For our last 2022 Kaizen episode, we went all out:
- 💪 @jerod outdid himself in the number of improvements shipped between Kaizens
- 🕺 A few of our listeners contributed → prompted us to create a new contributing guide
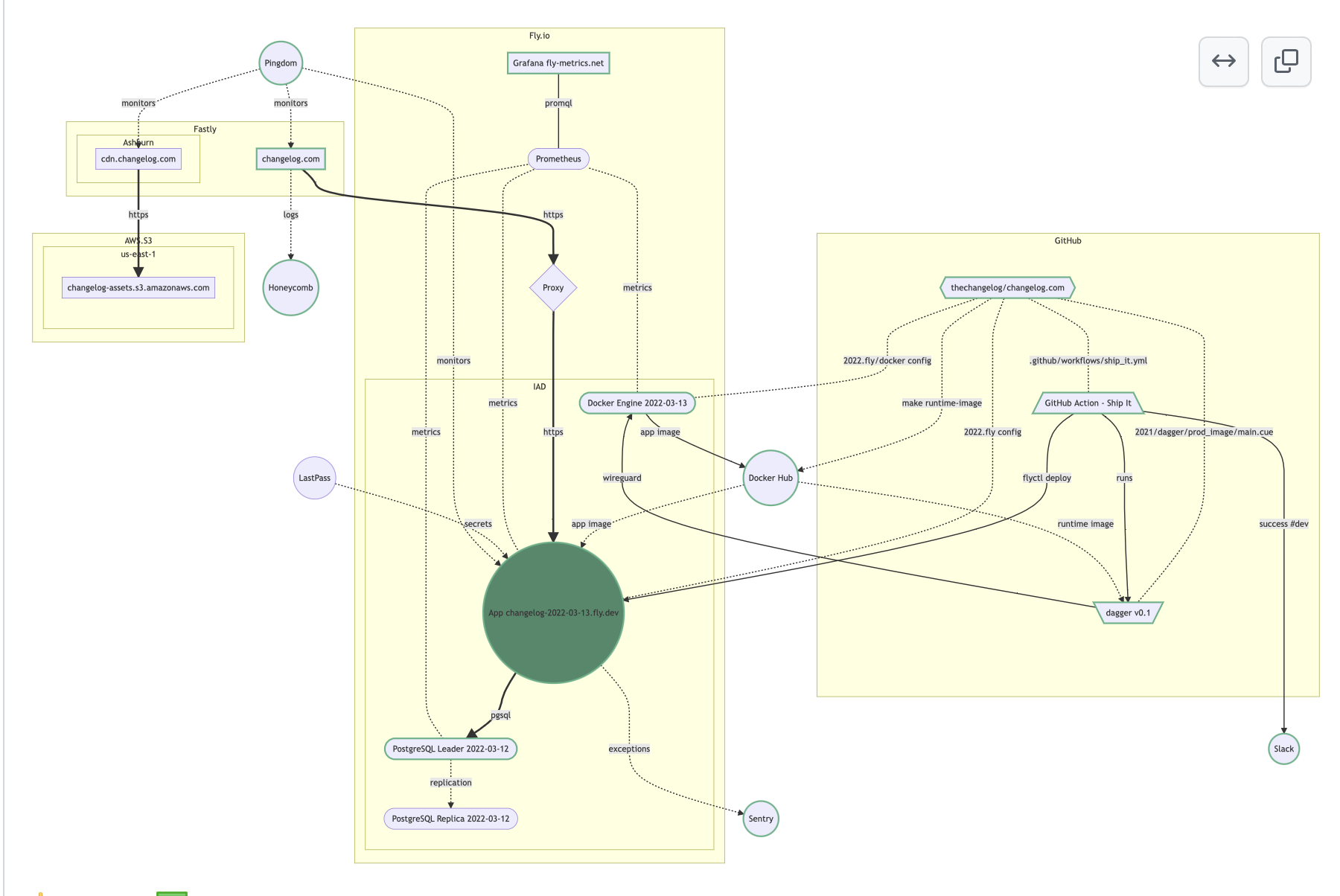
- 🗺 We now have a new infrastructure diagram
All of this, and a whole lot more, is captured as GitHub discussion 🐙 changelog.com#433. If you want to see everything that we improved, that is a great companion to this episode.
Featuring
Sponsors
Sentry – Working code means happy customers. That’s exactly why teams choose Sentry. From error tracking to performance monitoring, Sentry helps teams see what actually matters, resolve problems quicker, and learn continuously about their applications - from the frontend to the backend. Use the code CHANGELOG and get the team plan free for three months.
FireHydrant – The reliability platform for every developer. Incidents impact everyone, not just SREs. FireHydrant gives teams the tools to maintain service catalogs, respond to incidents, communicate through status pages, and learn with retrospectives. Small teams up to 10 people can get started for free with all FireHydrant features included. No credit card required to sign up. Learn more at firehydrant.com/
Sourcegraph – Transform your code into a queryable database to create customizable visual dashboards in seconds. Sourcegraph recently launched Code Insights — now you can track what really matters to you and your team in your codebase. See how other teams are using this awesome feature at about.sourcegraph.com/code-insights
Notes & Links
All episode notes are in GitHub discussion changelog.com#433. Feel free to add your thoughts / questions!
Chapters
| Chapter Number | Chapter Start Time | Chapter Title | Chapter Duration |
| 1 | 00:00 | Welcome | 00:54 |
| 2 | 00:54 | Sponsor: Sentry | 00:41 |
| 3 | 01:35 | Intro | 06:59 |
| 4 | 08:34 | 24 Improvements! | 03:56 |
| 5 | 12:31 | PR 415 | 02:59 |
| 6 | 15:30 | Fly & Docker | 03:14 |
| 7 | 18:43 | PR 430 | 03:35 |
| 8 | 22:18 | Sponsor: FireHydrant | 01:18 |
| 9 | 23:36 | Spotify | 01:39 |
| 10 | 25:15 | You, the listener | 02:05 |
| 11 | 27:20 | PR 431 | 03:20 |
| 12 | 30:40 | DCO | 02:40 |
| 13 | 33:20 | Passphrases and 1Password | 07:03 |
| 14 | 40:24 | From LastPass to 1Password | 02:57 |
| 15 | 43:20 | Sponsor: Sourcegraph | 02:22 |
| 16 | 45:43 | Discussion 433 | 05:59 |
| 17 | 51:42 | Mermaid text 👀 | 05:53 |
| 18 | 57:36 | Dagger | 05:48 |
| 19 | 1:03:24 | Wrap up | 04:23 |
| 20 | 1:07:47 | Outro | 00:52 |
{kind=link}
Transcript
Play the audio to listen along while you enjoy the transcript. 🎧
Our last Kaizen, episode 70, with a single big improvement, IDv3x Elixir library, with Lars… You know it, it’s episode chapters. So now you can enjoy episode chapters, because of that one single improvement. This is Kaizen episode 80, with Jerod and Adam…
What’s up?
All good.
All good.
But Jerod has 24 improvements in this episode. Okay, I just have to start there…
Woo-hoo!
How did you manage that, Jerod?
Kaizen. I’m just kaizening it, I don’t know… There are a lot of little things – everytime you do a big release, or big feature, and you drop it in, there’s always a bunch of little things, that either you’ve been putting them off, because they haven’t been as important, or they’re related to the thing that you shipped, because it wasn’t 100% baked… As was the case with chapters. So lots of little improvements to chapters, and then once you get rolling, you know, you just keep improving all areas of the application… And I just – I hit my stride and made some commits to this one.
Once you pop, you can’t stop.
That’s right.
They do say that about Pringles…
Yeah, exactly. We have to – anyways, the point is, once you start improving, you can’t stop.
Do you think the word “continuous” and “always” are similar, or synonymous? Continuous, always… They’re kind of the same, right?
I would say they’re definitely similar, but yeah…
They’re pretty close, right? So we have an ABR method elsewhere; Always Be Recording. So it could be ABI, Always Be Improving.
Always Be Shipping.
Always Be Shipping. ABS. This breaks.
ABI, Always Be Improving. I like that. I think we mentioned it in a previous Kaizen. Anyways, back to the improvements… Jerod - I cannot believe… So we started doing a few things differently for this episode. The first one - there’s a GitHub discussion; we’ll come back to that later. Secondly, we have GitHub tags for every single Kaizen, from Kaizen one… And now we can compare them. So it’s comparing from Kaizen 7 to our main branch, what are the differences? A lot. Jerod has been killing it. And you have so many things that you meant straight into production, rather than PRs, rather than anything like that. So what was your thinking there?
Why do you mean? Like, why don’t I open pull requests and then merge them myself?
Something like that, yes; to keep things together.
It’s the same reason why I don’t run a Docker container on my machine while I’m coding. It’s unnecessary ceremony. When I’ve already done all the things, we ship very fast… So if I ship a bug, I can very quickly fix it, which gives me the confidence to just go straight live and just see what happens. I don’t know… Should I be doing these pull requests if it’s just like a bunch of little things and I know what’s going on and no one’s really gonna review my code except for myself? Should I be doing that anyways, for some sort of happy trails?
No, I don’t think so.
okay.
I think that’s one of GitHub’s best and worst features - pull requests. Why do I say that? It forces you to create a branch, it forces you to have some code which is running in parallel to the main branch… And what that means is what do you do with it? How do you deploy? You have to set up a lot of stuff - preview environments… The list goes on and on. Staging… Whatever people call it, it’s really complicated. What you actually want is to group commits together, and maybe have a discussion on those commits. But they shouldn’t be on a separate branch. That would be my ideal, where commits that are grouped together are good, because we can see how something evolves; we can have a discussion about it, and I try this bug… So how many follow-up pull requests have people done, the ones that are listening to this podcast? I’m sure many… Because you ship a pull request, you think it’s finished… Ah, there’s a new bug. Okay, so there’s a follow-up pull request to my initial pull request, because I forgot about this thing, which you have to merge again, and so on and so forth. So I wish GitHub behaved differently when it comes to pull requests.
Should we dig into that a little bit? How would you do that then? What would be the experience for that? Because wouldn’t branches be the most logical way to natively get – you know, in the Git realm, not the GitHub realm… Separate your main branch, your master branch, or whatever, from other code. Just to give it its own lane, so to speak. How else would you group commits?
[06:13] Well, if you could attach a commit with some metadata to a pull request, which is just a virtual object, and you’re done, the pull request is finished, when maybe you flip a feature flag. And by flipping the feature flag, that feature is live. Everyone has access to it. But you keep shipping into production, you don’t enable it for everyone, and when it feels like it’s done, you’re done. If there are still bugs - well, guess what? You can do follow-up commits, attach it to the same pull request, and it’s still like the same logical grouping. I think that would make more sense.
But it still lives in the master and main branch, basically.
Yeah. Everything goes on the main branch, yes
Okay.
So does the grouping only exist then on the platform? Like, it doesn’t exist inside of Git? Or you’re hoping this would be a feature of Git itself?
Maybe both… I mean, I don’t know who has the appetite for this, but… Pull requests are a GitHub thing.
Yeah.
They don’t exist in Git. Branches exist in Git. So if pull requests were first-class in Git, I think that would make more sense.
Right. Well, the very first users of Git did not use historically - I’m not sure what they do now - pull requests; they used patches. So the Linux Kernel, for which Linus made Git to collaborate around, they’re all about – they were all about (I’m not up to date), emailing patches.
Right.
So like you said, pull requests were very much an invention of GitHub, and have been copied; I mean, they’re called merge requests over on GitLab, which I think is actually a more accurate name… But sorry, pull request has the inertia, so it just doesn’t quite land the same way, but they’re pretty much identical. Thoughts on different platforms, neither of which were a Git-native action.
Yeah. I do like the pull request representation, where you can have a discussion, you can link to other pull requests, you can link to issues, you can solve issues, you can add images… I use that a lot; screenshots, videos… A lot of things. So it’s great for a discussion. I find that richness, sharing that information and being able to refer back to it, so useful.
Right.
And it’s like a biography too of what happened. So going back to triage, or learn from mistakes, or learn from positive things, too. You can totally do that with a well-done issue, or a well-done PR.
So that felt like a segue… Back to the 24 improvements. I’m looking at the list right now, there’s so many things there.
Do you wanna talk about any of these in particular?
Well, which ones do you wanna talk about? …because they’re all yours…
Right.
Which felt interesting, which felt unexpected…?
Unexpected?
Mm-hm…
I’m just kidding. Go ahead. Keep going.
So commit 19, when I fixed the bug, that was unexpected, because I didn’t expect there to be bugs in my code… Um, so a lot of this was follow-ups to chapters, and kind of finishing or rounding out the chapters feature, allowing for the attachment of images to chapters, adding chapter support in the on-site player, which is still a first draft of the feature, but was a small enough feature that I could do it in an afternoon…
So all that chapter-related stuff… I also did some kind of one-off things that I’ve been waiting to do. All of our Medium posts go to Scribe now, which is just a quality of life improvement for our readers when we link to Medium… Because Scribe is basically – remember InstaPaper, where you would take a URL and then get the InstaPaper view? Now built into mini-browsers; Safari has the reader view… A lot of them have that… Scribe is kind of like that for Medium posts, where you can just take the post, direct it to Scribe instead, and it gives it a nice reading experience without all the Medium cruft that we don’t like so much… Because - gosh, I hated linking to Medium because the reader experience sucks, in my opinion. But there was so much good content there that it was compelling. And I didn’t wanna turn people away just because they’re on Medium, but we used to a little bit; I’d email them and say “Hey, write this on your own domain and I’ll link to it.”
[10:18] Now, this is a much better answer. If the context is good, we wanna be able to link to it, and now we have just a better reading experience. So that was one that I’d been waiting to do, and once chapters was done, I kind of had no excuse not to…
Notably, we switched to – or we didn’t switch to, but we started to integrate the Open Podcast Prefix Project, OP3.dev. We had a whole show of our Backstage podcast talking to John Spurlock all about that project, and we told him at the end of that show “Yeah, we’ll give it a shot. We’ll send you our data.” And so I did that pretty easy change, but hopefully a profound one… And then just a bunch of cleanup; things that we didn’t need.
One thing that we get a lot of is spam. And the reason we get a lot of spam is because historically podcast RSS feeds required you to have a working email address in your feed. So editors [at] changelog.com for years and years and years has existed in all of our feeds… And all these podcast spammers who either wanna come on your shows, or wanna sell you something - they just crawl all the indexes (Apple Podcasts requires this), and they grab all the email addresses of everybody who has a podcast, and they email you as if they’re your best friend. And you know they’re emailing 45 million people, or whatever it is…
Until recently, Apple actually removed that requirement, and so the iTunes owner element is no longer required; it actually doesn’t do anything… And so we can remove that, which means we’ve removed that email address from our feeds, which means less spam over the long-run, which is exciting. So little stuff like that…
Yeah, a lot of amazing improvements, I have to say. Even though they read – like, it’s one-liners, and I enjoyed very much seeing them in our dev Slack channel as they keep rolling in, that’s very nice. I really enjoy that, by the way. That’s one of the things that we’ve improved for Kaizen 7. And seeing those improvements coming through was very nice. But it’s like 10 minutes, 15 minutes here, and they add up over 2,5 months; there’s a lot of stuff there, so it’s great to see that. Amazing.
Talking about contributions and improvements, I wanna give a shout-out to Josep, Luis, Giralt, Glakost, Pep for short, maybe I should’ve started with that… Pull request 415. That was opened since May 2022. So May earlier this year. That’s been open for a while… He is a Ship It listener, and I think it was in response to one of the Ship It episodes… Thank you very much, Pep, for that pull request. And I noticed it in August, and I finally merged it for Kaizen 8. So that made me very happy to get it in.
Now, he was asking whether he can get a Kaizen T-shirt, and at the time we didn’t have them in the merch store, but now we do. Now, I’m wondering - you two are already wearing them, so that’s great. I’m still waiting for mine… That is amazing. I’m wondering if we can send maybe Pep a Kaizen T-shirt… What do you all think?
Let’s do it.
Let’s do it.
Nice.
Ship it.
Okay. Yes, please.
Ship that shirt.
Alright, Pep, so hopefully you’re listening to this; and if not, that’s okay. We’ll get your posting address somehow; we’ll see how we get that T-shirt to you.
Well, it’s easier than that. We just give him a coupon code to the merch store, and they go there and use the code themselves, order whatever – they may not even get the Kaizen shirt, you know? He may get something else.
We have his email. We can spam him. Okay, so Pep, you’ll be spammed…
[13:53] This is the kind of spam you wanna get, you know?
Oh, yes. That’s amazing. Okay. Cool. Now, someone else that I wish we could send a Kaizen T-shirt to is Noah [unintelligible 00:14:03.00] He has two pull requests. Pull request 428, we got it merged, where Elixir was bumped from 1.13 to 1.14.
Right…
And Erlang OTP from 24 to 25. Now, if this sounds familiar, that’s exactly what we did for Kaizen 7, the previous Kaizen, and Noah did it for Kaizen 8. How amazing is that?
Now, I tried to merge that one and failed… I think there’s more to the story here. Maybe we’re getting ahead of ourselves… But you finally got it – I couldn’t do it; I wasn’t cool enough. Gerhard, you’re cooler than I am, so it ended up landing eventually… But I think we should definitely send Noah a T-shirt, too. I mean, if Pep gets one, Noah’s gotta get one, right?
Definitely. Those are the two noteworthy contributions. Great improvements, thank you both.
Now, there is a related pull request where I explained how to use the Docker that we have deployed on Fly.io to build images. But the gotcha is that if you docker login, and you docker login locally, targeting a remote Docker engine, the login, the auth gets configured locally, not on the remote engine. So what that means is even though you appear to be authenticated, the remote engine cannot push images, because remotely it doesn’t have that auth token, so it can’t talk to the registry, in our case Docker Hub. So all of that is going to improve; all of that. But I think we’re gonna leave it for a bit later.
Okay. So let’s focus in on this Fly/Docker situation, because this is very cool… This solved a painpoint in my life, which has been there for years, which is local Docker for Mac slowness, having to have it installed, having to upgrade it, deal with it… And just the disk space usage of that sucker has been significant. And I don’t have to do that anymore, because we run our Docker on Fly, and I just set like remote server or something; there’s some sort of environment variable you set…
Docker host…
Docker host.
Export Docker host, yeah.
And because it’s client server software, I just have to run the client, the server is on Fly, all of the nasty bits that I don’t want on my machine are on Fly… And that’s just super-cool. I’ve been using it a lot, because I’ve been setting up some Mastodon stuff on Fly, which was using Docker containers, in addition to our stuff… And that’s super-cool. Is this just common practice now, that I wasn’t aware of, Gerhard? Was this a grand idea of yours? What’s the deal here?
Yeah, I don’t think it’s common practice. This is actually, if anything, not common, because of issues like I mention… Like, your client is authenticated locally, but the remote engine isn’t, and weird things like that; definitely edge cases… And the reason why I set this up was for our CI. So I think Kaizen 7 or even Kaizen 6 - we had the issue where we were targeting the same Docker engine; that was running in my shelf, I kid you not. It’s a very beefy machine, but I just run it in my shelf.
That’s right. It was at your house.
And the GitHub Actions runner was connecting using Tailscale to that host. But the problem is I was using the same Docker engine for my local development, this, that and the other… And then there issues when the CI was trying to use it, too. So again, there’s a pull request; I will link it in the show notes.
So to fix that, to improve that situation, I’ve configured a Docker engine on Fly. Again, I think it was in a previous Kaizen where this was mentioned… And I added pull request 426 - that’s the last one, September 22nd; that’s when it was merged - to basically capture how to use that Docker engine on Fly.
So not only our CI is using it, we are using it too, but again, we have to be careful with that, because we can create issues if we share the same Docker engine. So that’s something to improve further, for sure.
[17:50] Well, it’s a cool hack, and I will say, it’s a better hack than the previous one, which was to run it from your shelf. You know, we’re pretty open here, and open to criticism, open to ridicule… You know, our code has always been open, our infrastructure has always been open… We don’t get easily embarrassed; that one is like darn near – like, seriously, guys? You’re running your production business websites and stuff with a –
Just a CI. It’s okay. [laughs]
…just a little bit of that infrastructure in Gerhard’s office?
Yeah, pretty much…
…or closet, or wherever that shelf exists… So I’m glad – I think that’s definitely a Kaizen. We’ve continuously improved from there, and we’ve moved it off there into a Fly VM.
This is going to improve even further, but I think we should leave that to a bit later; Dagger has a lot to do with that, and all this year has been about Dagger for me, so… Anyways, there’s something big coming, so let’s leave it for a bit later.
An even bigger improvement from Noah that is waiting to be reviewed and merged is pull request 430. He added support RSS feeds for specific topics, especially combining current feed and topic functionality… Now, this was branched off pull request 390, that was opened last year by [unintelligible 00:18:58.24] So there’s two PRs in one, and I think we mentioned this briefly, maybe offline. What do you think about that one, Jerod?
I’m definitely down with the feature. I think I approved the feature conceptually years ago, when [unintelligible 00:19:16.05] began working on it… And I think he got some stuff working. It wasn’t quite there… I think the implementation - I code-reviewed the implementation and said “Why don’t we do it this way? We already have a feed controller. Let’s just reuse that, versus putting it over in the topic controller area of the codebase.” And then life happened, and he was just never able to get back around to it, never passed my threshold of things that I’m gonna actively work on, so it just kind of sat there. So it was super-cool to see kind of a hand-off of this feature to somebody else… And I haven’t looked at this PR recently, but spiritually, I’m there. I’m definitely gonna merge the feature when it’s ready to go. I think it’s cool. Certain people just care about certain topics, and it was like “Why not have a feed of –” We have feeds, they’re just HTML feeds of topics. So why not have RSS feeds of those topics? It’s a no-brainer, so - happy to have it in there.
It’s a long-time WordPress feature, basically, to have your tag or your topic be feedable, essentially. So I agree with the usefulness of it. Because for a while there when we were on WordPress, we would encourage that. That’s [unintelligible 00:20:20.09] tracked Ruby by just tracking the tag via RSS, that way you don’t have to get the whole kit and caboodle; you can just get the one thing… Which is what kind of everybody wants, right? Just a slice, not the whole pie.
A similar feature is just author-based… Now, we don’t post that many posts, but even news perhaps… Publications bigger than ours, I’ve definitely had certain authors that I appreciate, but I’m not gonna subscribe to The Verge’s feed. I’m just not gonna do it, because they’re gonna publish 12, 15, 20 things a day, and overwhelm me. But this author - I wanna know when they write something new. And The Verge did not provide that as a feature. I think Feedbin actually allowed me to filter down a feed, which is kind of cool… But author-based feeds - I think that’s something that WordPress also does by default, and I would definitely appreciate that, even on ours… Even if two people use it. Still, it’s a pretty easy feature once you’ve already done it for topics; it’s the same concepts on a different object… So I would also merge something like that.
Nice. Does it mean that Kaizen can have its own feed?
Kaizen can have its own feed, because there’s a Kaizen topic now, right?
Yes, there is.
Yup, so that’s all it needs.
Okay… That’s really cool.
Yeah. Like, if you only like the Kaizen episodes - boom. You don’t like any of Gerhard’s interviews… What’s wrong with you?
Exactly. I don’t know. I don’t know. But that’s fine. [laughter] I run things on my shelf.
The consumer isn’t always the listener. It could be somebody who’s publishing a web page. Similar to the way we did when we were on GitHub [unintelligible 00:21:49.05] forever ago. Like, they would just pull from the podcast tag only. There was one feed, so they would filter it. So there could be a usefulness, where it’s like, not not liking it…
Yeah.
So I’ve been dabbling into our Spotify… This is a bit upstream from where we were, but… You know, Spotify has a lot of people who never discovered us before, so like, you wanna be there, you wanna be visible… You know, new people listening to your stuff is cool… So they have playlists inside of Spotify, and I’ve been over there creating certain playlists. Like, it’d be cool to have a Kaizen playlist in Spotify, but I don’t wanna go into Spotify and create a Kaizen playlist, and manage it… It’d be cool – this is never gonna happen, but a Spotify robot is what we need to basically mirror our topic feeds into different indexes… And then you could have – for instance, our dev game shows is a manual playlist I created over there for our Frontend Feud episodes and our Go Panic episodes… And it exists over there because I go over there – we do them infrequently enough that I go add them. I’m like “Here it is. It’s dev game shows.” Well, that should be a topic on our platform that then just gets syndicated into places, and then we’d be cooking with gas… A Kaizen feed on-site is awesome, but if that could be mirrored into Spotify…
Oh, yes.
…even cooler.
We can dream… We can dream.
I would definitely send a Kaizen T-shirt to a pull request that did something like that.
Yeah, the Kaizen is young; Ship It is young. Lots of things could happen, yeah.
Yeah. A publishing bot.
Cool. Now, all these improvements, all this talk of improvements - I’m sure you, dear listener, are thinking “Okay, I want to contribute. How do I do that?” Pull request 434 was created for that. It’s a new contributing guide, and it includes how to set up our app locally for our development. It does not involve Docker.
No Docker.
So Brew, that’s all you need, and I did this on a clean Mac, macOS 12. Linux help is wanted. So if you want a Kaizen T-shirt, there’s a hint for you.
[laughs] These are like – you put a Kaizen shirt on a stick and dangle it in front of people.
Pretty much. [unintelligible 00:25:56.09] [laughter] Well, by the way, you can also buy them. You know, this is a free one, just to make it clear… How many do we have on the store, Adam? What’s our stock level like? Do we still have any left, by the way?
[26:09] We do… It’s not massive, but it’s enough.
Okay.
But now that we have this all set up - I mean, re-stocking is easier than it was the first time, when we had to actually create the design, submit the design… Now it’s kind of in the system, and re-stocking is not a huge problem… But we’re definitely getting low, because they’ve been on the store for maybe six weeks, and we’ve just started talking about it, and they’ve been selling. So…
Okay. Nice
…either buy now, or code now…
Yeah. [laughs] That’s a good one. Contribute. Contribute to changelog.com, the repo.
So we’ve got – yeah, we’re getting kind of low already. We’ve got seven each of large, medium and small, 11 of XL, and 15 of 2XL. But I think that 2XL is not correct. [unintelligible 00:26:55.16] so I think that could be more like 11 of that one, too. So we’re pretty shallow on our stock for it. So if you wanna get one, contribute, or if you wanna buy one, do it now.
Plus, Gerhard needs one.
One? I thought four. I’m getting four. Five, actually. For every day of the week.
One for each.
Yeah. One for each. Cool. So coming back to 431… I know that, Jerod, you’ve reviewed it… You had the question about the DCO, why do we need it and what it is… What did you think of that PR overall, apart from the DCO? We can go into that next.
Yeah. No, I think it’s great. I like the idea of putting all of our contributing stuff in its own file, its own place in the repo… The readme was getting excessively wrong. It was pretty outdated. It probably still kind of worked, but nobody’s really actively using that flow. We all develop locally anyways, so why have a flow for contributions that’s different from what we do?
I think the reason for that was cross-platform compat. We want everyone to be able to contribute. But in reality, it wasn’t good. So this is better. I do think it’s a step. I would rather have a better story, and I think there’s lots of cool opportunities. Have you guys seen Devenv? That’s a Nix-based one that I saw just yesterday. I put it on Changelog News. Potentially a way that we could do it… It’s cross-platform. It’s native, it’s not inside containers…
Now, all of our stuff is pretty stock. Like, okay, Elixir and Erlang is a little bit rare, but other than that, it’s Postgres, and it’s ImageMagick and Node, right?
I don’t think – do we even need ImageMagick? I don’t think we need it.
I mean, you don’t need it for development unless you’re actually working on that feature. The Apple run without it. But you do need it just for like avatar resizing and stuff… So to be 100% running the site you would need it, but for 99% you would not need it.
Cool. So what I’m going to do now is do “Remember to add ImageMagick.” I’m leaving myself a comment.
On the PR.
On the PR.
Put that in the contributors guide as a dependency.
I’m looking at the readme that you changed, so I’m excited about this, because I’ve been waiting for a more thorough guide, because I’m tired of asking Jerod, and he’s probably tired of asking me to help me set up my local setup, and it’s always like “Do I have all the right steps? Help me understand what the specifics are like. Do I need ImageMagick, for example?” What do I need to have to just contribute small things, like footer changes, or other changes that I can take care of, that I tend to push out, because I don’t have a dev environment set up…
So I’ve actually been digging into my own dotfiles and automation and stuff like that, because I just did a clean install of a Mac, just for the fun of it; so we’re kind of like right in the same spot, Gerhard. So I’m gonna go through this myself… And I’ll be your first Guinea pig, because I’m excited to do this.
You know what - I’m going to add you as a reviewer on this pull request. See? Pull requests are really useful. Super-useful for stuff like this… To get people to look at it, try it out, see what works… Like have that conversation, which is around a specific issue.
[30:05] To be honest, I would have liked this to be already in; I would have preferred that… Because if something is not right, that’s okay; we can just iterate in the final place. We don’t have to keep it on the side, because it’s just the inventory.
Yeah, we can merge it, and then if you find changes, follow up.
But then we need to submit a follow-up pull request, so that’s the most annoying part…
Ah, come on…
Oh, my gosh… This is where I guess it would be nice to live in master or main, depending upon the age of your repo, for example, where your initial idea we talked about early in the show kind of plays [unintelligible 00:30:32.26] where it’s like, separate branch, separate pull request… It kind of gets kludgy UX-wise.
A question on the DCO… Is that in line with or similar to being verified, like your commits being verified? I know that this is different, but is it in the same realm? Would we like to have verified commits? Because I know, Jerod, you’re not a verified committer. You commit code that – you’re not verified.
I’ve got a bunch of open tabs right now…
Okay… I can help you with that. It’s really easy. If you already have 1Password, it’s ever super-easier. They’ve made some cool stuff… I love the 1Password SSH integrations; if you have a TouchID Mac and you’re not doing 1Password… If you’re familiar with this, Gerhard, please praise it up, because I love it.
I am.
You literally biometrically sign your commits with your finger. And you can SSH into a machine, or commit to your Git repo even locally before you push it, your commit, locally. [unintelligible 00:31:25.25] is signed via a biometric press on 1Password. So cool. I don’t recommend it for machines that are remote, because you literally have to have the UI… Because if not, you’ll get stuck in the prompt. But then they have some instructions on how to sign your commits, which is like a couple of additions to your git config… And you’re off to the races. It’s really, really easy.
Well, I’m smelling a pairing session here… And if not, then I’m disappointed. [laughter]
Yeah, it’s super-easy, and I’m loving it, honestly. I’m just so stoked with the stuff they did. I have some improvements I’d love to see them do… But they’ve made some great strides already with biometrically signing Git commits, and SSH-ing and using your SSH key. So cool.
Now, can’t I just take my GPG key and add it to Keychain, and not have to…?
That’s the old way. The new way is using the SSH key. So you can sign using the SSH key. GitHub supports it. GitHub will verify your signature…
So I already have an SSH key, is what you’re saying.
You do, exactly.
I’ve got a 10-year old SSH key just sitting right there.
That’s it. You put it in 1Password, do the configuration…
Oh, I was just setting up a GPG right now. So I didn’t need to set up this GPG key?
No. You don’t. No, no.
Doggone it…
That’s the old way. That’s the old-school way.
Do you rotate your SSH keys often, Gerhard?
Sore subject. Sore subject.
Sore. That’s how we started. [laughs]
I was gonna say, that’s a long –
Six years ago. That was like “Hey, Jerod, what should we do with this old key? You’ve gotta SSH.” [laughs] That’s how old it is.
I told you, we’re not easily embarrassed. In fact, it was so old… Was it Ubuntu - it wouldn’t let me SSH in.
Exactly.
It was like, “Nah. Your algorithm is too old.”
It’s too old, yeah.
It’s like, “A 10-year old SSH key? I’ve never seen such a thing. What is this thing?!”
I connect with so many machines. I don’t wanna have to rotate that thing… Not anymore. Now I connect to like nothing. But back then…
Tell me if this is overboard… So the one thing I don’t like about 1Password currently is that if you create the SSH key within it, it doesn’t let you create a password, which I think is super-weird. I like creating pass phrases for mine, but the user experience makes you put it in all the time. But I like to generate a 100-character passphrase for my SSH key… Because who’s ever gonna crack a 100-character passphrase? It’s probably just impossible. But is that what you do, Gerhard? How do you deal with these little things like these? Do you passphrase every SSH key? Of course, right? That’s the best security. Because if not, you only have the keys themselves to authenticate; if you don’t have a passphrase, it’s just – pair them up.
[34:03] So I used to have my YubiKey part with the whole SSH, and the YubiKey would use to generate the same passphrase… So my passphrase from my SSH keys used to be something that I knew, joined with what my YubiKey was generating.
I see. So something memorable.
Exactly, yeah.
So my brain is 1Password, basically. Like, I skip all the memory and me; I don’t have a clue what my passphrase is.
So that’s what I used to have. And the problem was there were issues with the YubiKey. It was not just the YubiKey, but it was like the software. The support was a bit patchy, and then there were like new upgrades… So I had this physical key… I’m still using it for 2-factor authentication as a back-up; I also have my phone… So if my phone gets lost, my YubiKey has all the OTP tokens. So that’s a separate issue. And also now 1Password. So I basically have triple redundancy for my [unintelligible 00:34:54.27]
Of course you do.
[laughs] As you would, right? Exactly.
As YOU would.
Yeah, as you would.
No, not me… As YOU would, Gerhard. [laughter]
Careful.
So coming back to 1Password, I do add my SSH keys there. You were mentioning not having passphrases… I can’t remember that. That was something recent which I changed.
Yeah, if you create it within 1Password, there is no passphrase created. It just creates it.
Right.
Now, I prefer to do it via [unintelligible 00:35:26.10] myself and import it, because I can create the passphrase myself. That could be maybe I don’t understand how to use it, but I don’t think so; I’m holding it wrong potentially, but I don’t think it creates a passphrase if you create the SSH key inside of 1Password… Which you can do. I think it’s super-cool, because – I mean, for those who don’t wanna touch the command line, that’s a GUI, essentially, for creating the SSH key. And you could choose RSA, you could choose Curve25519, whatever you wanna choose; you can go either direction. But I like to do it via [unintelligible 00:35:55.09] because I know I can create a passphrase there, and that I just import it into 1Password.
Yeah, that’s what I do, too. That’s exactly what I do, too. Yes.
I’m curious about your OTP stuff with the YubiKey, which I’ve never set up… But in terms of an app authenticator, I’ve been using UI Verify; I don’t know if you use this or not, but UI Verify to me is the best. I don’t know, will that focus for you guys?
I can see it. That’s really cool.
Oh, that’s my face. Sorry. It tried face ID first…
Yeah, I haven’t heard of UI Verify.
That’s all of the things I have in there, which you can sort of see… That blue line up top will rotate through… You can see how long you have to put the code in…
Where’s yours, Jerod? Where’s yours?
For those on audio, Gerhard and Adam are holding their phones up to their cameras to show each other…
[laughs] The OTP tokens.
…their current OTP tokens.
That’s right.
Quick, type that in before it rotates.
Yeah. [laughter]
So here’s my problem with those things… I upgraded my phone and I inevitably forgot that I need to back that sucker up, and I wiped my old phone, and then I lost access to like the six most important things in my life. And then I’ve gotta go to that site and I’ve gotta say “Hey, it’s me, and I lost my auth token verifier app.” And they’re like “Here, send us a picture of your photo ID”, and I do that six times. And I said to myself, “This might be worse [unintelligible 00:37:22.01]
That’s fine, you need a backup. You need a backup, seriously.
Aahh…!
Yeah. So you have it on your phone… 1Password. 1Password supports it, by the way. So you can have your OTP keys in 1Password, on top of your phone.
I saw that, but I didn’t know how it worked, and I was already using UI Verify, so I was like “Oh, I’ll just use this.” So I love that you’re – we’re gonna point to blog post or something, documentation that you’re aware of… Because I was like “Okay, cool, but I also have it here already, so I’ll just keep using what I’ve got.|
Yeah. Let’s share them post-show. But you definitely want – because as you mentioned, if you upgrade your phone… If something goes wrong, your phone gets stolen, what do you do then?
[38:01] Yeah, you’re totally locked out. You don’t regularly back up your UI Verify, do you, Adam? If you don’t, you’re gonna be in the same boat I’m in when I forgot to and upgraded. And I’m like “Dang it, there’s all the serious things… I can’t get into the most important things.”
That’s true. If I lost my phone and I wouldn’t be able to move the data over… You know, I’ll have to test that theory. But for me, my most recent phone upgrade, I just moved the data from one phone to the other. I didn’t do it through the cloud, I went from phone to phone, waited three hours, was patient… Because I feel like that’s the best way to get everything.
Yeah. I do a restore from backup…
I don’t like backups. I like to go phone to phone, direct. It’s problems with the cloud.
That’s yucky though, because any problems you had on that on that old phone are now on your new phone. Whereas if it’s just the backup, so the things that are good, it’s cleaner. But you don’t get that UI Verify, or… I was using Google Authenticator; same idea, right?
Well, it did come over. That was thing with this time; I was sharing that with you. It was like, when I moved my data from my phone to the new phone…
Well, phone to phone you would, yeah. But from the cloud you wouldn’t. Or I didn’t. And that’s how I lost access to so many things.
Well, there’s definitely some holes in the process, for sure. What I like about it, and what I’m sad that you don’t embrace this because of all this pain you feel, is that really it’s like the best way to be authenticated. Because your face is your face, your phone is your phone, as you know… And to me, things like GitHub, especially when you’ve got supply chain security issues… To me, if more people verified their commits, took the time to do – maybe we should write this blog post, Gerhard, because I feel like it could really help.
I think so.
I feel like if more people did just the verification on the Git commits, which is tied back to your SSH key, and there’s many ways you have to put that key into GitHub, it has to authenticate with them… Then they have the ghauth locally, which you can sort of authenticate to as well, which is all part of this process… It verifies your commits… Same thing for your SSH… It’s like, in 1Password it’s gonna be super-easy… But then also, this 2-factor authentication, these OTP codes - to me, that’s the best way to ensure it’s you. And it’s worth the pain. I wouldn’t do it for every app in the world, but more and more supported, so I’d just embrace it. GitHub in particular. Cal.com… Like, I don’t want people to not be me on Calendar; so Cal.com is there, Slack is there, GitHub is there… Unify, Ubiquity, that’s there…
Mm-hm. There’s still one pull request which I didn’t have time for… But between this episode recording and the episode shipping, there’s a week. So a week is like a year in my world, so I’m hoping that this PR will land… And that’s basically the migration between LastPass and 1Password. We’ve mentioned this in Kaizen 7, I think even before we’ve talked about it. So I think part of that we can also help everyone configure SSH via 1Password for those that use it. I use it, you use it, Jerod will use it… Yes, he’s nodding…
Well, we have it, so he should use it. I mean, it’s too easy.
Exactly. Yeah. And then once we do that, all the secrets… By the way, they are already in 1Password. I migrated them from LastPass to 1Password. I just haven’t finished all the integration with our infrastructure. With Fly, all of that stuff. But I think part of this should be how to configure your SSH key, how to sign your Git commits… Because it’s all this one tool. The problem is we are depending on a lot of things on 1Password. So what worries me is what is the backup plan; if that was to fail, what do we do?
Yeah.
I’m just being paranoid, I’m sure…
Because it is cloud-based, right. If they were attacked, if they were compromised… It is a centralized point of failure, and it is cloud-based, so there isn’t local copies. You have to authenticate to the cloud, and it’s all internet connection-required, right?
We do have local copies, but it’s all synced from the cloud. So if the cloud gets corrupted…
Right, precisely.
…the vaults would get corrupted. All the local vaults.
[41:59] I think you’re knocking on the door of an episode on Ship It with them, because I think – I’ve got questions for them. If you wouldn’t mind, I’d join you on that show, if you were open to a guest host, or whatever… Because I’ve got questions. There’s some things around the SSH authentication stuff, I’ve got questions about improvements… I’m just curious about where they’re going with it, because I think it’s great how it is currently; but if there is improvement (Kaizen), then I’m just curious how we leverage it in our infrastructure, and then also individually as users.
I like it. Definitely. So that’s coming up in PR form, and also in Ship It episode form.
If they say yes.
Well, someone will say yes…
Someone will.
Someone that knows 1Password really well will say yes.
We’ll take anybody. The janitor, you know…
Exactly.
“What do you know about the SSH integration?”
“What is SSH?”
One thing which I haven’t mentioned, and I wanted to; I was convinced that we’d start the episode with this - it was the GitHub discussion 433. A lot of things to be talked about, and other things are in that GitHub discussion. This is the first one of the kind. It’s on our GitHub, and it contains all the links, all the references, all the comments for what we talked about in this episode.
I’m trying something new; it’s an open-ended discussion. You can ask questions, you can even maybe suggest someone from 1Password that wants to join us on that episode. So everything is there. And it’s something that can be open for a while. We don’t have to close it. We can leave it open. And as we start preparing for Kaizen 9, we could create another discussion for Kaizen 9 ahead of time, just to give people a bit more visibility as to what’s coming, for our most loyal Kaizen followers. Just an experiment; we’ll see where it goes. But there’s a lot of stuff there.
Now, I must mention the diagram… But before I do so, does anyone want to mention anything else about this discussion?
Well, I wanna point out a few things for it. So when you go to this discussion, what Gerhard’s saying is like for each Kaizen we’re gonna have an open discussion; where normally these details were behind the scenes, sort of as preparatory show notes… They didn’t live in the wild, basically. So what he’s proposing and what we’re doing with this one as an experiment is to put it out there in the open, so we can use it, but then you can also follow along. But one thing I see there when you go to this page is this tag up there that says “Almost there.” What is this UI? Tell us about what you see there to know, like, is this current, is it stale, is it old? How do you know the status of this discussion, so that you can sort of play a part?
Oh, I see. Okay. So that’s using shields.io, and I think we’re also using the readme, which is basically those – how do you call them? It’s not bubbles… What do you call them?
Badges.
Badges. That’s it. Thank you. It’s the badges that usually people put in readmes, on GitHub you see them in repositories… So that’s a badge, and it’s like of a certain style. It’s like a traffic lights system, so it’s red when it’s work in progress, a Stop sort of thing; we are very heavily working on it. Orange - get ready; almost there. We’re recording it, or we are very close to recording it. And green, once the episode ships. So that’s what I’m thinking.
[48:18] Isn’t there labels in there and stuff like that too, though? Couldn’t you do that with labels? Because that’s like static in the –
Yeah, I could.
Right? Like, you’ve gotta manually update. You’re gonna have to go back there and say “Last updated on November -” not 15th, like it is now… 17th, or whenever you next go up there, and then change it from saying “Almost there” to “Shipped”, or… So it’s a very manual thing. Is there a way to do some of this stuff with like labels, and other things, or…?
Possibly… I mean, I’m adding a lot of content anyways to that description; so that is iterating, so changing a few characters is the least. There’s so many other things happening behind the scenes… Because I’m editing that discussion, the first one; I’m editing the first post, or the first comment, which starts the whole discussion… And a lot of stuff is being added, which is basically a summary of everything that we did in 2,5 months… And there tends to be a lot of stuff.
So labels - yes, maybe. It might work. But I think a badge - it’s good in that we are used to seeing badges on GitHub readmes: build is passing, build is failing… Things like that. So that is meant to signal the state of something. And I think a traffic light system is what we are familiar with from the real world, so I quite like that.
So if it was green, it’d be like “This is shipped” or “This is sort of done and baked. Feel free to comment, but what’s planned here is now done.”
And again, I haven’t figured out all the stages that the discussion goes through. I’m still figuring it out.
Right. These Mermaid flowcharts, though - I’ve seen lots of things… Even GitHub Universe came up recently with blocks, and stuff; this is similar, a lot of interactive things you could put in here. This is a Mermaid flowchart, like you’re talking about. It’s Markdown – it’s text.
That is one of my favorite features. Oh, yes. It is text. It is all text. So I’m using Mermaid.live to have that live continuous feedback loop as I work on the chart. So you can see how the chart changes in real time as you change something in the graph itself. The chart that Adam is referring to - and you’ll see it in this discussion, GitHub discussion 433 - shows our current setup. All of it. Fly, GitHub Actions, Sentry, DockerHub, LastPass… Everything. All the services that we use, how the app runs, PostgreSQL replication, the whole thing. That took quite a while to build, but I’m very happy with it because it captures a point in time, a snapshot of what we are currently running.
And OP3 was mentioned. Now, that’s interesting… I didn’t know how that interacts. So things like that we can add to this diagram, and we can also have links. So that means some of these elements - you can click on them and all of a sudden you’re in Fly, looking at the metrics that are for the app, directly from this. Obviously, you can’t authenticate; if you’re not part of our team, you can’t access that… But if you are, just click on that and there you are.
Also, when things change, we can submit a pull request that shows what changed in that chart. So this is something which hasn’t been open yet. This is a PR which we’ll – I’m thinking InfrastructureMD. And InfrastructureMD will have this diagram to begin with, that will capture our setup. I think that’s really nice. We can tag it… Kaizen 7, Kaizen 8… We can see how these things change over time. I wanna try it out.
The end result of this is super-cool. Definitely check the show notes, or maybe we can put it even as the chapter image of right now, so people with chapters can look at it.
The text is complicated, man… How did you learn to write this? Or did something generate this based on drag and drop things, like draw.io, or you wrote this yourself by hand?
I wrote this myself, yeah.
Handcrafted Mermaid text.
Handcrafted, exactly. All of it. Yup.
No GUI?
No. Nothing.
[52:15] Well, if you consider your editor a GUI…
So on one monitor I had Mermaid-js.github.io open, which is a reference for all things Mermaid. I had my flowchart open and I saw examples there… And on the other monitor I had Mermaid.live, which was split in half. The left-hand-side half was the diagram, which I was writing; the actual code, if you wish, the Mermaid DSL. And on the right-hand-side I could see a live representation of every single character press. It’s really nice. So I had instant live preview.
So as I was trying to capture the things which I was trying to put in this chart, I could see how it changes the graph. And once I was done, copy-paste it in our GitHub. That was it.
So is Mermaid.live a startup, is it an open source thing?
I don’t know, I just found it. “Oh, this looks interesting…” For hours and hours I was engrossed in writing Mermaid; learning and writing Mermaid.
Is that a third-party thing? I guess I’ll just go to the web URL and see what is there… But is that part of the flow of this? Or it’s just like they created a spec and some tooling, and then GitHub integrated their tooling? I don’t know what Mermaid.live is. Hold on, let me look it up.
Yeah, let’s look it up. I know it’s like – yeah, let’s check it. I used it, and it worked really well. It was like – I don’t know who created it; it’s like a live editor, Mermaid Live Editor. I think it’s hosted – this site is powered by Netlify, that’s what I see. But I don’t know who’s behind the service, to be honest.
Yeah, so when you load it up, it literally is the editor. Mermaid.live takes you to the editor that Gerhard just described. But there’s no like About Us, or Pricing page, or anything… Which I guess is kind of a good sign. Clicking through to the GitHub, it’s Mermaid-js that’s in charge of this thing… And they don’t have much about them either. There’s a Twitter handle that says “Create diagrams and visualizations with text. Official handle of the MermaidJS open source project.” So maybe that explains it right there. It is an open source project with a domain that hosts the editor, where you can get your Mermaid stuff. And then you just copy-paste from that into your markdown inside of GitHub, and it renders.
That’s right.
This is a blog post, Gerhard… This is a blog post.
I think it is, yeah. For sure. We used to do these every year, but I think there’s another one coming, for sure. December will be a good month, that’s what I’m thinking. Reminiscing, capturing – a good retro month, and capturing all these things.
So the one thing which I wanna mention is that the Mermaid in GitHub – and by the way, this GitHub markdown has native support for Mermaid. So we have like the [unintelligible 00:54:58.08] and you define it as Mermaid, and then you start writing Mermaid. And it’s like code; like, any code that you would put. So that’s really nice.
Mermaid.live has some extra features. So if you copy our Mermaid from this discussion and you put it in Mermaid Live, you’ll see some extra things, like for example icons. Fav icons for Fly, Phoenix, things like that. Yes.
Oh, snap.
So when you’re in the discussion you have that copy, so there’s like the two arrows pointing in left and right; that expands the chart. And the button to the right is the copy button. So if you click on copy, you can go to Mermaid Live and you copy-paste that chart, see what happens.
Trying it, trying it… This should have a button that instead of Copy says “Open in Mermaid”, or something.
That would be nice.
Uh-oh… It says “Long diagram detected…”
Yes.
Turn off autosync? Okay…
Yeah, I think it disables autosync. So you need to enable autosync, which is the toggle just above the code…
[56:04] I did.
…and then you refresh.
Cool. So for instance, DockerHub has the Docker icon.
Yeah. Pingdom has it, Grafana… A bunch of things like that. So I really like that.
Fancy-schmancy, Gerhard. You’re really going to the next level. You nerded out on this…
So some of these things can even be animated.
Oh, boy…
I didn’t have time… Exactly. Arrows that move and change… And before you know it –
You can show the path of a request through our system…
Yeah, exactly. That would be really nice, yeah. So that’s cool… I’m glad that you enjoy it.
I do enjoy it.
Cool.
I enjoy how much you enjoy it.
You have such patience for things like this. I do not have the patience… Well, sometimes I do. But I can see how you have good artifacts that come from obsessions. That’s what this is.
Isn’t this like a –
Passion for detail, that’s what I would call it. You wanna go further, and you keep refining and refining. I mean, you don’t do it in one session. Maybe you have three sessions. An hour, an hour-and-a-half… “Okay, so how can I improve this a little more?” That’s what it is. And you keep refining it, and you see that finally, like “Whoa! This thing is amazing.” And I spent maybe six hours in total, but broken down in 3-4 sessions.
Right. And there’s the little wins along the way, which gets you to the next spot, and then you realize you can [unintelligible 00:57:17.13] This is a quintessential yak-shave, isn’t it? Like, you just shaved this yak all the way down to its bare–
Pretty much… [laughs] It’s a nice yak.
It’s a mermaid.
It’s a mermaid, that’s a good one. [laughter]
Cool. Very cool.
Now, let’s talk about something that in a way captures my whole year. I know this was not meant to be retrospective… This is the last Kaizen, and I saved the best for last. So one of the things that we’ve been using since November 2021 was Dagger for our pipelines. Why Dagger? Well, it allows you to run CI/CD locally. It allows you to run the pipeline locally. And the reason why that’s nice is because you don’t have to commit and push to see what is the effect of this change. You can run the pipeline locally.
And then when it comes to commit and pushing, guess what - your CI/CD system, whatever it is, it will run exactly the same pipeline.
In November, episode 33, Ship It #33 - you can listen to why we did it, and a couple of other things. But we were using Dagger version 0.1. In the meantime, Dagger version 0.2 was shipped… That was end of March/April, and that was CUE-based… And people liked it, but it was CUE, and it was weird for many, and some struggled. So Dagger version 0.3 shipped.
Yaml?
Nope. [laughter] That’s a step back, that’s not an improvement, Jerod… That’s not how this works.
Oh. Okay, good. I thought you were gonna say Yaml.
No, no, no. It’s actually the language that you use. So if you write Go, you can now declare your pipeline in Go, and you can run it in Go. If you use Node.js, TypeScript - you can do that. If you really want CUE, there’s CUE still there. Now, there’s no support currently for Elixir; we could add it… There are just SDKs.
Is that a transpiler? Does it transpile to CUE then?
No. There’s GraphQL behind the scenes. So the interface to the engine, the engine that runs the pipeline, and it orchestrates everything, puts up an API, which is GraphQL, and it does all the magic. So anything that can make GraphQL calls can declare a pipeline and can run a pipeline.
So the next thing, the next big thing - and I don’t know whether this will be finished by the time this Kaizen goes out, which is in this case next week… But soon after, I want to add a pipeline written in Go, because it’s a cloud-native language, that would be the upgrade from 0.1 to 0.3. In this case, Go SDK 0.4. A Dagger Go SDK 0.4 that anyone can run locally. And then our CI - we can get tests locally, we can have a bunch of things, and this opens again… It’s the next bits of Docker, but without Docker, in a nutshell, for pipelines.
[01:00:15.06] Is that your guys’ new marketing slogan? “The best bits of Docker, without Docker.”
No… That’s just me saying it.
Well, submit that to the CMO, see what he thinks.
For those that listen and don’t know yet, I do work at Dagger since January… So it’s been 11 months now, close to 12 months. It’s close to being a year, by the way.
We wouldn’t normally run a 0.1 tool unless we had inside access, right? 0.1 is pretty early…
Very early, yeah. I think we are one of the very few ones that run it in production. Now, that’s the thing that has been running every single commit since November. And apart from the Docker engine - by the way, Docker is needed as a shim to get BuildKit, but BuildKit is the interesting one; it was the interesting component… And that is slowly changing, because the Dagger engine, as it’s being built, it’s less and less BuildKit and more and more its own thing. It was just like a stepping stone, same as Docker is a stepping stone. But BuildKit is the interesting bit right now, and that will change soon.
So the reason why we want that is because we don’t want to be writing Yaml, and we don’t want to be writing anything else that looks weird. Now, we may not be able to write Elixir right now, but it’s an option in the future. If someone wants to contribute that SDK, why not? Lars…That’s the first person that comes to mind.
So is this a move back? I mean, not back, but is this a move in the direction of imperative configs? Because you have a full programming language at your disposal; you’re coding now. You’re not like doing some DSL, or declaring your infrastructure, your pipeline. You’re coding it.
You’re coding something that makes GraphQL calls. So they’re all very functional. So you run this function, and it gives you back a response. And then what do you do next?
So because you’re thinking in terms of functions, in terms of artifacts, it is a real pipeline in the sense that it does operations, it gets results, and then it continues with those operations. The nice thing is you get to use your own language for the looping, for anything that you would do - templating… Any weird things that you may want to do, you get to use your language.
If there’s any library – for example, to integrate with 1Password, you get to use your language. You don’t have to find a CLI, or this weird thing to integrate with the service. If there’s a library for your language, that’s all you need. So that is one of the advantages.
Well, I happen to know a pretty good functional language that’s good at pipelines…
I know, right? [laughs]
Elixir seems pretty good for this.
Pretty much, pretty much…
But Go’s a good, cool start for us, for sure.
I mean, it’s something really lightweight, and something that’s supported… So version 0.3 - that makes me really excited, because we can get rid of some CUE, and we can get rid of some makefiles as well. We can get rid of all the makefiles. And we can use a magefile, which is makefile but in Go… Rake? Remember Rake? Mage is like Rake; think of it like that.
Okay. For Go.
For Go. Exactly.
Alright.
So that’s the next big thing.
It sounds pretty cool…
Now, what else is coming for you, between this Kaizen and the next one…? Any last thoughts before we wrap up?
I didn’t prepare for this being the last one for the year… I’m excited about the improvements that have been happening… I don’t know, that’s about it for me. I’m excited that these discussions are open now too for these episodes. I feel like it’s more of an integration for the listeners to play a part, and see what’s going on behind the scenes.
Do you remember when we used to do this once per year?
I do, yeah.
That’s how we started. Once per year. Look at us; every two-and-a-half months… This is pretty good.
[01:03:58.28] Is this the right clip? Should we be doing it less, or more? Or just right? Something worth thinking about. Maybe ask you, the listener - these Kaizen episodes, do you like them less or more than all the other Ship-Its? Because if it’s a lot more - I don’t know, maybe we have to make adjustments. If it’s the same, then we just keep it as is. If it’s less, maybe we should stop doing these. I guess maybe we should Kaizen our Kaizen, and hear from the listener, and ask you if this is something we should do at the exact same rate, or more, or less. What do you all think? How can we make it better? And then we’ll know for next time.
I really like that.
In terms of things that I wanna work on - there’s a long list… Lots of little things. I guess probably expect a lot more little commits from me. We have a couple of big initiatives that probably won’t land by the next Kaizen. So more small changes. I would like to see some outside contributors, now that we have the new contributing guide.
I’ve never been good at providing low-hanging fruit for people to reach for and grab… Maybe I can put some effort towards that with my list of little things; hang them out there as good first issues, or ways of getting involved for people. Maybe that can be a goal for me over the next couple months.
I think so, too. I mean, we already had two very nice contributions, external contributions for this Kaizen. That was very nice to see. So if we can get two for the next one, that’s amazing. I mean, one we didn’t merge yet, so the RSS feeds - I’m sure we will discuss in the next one. But I’m sure there are other things. Again, I don’t know what they are, especially like the small ones… And I’m mostly focused on the infrastructure side of things, and that requires access, and things like that. But from the app perspective, I’m sure there’s other things. Dark mode, especially in these dark, long nights… I would appreciate dark mode.
Well, we might be working on something in that arena as well…
Oh, interesting…
Let’s invite some folks in. So if you’re listening to this and you’re thinking “Gosh, I’ve gone to the repo, I don’t see these lack of low-hanging fruit that Jerod is talking about. How can I get involved?” The easiest way honestly is just changelog.com/community; you can hang out in the Dev channel, or I would say even the Ship It channel. [unintelligible 01:06:20.27] asking questions around this front. So you can go into Ship It and ask questions about the show, or whatever; or you can go into Dev, which we have pull requests that are there, and things like that happening; commits that are in there. But you can also ask questions. And if you’re thinking like “Hey, I’d love a T-shirt, and I’d love to contribute. Give me a direction”, and if it’s worthy enough, obviously, then we’ll give you that direction and give you a shirt, a code, or whatever…
But that’s probably the easiest way, is be part of the community. Come on in, and… That’s how we wrap up the year, too. We have a state of the ‘log coming up too, where we go through the state of the Changelog over the year, which is sort of the show itself, and also sort of overarching of the entire CPU, the Changelog Podcast universe, so to speak, that’s growing… But it begins with people. It’s all about the people.
So come on in, you’re welcome… Hang your hat, call it home… We’ll make you a tea, coffee, favorite water, give you some slippers… Chill out.
And if you don’t want to sign up for Slack, that’s okay, too. We have these discussions on GitHub. You’re already there, we know that. Discussion 433… Drop us a comment. We’re all subscribed, and getting notifications for that; so that works, too. I think it’s time to call it…
I think so.
That’s it.
Happy New Year, Merry Christmas…
Merry Christmas.
Not in that order… And Kaizen.
Yes, Kaizen!
Kaizen!
Kaizen!
Get your shirt!
Our transcripts are open source on GitHub. Improvements are welcome. 💚