE. It would have an Ingress, and that’s how that used to work before.
But when we migrated to Fly, we no longer had the Changelog domain. We were using the Fly.dev domain. And once we did that, a bunch of stuff broke, especially this one, the robots.txt. So I think there’s something to improve for us, and I’m wondering what that improvement looks like. We don’t have to talk about it now, but it’s something I definitely want to dig into, as a pull request, as a follow-up, whatever that looks like… But that is an important one, because I would like us to have multiple origins. Fly is one, but should we have more? We talked about multi-platform for a while… And while I don’t think we’ll do that in a rush, I still think we would like to be open to that, so we’re not Fly and nothing else. We like it, that’s great. But you know, we felt the same about LKE, and it was for a while, and we enjoyed it, but then something else comes along and it makes more sense, and we try it, and we like it.
So the idea being these improvements make a lot of sense. I wish we knew about that, but you don’t, and that’s what happens. Same thing with S3 - there’s the unknown unknowns. There’s no way you will know how it’s going to affect you until you make the change. And that’s why when we did the migration, at the last step of switching traffic we realized, “Oh, crap, there’s this problem in the VCL config.” But maybe we don’t talk about that just yet, and we talk about other changes that we noticed since migrating.
So one thing which I noticed today as I was editing episodes - this is as an end user - I noticed that I had to save an episode multiple times to see a change. So I was doing some edits, episode 49, save, refresh the page - the changes weren’t there. I thought it was caching. But then I was by-passing Fastly, I went directly to the origin. So it’s a nice way to be able to rule the CDN out, and everything’s still working.
[19:46] And for some reason, the page was not updating. And only when I saved it again, the second time, even though nothing changed, then it updated. It might be the app. Maybe. I don’t know. Maybe Jerod knows there’s like some caching, something happening… Because the one component which is new, that we didn’t have before, is now we have the Fly proxy. The Fly proxy is the equivalent of the Ingress NGINX, and I’m not sure how that behaves, because we don’t have any logs from it. That’s like a request, and we’ll talk to Mark about it… But we can’t see what’s happening. That proxy layer is like an invisible component, so maybe this is something happening at that layer, but we don’t see that.
I haven’t experienced that, but I would say that’s definitely not in the app. I think we’ve used the app extensively at this point. I’ve never seen that, so I would think that’s probably infrastructure. And the code around [unintelligible 00:20:35.07] episode form hasn’t changed for years, so I would expect that to be infra.
Okay.
Or your internet connection, Gerhard. It could have been your internet connection.
No, it’s definitely not. [laughter] It really isn’t… And we’re not opening that can of worms now. We need like a whole episode just for that. But no, it’s not that. So anyways…
We kind of did. We kind of did.
So I’m suspecting something happening at the Fly proxy, but it’s something to look into, for sure. I mean, that must be a really complicated piece of tech, because it fronts the whole traffic to the different Fly apps that you have running, all the instances, everything.
yeah.
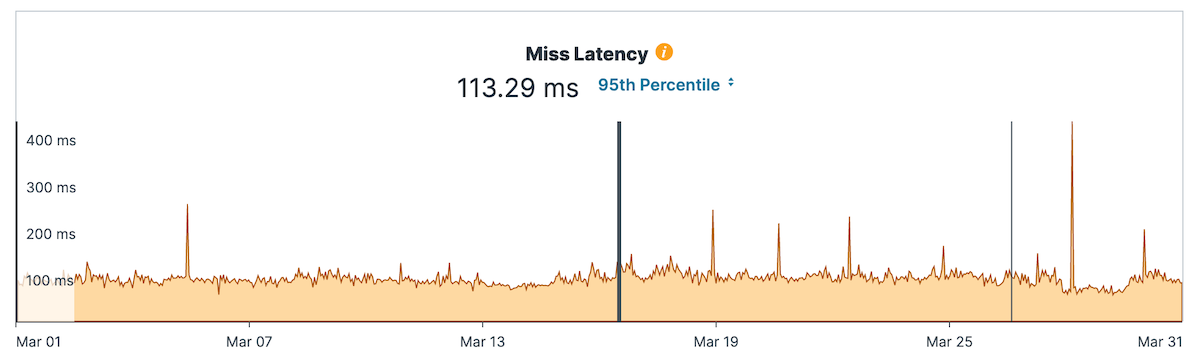
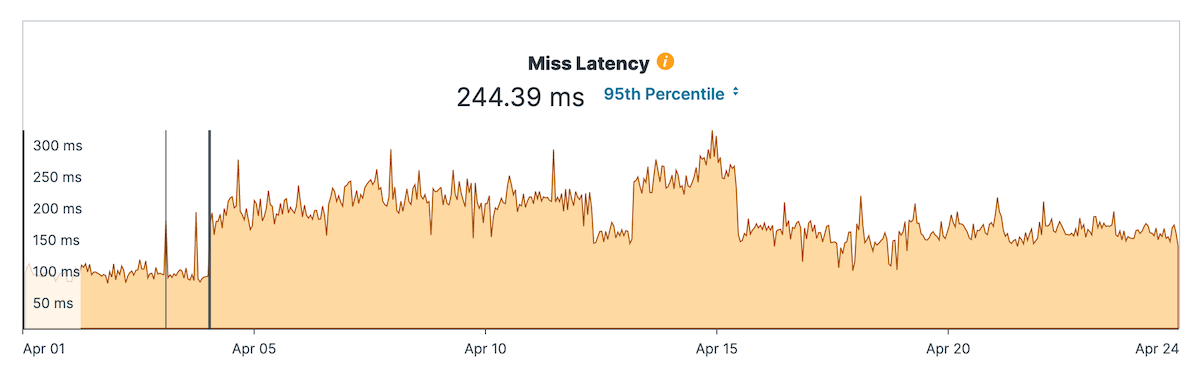
But the other thing which I noticed, and I think this talks about speed, is the miss latency. So when it requests in the CDN, we can’t serve them from the CDN, and they have to go to the origin. That went up to 250 milliseconds, and we can see that in the Fastly metrics… And it used to be 115 milliseconds, so it’s more than twice as high. And maybe it’s not big enough for you to notice, but I’m really wondering what is happening there.
Now, the other thing which we changed is we removed shielding. So we no longer have shielding. What that means is that any requests going to a Fastly POP, it has to go to the origin; it can’t go to a shield, another Fastly POP which basically has it in the cache maybe.
Right. So for clarity, that’s shielding on the Changelog.com domain or origin, not on the cdn.changelog.com, which goes to S3. So shielding there is on. Shielding on Changelog.com is off. It used to be on for both.
Yeah.
So we’re hitting Fly more than we are hitting Kubernetes.
Exactly, yeah. Before we weren’t hitting Ingress NGINX as much as we were hitting the Fly proxy. So that’s the one thing. But again, I suspect that if we had more details from the Fly proxy, we would be able to tell, because that’s like one blind spot that we don’t see, or one component that we don’t see.
Okay, so you must be wondering why did we really need to migrate off Kubernetes… Because I have been talking about Kubernetes for like 49 episodes, and now all of a sudden I’m telling you “What?! We’ve switched from Kubernetes.” [laughter] And it’s not because Simey asked, just to be clear. Simey asking “Why don’t we use a PaaS?” - it just so happened that it fit.
You’re telling me this whole thing is not because of an episode request?
No, no, no…
Because that would be as listener-first as you could possibly get, right?
Yeah.
Yeah, I mean…
It reminds me, we have another episode request that says “You should rewrite your platform in Clojure.” So…
Go to AWS Lambda. [laughter] See you two years later…
“Why is this not written in Go?” Okay, I guess we’ll restart…
There you go. Or Rust. Even better, Rust. For sure. Or both.
I would say there’s multiple layers to this why, honestly. There’s multiple layers. There’s gonna be layers from you, Gerhard, from you, Jerod, and there’s layers from me… And then obviously from the listeners’ perspective, thinking “Okay, why is this seemingly just a podcast host app running Kubernetes?” question of like “What’s the deal here?”
Which we’ve definitely tread on that ground some, but… Okay, who wants to go first? Why did we do this? Who wants to kick it off?
Alphabetical order, I propose. That means Adam…
Adam. Adam’s first. I think for me, the reason – because I think I resisted, I pushed back on the two of you on a possible change for a while… Because at the core of our business, we really thrive on great partnerships. Fastly has been a great partnership, we talked about how they’ve fronted our traffic, how much traffic they front for us… And it’s really amazing. I think we’re uniquely positioned in our business as podcasters that also talk about tech, in particular software, and how it works, and how it’s deployed, and how it affects teams, how it affects the future, the innovation, open source, business… All the different angles. And so at the heart of our business we really thrive on great partnerships. And Linode had been a great partner for many years. And they were recently acquired, and there’s nothing negative about Linode, they’re still an amazing team… But I think we, to the nerd-out question, we wanted to nerd out at several layers deeper, and we just didn’t have that opportunity at Linode with kubernetes, [unintelligible 00:26:27.02] we could.
And lo and behold, about a year ago I was reintroduced to Kurt Mackey. Jerod, you spoke with him on the Changelog, solo, a while back. He’s got lots of interesting routes that cross ours, from Ars Technica, to Compose with the IBM acquisition, and just a lot of history there. And don’t buy my nasally cold, by the way… So if you hear me out of breath, I kind of am out of breath, so bear with me… But I was reintroduced to him, and really fell in love with how he approaches this Fly platform, and the way he desires to engage with developers. And then obviously, the influence they’ve had over Elixir and some of the roots they’ve sort of planted there, and the depth they go with different frameworks and platforms I think was really attractive to me. And then they’re also just fun and easy to work with… And from a nerd-out perspective, I think it’s going to be fun to be flying with them and to help them improve that platform, and obviously, to bear some of those benefits.
So the Why, from my perspective, is we desire great and deep relational partnerships. So because of that, we had this opportunity and this curiosity, and the possibility of a better way for our application. So there’s just a lot of multiple win/win/wins to just say “Yeah, let’s do this.” So that’s my reason for Why.
That’s a good one. That hit some really important aspects. For me it was a couple of things. One recent one - Kelsey was mentioning about having a managed PostgreSQL, and I was thinking “Yeah, why don’t we do that? Why don’t we just go and get a managed PostgreSQL from somewhere?”
[28:02] I know that we talked about CockroachDB for a while, but the change is too big. I remember Jerod pushing a little bit back on that… Like, “Is there something smaller that we can do as a first step?” So Linode, and I think MySQL is in private, or it was in private beta when I last looked at it; maybe it has not been made available more widely, in more locations… But they didn’t have, and they still don’t have PostgreSQL today. And that may seem like a small thing, but we did have quite a few issues with PostgreSQL, and we had downtime because of it, we went to Kubernetes operators, and… It’s just a complex problem which - should we really be spending any time on? And the answer is no. Kelsey put it very nicely in episode 44 why we shouldn’t do that… And it really got me thinking. Like, what is the hold-out? Why are we doing this? So that was one thing. The other thing was the forced migration. I really did not like that, I have to say.
Say more about that.
So mid-January this year we got an end-of-life notice from Kubernetes 1.20. And I knew it was coming, so it wasn’t a surprise, but we just had to upgrade. And at that point we spun up another 1.22 cluster, because you know, we run two of everything, more or less. So a few things happened since then; you know, we just couldn’t complete the migration, but it was a testing ground for the S3 assets.
I remember us testing like “Does this app work correctly in its final setting with the S3 assets?” And that really helped, and everything worked, so it was fine… But we still had a couple of components missing. So we couldn’t just do the migration. Mid-March we got the final end-of-life notice for Kubernetes 1.20, which is what was run in production, Changelog.com, the origin.
And if we didn’t upgrade in the next 48 hours, we would have been forced to upgrade to 1.21. And we couldn’t stop the upgrade; I reached out to support, and the answer was “You either upgrade it, or we force-upgrade it.”
Now, the problem with that was that we had the PostgreSQL data - see? It keeps coming back to it… We were storing it on the local storage. Why? Because it was the most reliable configuration for our database. And when we used the block storage, when we used the volume, we had all sorts of issues with volumes not detaching correctly… And I know these were early days, but we had issues around like not having NVMe Drives; that has changed in the meantime… So there were certain limitations which were preventing us from using PostgreSQL the way it’s meant to be used in Kubernetes. And it just goes to show it’s a hard problem.
So if we had let the upgrade, the forced upgrade go through, everything would have been broken, and we would have been in a mad scramble to fix it. And no one wants to do that, because then you do mistakes… That was like in the middle of the night for me… It was just an awkward way to go about it. And we already had this 1.22 cluster set up, so why can’t we just use that?
So to cut the long story short, this forced upgrade was not nice, and asking like “Hey, can we defer this?” It was just a matter of a few days. Because the big thing - and I think this is the back-story that people are missing… I just joined Dagger. We were launching Dagger. It was a crazy couple of months, and I didn’t have any spare cycles to do this. It’s not because I didn’t want to… I was looking forward to that, but I was always pushed to do things. I was like, “When I have time, I’ll get to it. But not now.” And that pressure was just – you know, whenever you’re under pressure, it doesn’t matter how experienced you are, it just takes the joy out of it… And that’s why we did it. We did it for the learnings, we did it for the joy, we did for “You know, this is fun.” It’s not work-work. We’re doing this for the learnings. And there’s a couple more, but I’ll let Jerod go next.
Well, I wanna throw one thing in there too, because I think this is part of the frustrations we have… Because if we had a deeper partnership at the nerd-out level, this may not have been quite a problem. Because if you have empathy from your partner - and I’m not saying that Linode is bad; I’m not trying to say they’re bad. We just didn’t have that kind of access, which was what we desired. And that’s why working with Fly makes sense; that’s why this Why makes sense to me… Because if we had that, if we could say “Here’s our challenge. We’re in the middle of something else. We can’t make this, and this forced upgrade is really bogarting abilities right now.”
[32:17] Well, if you have that deeper-level partnership, that deeper-level access to those who can not force you to upgrade, then there might be an easy yes… Because we had like zero empathy. It was just support. We didn’t have an advocate for us, technically, inside of Linode, having our back. And that to me is challenging, because we desire to partner at that level, because of this show and what we do. That’s why it makes sense for us. So if we had that, it may have been a different story. We may not have gotten curious to go and say “Well, maybe this PaaS makes more sense.” We really desire just that deeper partnership, and that’s what we have now.
I’m sure if there was something happening on the Fly platform in the next year, and it was gonna – you know, there would be some workaround. We would have some sort of handholding, some sort of guidance, some sort of empathy and forgiveness in the process.
Well, everything I will add is additive, because I’m well aware of both of what you have said. So those reasons I think are actually enough. But from my perspective, and why I’ve been excited about this shift, is because I’m a Heroku fan boy from way back.
Truth.
I mean, I’m an old-school sysadmin, and I was like “SSH into the machine, set up some cron jobs, copy the stuff, rsync the things, backup the database…” And once I didn’t have to do that stuff anymore, with Heroku, I never wanted to do any of that stuff ever again. I am a loyal listener of Ship It, but I don’t do any of the things that you guys talk about doing on Ship It. I just like your show, Gerhard. But once Heroku came around, I was just like, “Yeah, let’s just let Heroku do all the things.” And when it came to Elixir, I lost that, when we were gonna go deploy this Elixir app. So that’s when I brought you in to help me do the things that I used to be okay at, but also don’t know how to do things well anymore in this ecosystem, and thus began our story.
When it came to Ansible, I was along for the ride. When it came to Concourse CI, I was just riding your coattails. When it came to Kubernetes, I was like “I hope Gerhard knows what he’s doing, because I don’t…” So just the Heroku style, PaaS, for me is exciting because I feel like it’s a pool that’s shallow enough that I can swim in it safely, and not have to turn to you and say “What’s the kubectl thing, or the K9s thing?”
Yeah, shortcuts, and…
…because those are just areas that I don’t normally swim that deep in. And just being back on this short time, I’ve been able to figure out some stuff for myself, and do things the way – I mean, it’s not as polished as Heroku. We might get into some of those details… But it feels familiar. And for me, my mental model is so much simpler, and it’s not for any reason, I don’t think, except for that I never acquired the deep knowledge of the other platform. So this is something I feel like I can grok more simply, and administer without you. Even the other day I asked you a question, you weren’t around… I’ve figured it out. And there were a couple times in the previous setups where it was like I ask you a question, you don’t answer, because you’re working or whatever, and I try to figure it out and I’m just like, “Nah, I’ll just wait. I’ll just wait for Gerhard.” So that for me is exciting, about simplifying, for me, so I can do more stuff.
That is a big one, because what I’m hearing is I did not build the platform that Jerod needs… For obvious reasons. [laughter] So is there one that we could use, that would work? And Fly definitely fits that bill.
[35:49] But just to mention – again, the additive, to keep that point of view, to what Adam said. The interaction that we had with Fly was amazing. We had the Slack channel, we were able to talk to Kurt, we were able to talk to Mark, and I think Joshua… There was someone else, and I forget their names, but everyone was so helpful. Everyone was there. We had an issue, and it was fixed the next day. And this was like a genuine issue on the platform. So they are iterating –
There’s even comments on the PR from Kurt, you know?
Exactly, yeah.
So it’s like, there’s a feedback loop which we just did not have.
So yeah, that’s PR 407. You can go and check it out. But there’s one more thing which I think you will want to stick out for… So we said that we migrated to Fly.io - not the first time. That didn’t work. And it had nothing to do with Fly.
Right.
So we ended up going from Kubernetes 1.20 to 1.22 at 4 AM in the morning because Fastly and Fly just did not work. [laughter]
It was not gonna work…
No. So at like 4 AM, I’m just like all Kubernetes with this, because that’s what I know, dang it, and that’s going to work… And there was like an issue between Fastly and Fly, and it’s too late, and I can’t be bothered, I just wanted to go to sleep, whatever… PaaS is meant to be easier, right? Or easy. And it wasn’t.
Now, again, just to be clear, it was not a Fly.io issue. It had nothing to do with Fly.io.
I should say that I was with you. So it was your 4 AM… For me it was like 8:30 PM, 9 PM, and I was sick that day… So I was like, “I can’t believe this is happening right now.” I knew that it was middle of the morning for you, and when you said “Let’s just go back and do the LKE upgrade”, I’m like “Yes! Let’s just do that!” And 15 minutes later it was done. We were done. And that was amazing.
So we had all this plan, all the steps, and I had even like an incident running… It’s all there. you can check out PR 407. And just like when we were adding the Fly origin into the Fastly config, everything blew up. And what I mean by that - the requests that were not cached - they were trying to be served from AWS S3. So admin pages, and news impressions, and any dynamic content was getting 404s because AWS S3 did not have that resource. That’s how it was behaving. I’m like, “What is going on?! The config looks good… This makes no sense.”
So what was the problem? The problem was a VCL misconfiguration. This was in Fastly configs. One of the subroutines was getting terminated before the backend was being set, and I’m still not clear whether that was the actual issue why… Because we have 12,000 lines of VCL config, 11.5k is just gibberish, because it’s all the origins, all the various shields, and only 500 is the actual config… So we’re having to do some vimming, remove a lot of lines… And then it’s like spaghetti code; you look at it… Why? Because it’s generated via ClickOps, right? You click through a UI –
This is why robots are not gonna take over our jobs any time soon, because that’s what they generate, is 12,000 lines, and we have to go wading through it as humans to figure out what spaghetti code that ClickOps generated. And it’s crazy how much junk was in there.
Yup, that’s right. And it’s still is. That has not been fixed.
It’s still here. [laughs]
But we have a hack that just kind of makes it work. There’s a VCL hack. And it’s just like how VCL snippets get integrated with other types of snippets, and they all get merged together into what looks like valid VCL… But sometimes it takes paths that you don’t expect it to. So when we’ve removed one origin and added another one, it just wasn’t even hitting it. So no requests were being routed to that second origin, even though everything was configured correctly and it should have worked… But you know, there were like some if statements, nested ifs… It always starts with nested ifs…
Yeah. And so Gerhard, you and I are sitting there, trying to determine – this is like when you’re knee-deep in a long debug session and you’re thinking, “Okay, is it because of the order in which we entered these domains, these origins?” “No, it’s not that. Because of this.” “Is it alphabetical?” You start wondering, “Is it ordering by alphabetical?” And it’s like, “Oh, it looks like it is. Oh, no. There’s a case where it’s actually not alphabetical.” We couldn’t figure out exactly what it was, but we did figure out a workaround… [laughs]
[40:11] What was the AI thinking when it generated this VCL…? [laughter] Getting in an AI mindset. There’s no AI by the way. Just some automation, and it was so difficult…
Yes. Like backend procedural code, for sure.
So I even wrote an app, a Go app, and I was using the Fastly starting app just to try and understand how the headers are being passed through. So we have the – do you remember lazu.ch? The Lazu Switzerland? We already talked about it in one of the kaizens…
It’s true, yeah.
So I took that service, which is configured in Fastly, to figure out – and by the way, all of this in pull request 407. So if you read it, you’ll notice why it took us two weeks longer to migrate to Fly.io, and why we had to take the Kubernetes one into detour in that migration, because it was just crazy.
Because we were running up against a deadline. This was like a scene from a movie, like Speed, or…
Swordfish?
You have 48 hours to cut over and –
[laughs] Swordfish, yeah. Exactly. That scene from Swordfish. That was Gerhard at 4 AM. Adam, have you seen that one?
I know the movie Swordfish, I can’t recall the scene…
Uh-oh… Gerhard is gonna break the show again. [laughter]
No, no, no…
I do own the movie, I’ll go back and watch the scene to laugh later. My bad…
[laughs] Bad idea Jerod.
Oh, my gosh…
[laughs] Here he goes again…
Let me comment here… I don’t know why they’re laughing so hard; apparently, this is an amazing scene… To recap though, the plan was to just move straight to Fly. And essentially, at the 11th hour we had to throw in the towel and just submit to the migration to the newer Kubernetes, the upgraded version. We had to just do the upgrade, because it was too complex.
Yeah, we just ran out of time.
Which, thankfully, that was still a possibility, that we weren’t completely out of the water.
Always have a plan C… Seriously. You always have to have a plan C. Because when plan B doesn’t work, what are you going to do?
Right. The deadline was gonna happen. The app was gonna be up already. What would have happened though? So if we didn’t upgrade to Kubernetes – from 1.20 to… It was 1.21, right? Is that right?
1.21, yeah.
1.20 to 1.21. If we didn’t do that, our app would have broke.
Yes. And we would have lost some data as well.
Yeah, they were gonna upgrade it for us, and it wouldn’t boot, right?
It wouldn’t boot, exactly.
I hate to go back to it, but that’s the thing that chaps my butt like we are going to break with this forced upgrade. It’s not like, “Oh, we’ll have some bumps.” We’ll lose data, our app will break, and we’ll be in a dire situation.
And we’ve made that clear.
Yeah, we did.
This is like when you’re hitting up against your tax deadline, and you’re like, “Can I file an extension?” And then the government says “Sure, you can file an extension.” But Linode said no. No, there’s no extension for this. This is happening.
Yeah.
And who knows what was going on inside to make that that strict. Who knows. They did just go through an acquisition, and maybe there’s something inside that we’re not aware of… But it just wasn’t offered as a possibility.
Yeah.
So here we are, 11th hour, Swordfish, and then having to cut over, and there you go.
Yeah. So having that 1.22 was really helpful. It was crazy how Linode had the solution for us… Right? Because let’s be honest, that’s exactly what happened with LKE 1.22 there but we didn’t want to go to that, because we thought “Okay, we are going to Fly. This is happening.” And everything was going great. Unexpectedly good. Until the Fastly configuration. And it was obviously like a bunch of things; we were tired, you were sick, Jerod… It was a long day, it was a stressful period… You know, mistakes are made, and it’s normal. Those things will happen, so how do you factor those in in whatever you’re doing?
Can I share some behind-the-scenes in the Slack channel of what happened, when you were talking with the team at Fly about the VCL?
Sure.
[44:03] You shared the Fastly integration, the issue, they captured it - which is all out there - and Kurt’s response was “That is a very large VCL. Wow.” And y’all talked back and forth about bandwidth and whatnot, and just how challenging it is to deal with VCL, and in particular how big that one was, which you all commented on already, which is ClickOps, lots of lines, not very human-readable… We’re not gonna be replacing it anytime soon.
Now, to Fastly’s credit, and to whomever engineer-coded that backend, when you turn shielding off it gets a lot simpler. So the VCL that’s generated without shielding is dramatically shorter. So it’s not like every VCL that Fastly generates is gonna be inscrutable, it’s just that ours was. Or anybody who has shielding turned on is. And probably most people do, so… Your mileage may vary, but… Apparently, setting up a shield for POPs all around the world is complicated. It’s got a lot of instructions for a lot of circumstances.
But even if you remove all of that… So let’s say you remove all the shielding.
That wasn’t the bug though. That was just obfuscating the bug.
Exactly. And you look at how everything gets structured… We basically have some extra logic in a VCL snippet, that configures the origin in a specific way. Okay, this is my long – let me do it very shortly. The UI generates some VCL, which is very difficult to work with, understand, debug. And while the UI makes it easy, it gets you into situations when you can introduce bugs, just because you use the UI. Like, this should not be possible. You should not get yourself in a situation when a backend is configured and everything is good, but the backend isn’t used because there is a snippet which exits the subroutine before the backend is set. If you think about it, this should not be possible, and it is.
I think the more important thing is I can see the same story in a way repeating itself, the Linode story, where there’s no empathy, there’s no collaboration on the Fastly side. There’s all these issues that we keep hitting across; and yes, support is good, we get our answers, but we cannot get past that stage of just getting support, and we say “Look, this doesn’t make sense.” I mean, we still have an issue with certificates that’s been two years old and it still has not been solved… Because we’re getting support, we’re not getting a partner.
Yeah. And I think part of these shows and part of this feedback - there’s gonna be a Fastly engineer listening to our show one day. There’s gonna be somebody knowing that we desire to improve, and that we’re patient. We’re not upset. Obviously, we’re perturbed, because it’s not the ideal situation… But we desire to make these partnerships not just to leverage the platforms, but to improve the platforms, which I think is key, because customers won’t do that for them. They’re gonna angrily shout at support for solutions and they’re gonna move about their day and improve their product, and ship better stuff, and make money, and profit, and get back to shareholders, and whatever. That’s how business works.
Our desire is to come to this mix and say “Okay, here’s some amazing picks. Here’s Fastly, here’s Fly, here’s Honeycomb, here’s XYZ”, and say not just “Can we leverage this platform, but can we also help you improve it?” We wanna give you that feedback loop, for us and for you, because somebody out there is not telling; we’re gonna tell you, because we care, deeply. So give us that feedback loop and we will help you improve.
I remember that was one of the key reasons why we started Ship It, and we were thinking like “Do we have something here?” And that was one of the pillars on which Ship It was built. We think we can do amazing things for companies out there by simply using them, and by partnering with them, and it goes beyond being a partner of the show, like sponsoring a show; it really does. We’ll use your stuff, we’ll tell you where the blind spots are… We will tell you the things that you’re missing. And it’s just one perspective; we’re not the final word in how to design systems and how to improve systems, but it’s yet another data point, and we’re a patient one. The code is there; we try these things, we have all the redundancies in place, we have a resilient system. It won’t break. And we ourselves are trying to improve along the way.
[48:17] And our closed open source - when you say “Okay, how does it integrate with a well-tuned application that’s in production, that’s also open source, that you can read the source code, permissively too? You can copy some of the code.” What’s our license, Jerod? Remind me. It’s like, “Hey, take it if you want.”
MIT.
Yeah, MIT. I even forget, that’s how little I pay attention to our license. I know it’s permissive, that’s all I know. It’s a great thing. I mean, it makes me excited about this show, and even back to being here with the fifth kaizen, episode 50, I love when you can look back at the path you set and say “Okay, this was actually a good path.” Like, you have some assumptions, “Okay, this is a good path. Let’s go and improve as we get there.” But I think having you speak to the community and involve the community, from those who were the innovators building the platforms, to those who are the end users, hitting the bumps and challenges along the way, and the practitioners putting it to work - like, that’s a great mix for a show. And for us, how we leverage some, if not all of those same topics within our own platform, and have that sort of retrospective, basically, of like “How did this go? Does it work well? Can we improve it?” That kind of thing. I think it’s such a beautiful recipe.
Very well put.
So I really like the journey, and I’m wondering where are we going next. You can already tell, as a kaizen listener, that this is towards the end of this episode. So what is going to happen next? I’m very curious about that. There’s a couple of things which I have on my list, but maybe we can start with Adam first? Or no. You know what - let’s do in the reverse alphabetical order. Jerod first.
Okay…
Is there where I put in my Fly.io feature requests?
You can… Mark will be listening…
[laughs] Because that’s where I’ll go next…
…and Kurt will be listening, for sure, and others as well… Go for it.
I like this platform. It has a kernel of something amazing. There’s a lot of missing things that I would like to have, as an old Heroku fan boy from way back. And the main one, for now, that I think is top of my list is like “Hey, how can we work with Postgres better?” Because right now it’s like – well, you work with it… There’s a simplicity of like “Well, you basically SSH in and just do what you would do.” PSQL, PG dump, and so familiar tools. It’s like your own little shell there, do your own thing. But I would love to have automated backups, and things that you can just click a button… Give me some ClickOps. Let me check the button that says “Manage my Postgres backups, and allow me to do things –” A lot of the stuff that Heroku built out over time, Fly is missing.
The other thing which I think is smart, but I hate it, is the way they do secrets… Which is like 100% encrypted there. You can set them, but you can’t read them. I understand why, but… Come on, man. Just show me my secrets. I need to know what they are. [laughs]
Yeah, it’s a one way… Well, it’s not really a one way. I mean, you’re right - why can’t the app get it?
I have to log into the app and then basically echo out the environment variable. Well, come on; if I can do that, just go ahead and echo it out for me right here, by terminal, like everybody else does… So these are things. Those are just two off the top of my head. I could go on…
Those seem like easy things to fix though.
Well, I think that’s probably a decision they’ve made, and it’s like a security decision, and I get it. But as an end user, it’s just adding three steps to the exact same end goal of like me also echoing out plain text to my terminal session… And so maybe don’t those go over the wire… Oh, they do; they go over SSH encrypted wire. Anyways. I’m sure they’ve thought through all the security concerns there, but I think as a user experience it just kind of sucks.
Those are just a couple things… I think Fly improvements - I’m looking forward to them, and I think Postgres backups and automation and those kind of things… Do we have a solution, in the meantime, for that? Because I just pg-dumped a backup, and I’m thinking “I hope this is happening every once in a while…”
Apparently it’s happening every day, but you can’t see that. Or at least I don’t know how to look at it. I just trust it’s there; that’s why it’s managed. I’m really thinking of deploying that other container which we had in Kubernetes as well, that every hour would back things up. And I think even – I think it was the pod. Yes, it was the pod. So we had the init containers; the init containers before the app would start would do a backup, before it runs the migration, and that was really important, so that in case the migration messes something up, you have the backup.
Yeah.
Fly does things differently when it comes to applications starting up. So that lifecycle - and this was one of the issues with Heroku as well; you didn’t have those nice hooks to put into them, like for example init. Like prestart prestop. All that is just like a bit – I know it’s the detail that the majority doesn’t care about, but for us it’s really important, like how can we trigger, for example, a backup before we run a migration? Or if an app crashes, can we save the crash dump somewhere, the Erlang crash dump? And things like these, that especially when you’re so deeply integrated with Phoenix and Elixir as Fly is, we should have those things… Because they are first-class in Erlang, Elixir and Phoenix. That’s one right there.
[55:56] So I like that I can do Fly logs, like I used to do Heroku logs –tail, and right there, easy to get at my logs. I would also like those to be in Honeycomb, so that we can query them later.
Oh, yes.
I don’t know, that’s probably – is that a Gerhard thing? Is that a Fly thing?
Yeah, yeah.
Yeah. So that would be the next step I would love to see. It’s not a Fly feature request, it’s just like “Can we get everything into Honeycomb now that we have it setup?” Specifically logs, from the app specifically.
Exactly, yeah. The app telemetry, the Elixir, Phoenix… Oh, yes. I would so love that. That was on our list for a long, long time. But now that we did the migration, we can start focusing on these things - how to do that integration, how to get the app logs into JSON format, into Honeycomb, so we can slice them and dice them, now that everything is set up for us. How can we get the Fly proxy logs into Honeycomb as well? Is it even possible? I don’t know. But we would want that.
That was the important one, Ingress NGINX logs in Kubernetes. We were really using those big time, because that was the interface between Fastly and the application. And okay, there was like the Linode node balancer as well, but that was like a layer four, I believe, so it wasn’t in the network stack… So that was okay.
The PostgreSQL backup - that is a big one. But the biggest one for me are the certificates. So we used to use cert-manager in LKE. Our certificates will expire in two months if we don’t do anything and things will break. So we have two months to fix this problem.
We’ve got a new deadline.
Yeah, we have a new deadline, exactly.
You expanded from 48 out to two months.
Exactly. That is like the next step. So by the time we have the next kaizen, we will have a story about this, how we solve that… And it’s not an easy problem. It’s not an easy problem because –
So describe the problem… Why is more difficult on Fly?
So we were running cert-manager before, which was managing our certificates. Fly is able to manage certificates, but we can’t get the private key. And because we can’t get the private key, we can’t upload it to Fastly, to the CDN. If the CDN, if Fastly manages certificates for us, no one else can, which means that Fly can’t, because they add a c-name record for the ACME Letsencrypt integration, and only one of them can manage it at any one time. If Fastly does it, we can’t’ get the private key. If Fly does it, we can’t get the private key. So only one can have it at any one point in time.
So maybe, maybe this time around we can use Fastly. So Fastly will manage the certificates for us. Fly won’t, because Fly - we use the Fly.dev domain anyways, and hence the issue with robots.txt. So maybe that is the simplest thing, let Fastly manage our certificate. What about you, Adam? What is the thing that you would like to happen next?
I think just keep going copacetic. I don’t have any particular requests. I’ve been enjoying Honeycomb, and I know both of you have desires to get more of our logs and whatnot into Honeycomb. I know in particular I’ve been enjoying how I can communicate back to the two of you when I have challenges. I know I had an upload challenge recently that I was able to describe with data, not just complaint… Which I think is really awesome, whenever you complain or suggest there’s a bug or an issue… And I’ve been enjoying Honeycomb for that reason. Plus a lot of the stuff we’re doing around podcasts. We have our own dashboards and metrics inside of the app itself, but there’s different ways you can actually slice and dice the logs inside Honeycomb which I think is pretty unique. I like that. So I’ve been enjoying Honeycomb from that perspective, and just getting more of the app logs in there would be kind of interesting, too. I look forward to that.
I look forward to – I guess I’ll tee up, if you don’t mind, your next episode then. So after episode 50 you’re having Mark on, from Fly, talking deeply about other specifics. Can you talk about what that’s gonna be about? What is that show gonna be about?
So it was literally the follow-up to this one… Like, take all the things that we’ve learned about Fly, all the things that we would like to see improved, all the things that are maybe coming in Fly, that would help us, things that we would like to know about, and how do we continue strengthening our collaboration? Because this is a first great collaboration, similar to Honeycomb, and I’m very fond of that. I think that was the one that really shines among all our partners, in that we can do things in a different way. And I really enjoy that.
[01:00:14.02] So what does the equivalent look with Fly? What about the upgrades, what about the build packs? What don’t we know when it comes to the Fly platform, because we come from Kubernetes? And maybe we’re doing certain things in a way that in Fly are sub-optimal. So what are those things? What can we do better that we don’t even know about, that the platform solves for us?
And this is, you know, going back – I know that we’re holding it wrong, but I don’t know what right looks like. So can Mark tell us what right looks like?
Right. Maybe cert-manager. Maybe this whole scenario around certificates could be like “Okay, we can actually hit this flag and enable you to see your private key. And you can take it elsewhere if you want to. So we manage it, but we’ll share that private key with you. Either behind the scenes, or in the UI”, if that’s… Maybe not a security measure, but he’ll probably have some sort of reasoning for that. Like Jerod had said, there’s a reason why they’re doing it. And Jerod, maybe you get some of your feature requests right away. It’s like, Mark listens to this show before episode 51, and “Here you go. Here’s some presents. It’s not even Christmas.”
Well, I’d love that.
Yeah, I’m excited. I mean, episode 50, big deal. A year later we’re on a new platform, we’re saying hello to new partners, which is amazing. I like Fly, I like Kurt, I like the team; a lot of respect there. And I think what’s next for me really, the big thing is just hope, is that we can help improve the Fly platform, we can help improve our platform, and then as we continue down that journey, we’ll share that story here on Ship It.
And if as a listener you’re running Kubernetes, you’re managing Kubernetes, but maybe at a level higher up - I’m thinking Cloud Run - and you want to partner with us, I’d be very keen to trying out another origin. Fly is great, we like it, but it’s always a strength in diversity. Can we see what does the alternative look like? Can we still remain plugged in the ecosystem? Which - let’s be honest, the majority are using Kubernetes, and if we don’t use Kubernetes ourselves, the best one out there, will we have the same insights? Will it still be as relevant? Will I be able to have the conversations that I wish I could have with some of the future guests on the show?
So if you know a platform that does Kubernetes really, really well, and maybe it’s like a layer up from that, and you would like us to run a Changelog there, reach out to us. I’m very keen to have that conversation and to try it out, and to see how it compares… Because you know one of my sayings, “You always want two of the same thing”, in this case origins.
So Fly - it’s amazing just to have Fly, but what if Fly goes down? And it will happen, let’s be honest about it. Fastly did. It can take five years, it can take ten years, maybe less; we don’t know. That’s the one thing which we don’t know. But we do know that it will go down at some point. So how do we mitigate against that? What is the plan B? Because right now there is no plan B, right? It’s Fly, or – I mean, we have Fastly in front. Great.
[01:03:04.22] You’re speaking of like business continuity, kind of fail-over type situation, where if the platform Fly fell down, there was an outage, fail-over, switch-over, the site continues to be deployed? That’s what you have with a Kubernetes system, is you can move to a different origin, as you’re saying.
Just another origin.
Right. So plan B is another origin, and maybe the other origin is still a Kubernetes origin.
And let’s be honest, the world is moving multi-platform. That’s what’s already happening. And some systems are so complicated that it takes years, and I don’t know how many hundreds or thousands of engineering hours to get it there. Our system is a lot simpler. And we’ve been improving it, we’ve been making it as portable and as small and as streamlined as possible, so it shouldn’t be that difficult to run it elsewhere. PostgreSQL will have a single instance; now we have replicas as well, we have readers, and all that is managed, so we can connect to that. We may need to set up a WireGuard tunnel, but that’s okay. Not a problem. We can do that. So the database will be the same, but can we run it on a different platform?
Maybe.
We can dream. If you’re not dreaming, what are you even doing?
That’s right. That’s right. If you’re into that journey, and you’re listening to this show and you haven’t subscribed yet, the easiest way to do that is to go to Changelog.com/shipit, and there’s all the ways to subscribe to the show there.
So if you’re digging this journey so far, or if you’ve been here for all 50, thank you. If this is your first, because somebody was like “Hey, there’s this show, and this migration, and this and that” or whatever - welcome. Go subscribe, and join us on this journey.
And if you’re at KubeCon EU Valencia, I’ll be there. Look me up. If we want to record something, we can go for that, and just have a conversation. I still love Kubernetes, even if we’re on Fly. My heart still beats Kubernetes; every other beat is Kubernetes and is cloud-native, so we still like that very much. So yeah, let us know what is new and what else we don’t know, because I’m sure things are changing all the time.
What’s the best way to reach out to you?
Well, Twitter. @gerhardlazu on Twitter. Also on the Changelog Slack. I check it out at least once a day. Or request an episode, that’s another way. Or gerhard@changelog.com. That also works.
And we’ll have this in the show notes, too. you mentioned issue 407, which is quite thick. I mean, there’s a lot of details there. So as an encouragement from here, reach out to Gerhard about KubeCon EU and what’s happening there, and then also dig deep into issue 407; we’ll link it up in the show notes. There’s lots of details to go through there. So if you just enjoy the details of this kind of migration and you want to learn from our learnings, then it’s about to go.
Yeah. I hope you enjoyed the show, Simey. Tell us what we should do next. Simey de Klerk We are listener-driven.
Not Rust.
Not Rust, okay. Maybe Go. So okay, microservices, Knative. Yes…! Knative. Cloud Run. I can already see it. Someone stop me.
Slow down, slow down!
Alright… Thank you, Adam, thank you, Jerod, for joining me. This is a great pleasure, always having you, always doing a kaizen; they’re so different, so special to me. Thank you very much for being part of the journey.
Thanks for having us.
I’m looking forward to the next one.
Yes!
Kaizen.
Kaizen!
Kaizen.
Our transcripts are open source on GitHub. Improvements are welcome. 💚