Ship It! – Episode #9
What is good release engineering?
with Jean-Sébastien Pedron, RabbitMQ & FreeBSD contributor
Featuring
This week we talk with Jean-Sébastien Pedron, RabbitMQ and FreeBSD contributor, about the importance of good release engineering for core infrastructure. Both Jean-Sébastien and I have been part of the Core RabbitMQ team for many years now. We have built some of the biggest CI/CD pipelines (check the show notes for one example), wrote and shipped some great code together, while breaking and fixing many things in the process.
We have been wrestling with today’s topic since 2016. Jean-Sébastien has some great FreeBSD stories to share, as well as an interesting perspective on shipping graphic card drivers. Oh, and by the way, it’s probably our fault why your remote car key stopped working that afternoon. It will all make sense after you listen to this episode.
Featuring
Sponsors
Fly – Deploy your apps and databases close to your users. In minutes you can run your Ruby, Go, Node, Deno, Python, or Elixir app (and databases!) all over the world. No ops required. Learn more at fly.io/changelog and check out the speedrun in their docs.
Teleport – Teleport Access Plane lets you access any computing resource anywhere. Engineers and security teams can unify access to SSH servers, Kubernetes clusters, web applications, and databases across all environments. Try Teleport today in the cloud, self-hosted, or open source at goteleport.com
Linode – Get $100 in free credit to get started on Linode – Linode is our cloud of choice and the home of Changelog.com. Head to linode.com/changelog OR text CHANGELOG to 474747 to get instant access to that $100 in free credit.
LaunchDarkly – Ship fast. Rest easy. Deploy code at any time, even if a feature isn’t ready to be released to your users. Wrap code in feature flags to get the safety to test new features and infrastructure in prod without impacting the wrong end users.
Notes & Links
- FreeBSD release engineering
- Netflix and FreeBSD: Using open source to deliver streaming video
- List of products based on FreeBSD
- Darktable
- Mesa
- Erlang hot code reloading:
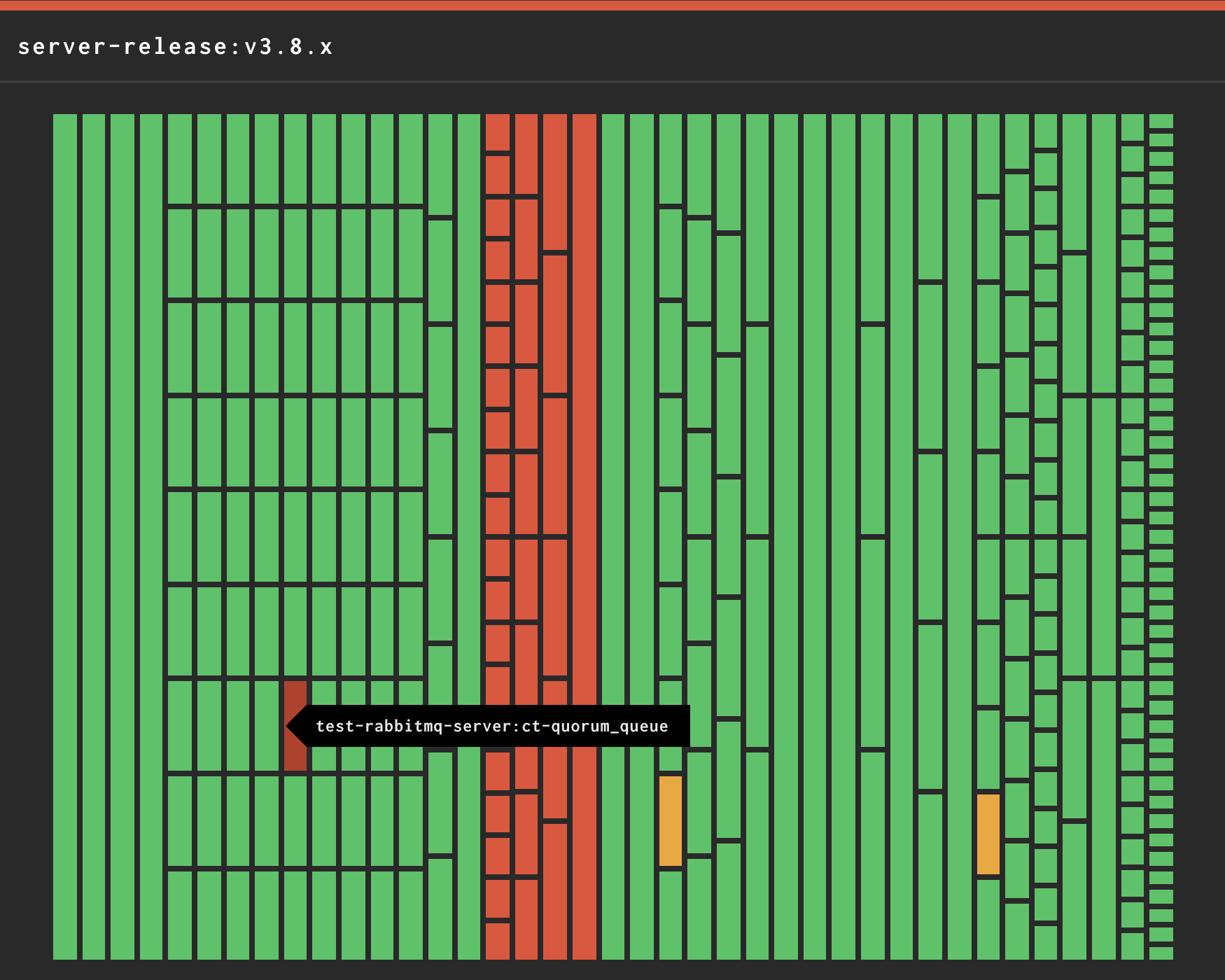
Transcript
Play the audio to listen along while you enjoy the transcript. 🎧
So end of 2016 I have joined this new team of developers, and they were the RabbitMQ core developers. The context of that meeting was the RabbitMQ Summit, which is something that used to happen every six months, twice a year. But that stopped, obviously, since the pandemic and all the recent changes.
The one person over the years that I really enjoyed working with is Jean-Sébastien. And if you’re wondering who you can thank for all the makefile madness that I’m leaving in my trail, it’s Jean-Sébastien. He’s the one who introduced me to make, and the rest is history, as they say. Not only that, but he also introduced me to the RabbitMQ codebase; we were pairing buddies for a long time, and I found out about the build system, about the pipeline, about many things.
[04:16] So for the listeners - I mean, you’ve made so far into this episode, and you’re still wondering what do I do; for those that don’t know yet, this is where I tell you that my dayjob is to work on RabbitMQ. I’m a RabbitMQ core developer, same as Jean-Sébastien. So welcome, Jean-Sébastien, joining me in this new world…
Thank you very much.
You’re very welcome. I was looking forward to this for a long time, actually… And one of the topics that are very relevant to this show are release engineering. And this is something that both you and me have been thinking about for years in the context of RabbitMQ, and have been working on it in different capacities… And my first question is “Why do you care about release engineering?”
I think it’s an important part of a project, and in particular an open source project. The first reason is that you want to ship your code to end users to help them solve their own problems; you want those users to be happy with what you ship, and I think that to make that happen you need to communicate well with those users, explain what you ship to them, like “That new release contains these new features. That bug you hit, now it’s fixed. You might be interested in that security vulnerability” and so on.
You also want those users to give you feedback on what you shipped, because that’s how you can also improve your codebase and make the next version better than the current one. So yeah, that’s what I would expect from a good release engineering, and I’d say that it’s important for open source products, because you do not have any paying customers most of the time. So nobody is pressured to use what you produce and ship. So it’s in the interest of the end users and you to have that great communication when you release something.
I think that relationship is really important, right? …the relationship of an open source developer with a user of open source… And that has gone through many ups and downs over the years. I don’t know exactly where it stands now, but it is becoming increasingly important for these projects and products to somehow make money.
Now, while release engineering for an open source product may not seem as important at first, because it’s free, so why care, actually the opposite is true. The developers care a lot about these things. And once you have a certain number of users, which RabbitMQ has, these things become important… Because bugs can affect many users, and one of the ways that I think about RabbitMQ is a core infrastructure component. Typically, RabbitMQ is used in all sorts of systems - cars (even), factories, things like payment systems… You don’t even know where it’s used, only when it goes down, or only when there’s a problem. And this is not great. And from that perspective, it becomes increasingly important to communicate changes well, to be careful with the changes that get introduced, because many things can end up being broken. And usually, what tends to happen if developers are not careful about this aspect is that end users - they stop upgrading. I mean, if you experience similar problems a couple of times, you’re more reluctant to upgrade.
Yeah, you will probably try to find alternatives to that project. This one was free – free, I mean it didn’t cost you any money, so you do not lose anything by switching.
[08:13] Again, I view RabbitMQ as core infrastructure, but what does core infrastructure mean to you?
I think I have the same definition as you. A core infrastructure is a component you rely on to provide your service, for instance, if you’re a company… Or even as someone at home, I rely on some core infrastructure just to run my own computers, even if it’s not for work.
For instance, as a company, in the context of RabbitMQ for instance, I expect that it’s crystal clear what I get from RabbitMQ, so that I’m confident when I want to deploy it, upgrade it, so that I can build my own business on top of that component, and this won’t fall apart because of that core component, core infrastructure. And that is the same for any operating systems. Nobody likes when the operating system crashes… So yeah, that’s why we call them core infrastructure, in fact.
Yeah. So I know that you have experience with RabbitMQ, but I don’t know as much about your experience with FreeBSD, because you’re not just a RabbitMQ contributor, but also a FreeBSD contributor.
So you have seen both sides of a messaging system such as RabbitMQ and an operating system such as FreeBSD. So how do the two compare?
An operating system is a very generic tool. You don’t expect it to be the best in a specific area, but you expect it to behave well, and be at least good in all areas. RabbitMQ is a bit different in that [unintelligible 00:10:08.03] because we want to provide a very specific service in RabbitMQ. Also, FreeBSD is an old project, with old manners, and it’s a big community, so it takes time for things and workflows to evolve. But in the end, we also want to ship an operating system which will work for end users who use it at home and companies who build their businesses on top of it. So yeah, that’s why the release engineering in FreeBSD is also very important. The goal is the same, how it is done is different, and how you test things, obviously. You cannot compare both projects.
So can you give me an example from your experience of release engineering gone wrong in both projects, if there is such a thing? I’m sure there is.
Starting with RabbitMQ, I remember one release – I don’t remember the version number, but at the same time we released a new version of RabbitMQ with both a security bug fix and a breaking change. That was perfect, I’m sure, for admins who wanted to deploy that security bug fix as soon as possible. I think that’s probably the worst-case scenario.
In FreeBSD I remember the FreeBSD 5.0 release cycle, because between FreeBSD 4 and 5, one of the big changes was to replace global lock used all over the place in the kernel by fine-grained lockings. And this went pretty bad because it took years to stabilize that work.
[12:09] In parallel to that, new versions of FreeBSD 4 were cut and published, but it was really difficult for the project to ship something at that time, because the cut base was very unstable, and nobody knew when we could cut even beta, let alone the final version. Yeah, it was a big problem because of that. It put pressure on people working on that code. Other people were tired because we didn’t ship anything, and I’m sure end users were saddened by that situation as well, because some of them were looking forward to using the new version… Other users would see that disaster coming, and in the end nobody wanted to use FreeBSD 5.0, because it was too uncertain what you could do with that. So I think that’s a good example of bad release engineering.
I think you touched up on something really interesting, which is the longer you wait to ship something, the worse the release gets, or the more problematic the release can become.
Yeah.
I don’t know whether it becomes is a definite but the longer you wait, the higher the chances the release will not be as good.
Yeah. And I think that the most important part is that people are losing confidence, both developers working on that, and users expecting the release.
Yeah, I think we keep forgetting, at the end of the day it is people like you and me that are responsible for some pretty important systems that they have to, first of all, consume these updates somehow, understand what changes they are rolling out, and when something goes wrong - well, guess what? They are the ones responsible to fixing those problems. I mean, they can blame the developers developing or releasing that software, but ultimately, they need to take certain precautions that things are rolled out in a good way.
So the harder it is for these developers to roll out these changes or to start using maybe new features, whatever it may be, the less likely they are to consume future changes. So it’s almost like they enter a vicious cycle, but it’s a negative one in that if it doesn’t work as smooth and as consistent and as pain-free as a user would like – for example your phone; if every time you upgraded your operating system on your phone things would break, would you do it?
No. If things would change in unexpected ways, would you do it? No. If you had to wait a really long time for an update, like let’s say two years, and then you applied it and everything broke, would you do it again? No. So there is a very strong relationship between the happiness of end users and the release engineering of the products and the systems that they use.
Yeah, I agree.
So if you had to pick one - I know it’s an unfair comparison, but let’s just go with it for the fun of it - what would you say is a more core infrastructure, RabbitMQ or FreeBSD?
It’s a tough one…
You can answer it any way you want, by the way… It’s meant to be fun, it’s not meant to be tough. [laughter]
I think it depends on… If we stay in the company we’re not end users and not people at home I mean, it depends on what kind of service you provide on top of that. For instance, if we are taking a company using RabbitMQ for cars, like you mentioned earlier, in that case RabbitMQ would be the most important one, because you want all those devices and cars and computers to communicate properly.
[16:16] So I think that’s the most important component. For a company like Sony, for instance, who is using FreeBSD in their Playstation products, if the devices they ship to gamers crash all the time because their operating system is unstable, it will be a very sad story for everyone. So in that kind of context I think the operating system is important.
I know that Netflix are other big users of FreeBSD. Imagine if you can’t stream your Netflix because there was a bug in FreeBSD, probably shipped worldwide, across all their [unintelligible 00:16:54.02]
WhatsApp is also using FreeBSD, but they’re also exchanging messages… So in that company if they were to use RabbitMQ - yeah, it would be more difficult to define which component is the most important. I would say RabbitMQ.
I think they would get the best and worst of both components, so it depends on a combination of that how well that would work out… But I see what you mean. And for the listeners, this actually happened; both myself and JSP were in Paris - JSP is from Paris, France… JSP - that’s how I refer to Jean-Sébastien. Do you know what JSP comes from? Actually, I don’t think I’ve ever told you this… So JSP is obviously the abbreviation of Jean-Sébastien Pedron, your full name…
But GSP is actually Georges St-Pierre, and he’s an MMA fighter.
[laughs]
I used to do his workouts many years before I even met you. So whenever I say JSP, I’m thinking “Ah, Georges St-Pierre”, and like “I should go for a workout.” So that’s something which happens – I know you never knew that, but anyways, that was a tangent. So coming back… We were Paris, and we had to – well, not figure out, but help this RabbitMQ customer to make sure that RabbitMQ will be reliable in all sorts of scenarios, because would end up not getting unlocked from their remote car key, because RabbitMQ is involved in between the car and the key; RabbitMQ is exchanging messages. You wouldn’t think about that, and neither should you; why would you? People don’t really care about these things. And when everything works, it doesn’t matter. When it doesn’t work, that’s when the problems start appearing. So that was a very interesting conversation and meeting, I have to say. I enjoyed it greatly.
Yeah. Especially that RabbitMQ is often used to also mitigate problems on both the application emitting the message and the application consuming it.
That’s right.
So if you have a problem in the middle…
Yeah, I’m pretty sure that today, for example, you have used a system that behind the scenes uses RabbitMQ. And that’s why we think of it as core infrastructure, because we know that it’s everywhere. And it works well in most cases, but as it happens, we get to find out about all the cases when it doesn’t work. Then we have to fix it, and then ship those fixes. So that’s a very interesting perspective.
Break: [19:27]
So we’ve been talking generally about the RabbitMQ release engineering, the FreeBSD one, how do they compare as projects, the whole core infrastructure notion… What I’m wondering now is how does the FreeBSD release engineering process look like?
So after that FreeBSD 5.0 disaster the release engineering team started to work on something so that FreeBSD never faces that situation again… And that process evolved a couple times since. Today, the FreeBSD release engineering is based on a fixed interval between major releases and also minor releases. We don’t expect to start on a very specific day at 8 AM, for instance. The OpenBSD one is sharp as a Swiss clock, but not in FreeBSD.
When we want to start to prepare the next release, we have release engineers or someone who is hired by the FreeBSD Foundation and is paid for that; he will take care of announcing to the FreeBSD contributors - not only the contributors, but the entire community. He will publish a calendar where he will state that the code [unintelligible 00:21:52.14] We expect to get the first beta at this date, we expect perhaps two betas, then two release candidates, specifying, again, the dates. He will indicate as well the date for the final release of FreeBSD. So that calendar is updated on a regular basis while we make progress in that release cycle. For instance, if we discover that there are bugs or there is a security issue, or whatever the reason, we might want to delay beta for a couple of days, or we might want to add third or fourth beta, or same for the release candidates, and so on.
So that calendar is very flexible, but it’s quite useful, because it tells to the FreeBSD contributors when to expect things, and it’s very easy for contributors to organize and prioritize their tasks. For instance, if someone is working on new features, then he knows that he has to finish by these dates, or it will be delayed to the next release. So that’s very helpful for contributors, and like I said, this is not that strict. So any contributors can communicate also to the release engineer what he is working on, so that the release engineers know that “Okay, this specific batch is incoming. It might introduce some instabilities, but we want that in the release”, so he can anticipate that and perhaps tell anyone that “Okay, we expect this to come in the next couple of weeks. This will go in that beta and we will add another one after that”, for instance.
[23:52] So that calendar tool is really useful, because it allows everyone in the community and the developers to communicate and understand what’s going on. As I said, for users who will use that new version of FreeBSD, they can plan for testing, for instance. You mentioned Netflix - they’d appreciate that, because they can test in advance the new features, so they will fetch the development branch, for instance, compile FreeBSD and then try it in their environment and see how it goes, and they will give some feedback.
So the fact that we use a detailed calendar - yeah, it really helps the communication and it makes the whole process more reliable and the outcome more reliable as well. I think that’s the main part which was introduced following FreeBSD 5. And we have some evolutions from time, but they are mostly around adjusting the timeframe between releases, so that it’s easy for end users to understand that “Okay, this will come in next September. Perhaps the release will take a bit more time, but in next September - okay, we know that we’ll have a new release.” This would have been very helpful in the time of FreeBSD 5, because we could have delayed some of the work done around looking to a future version, for instance, instead of trying to finish that huge task before shipping anything.
Yeah. This is something – first of all, this sounds really interesting, and what I’m wondering is could I see this calendar somewhere? Can I see how this process works? Is it publicly available?
Yeah, that calendar is published on the FreeBSD.org website, announced on the mailing lists… That’s the main communication channels.
And where does the FreeBSD development happen? I know that the RabbitMQ one happens on GitHub, but where does the FreeBSD one happen?
Initially in CVS. I don’t remember the years exactly, but at some point we switched to Subversion, and both servers were hosted internally in the FreeBSD infrastructure, and in the Yahoo cluster in Sunnyvale. In the past year we switched to Git, but we are still hosting that internally, and the reason is that we want to dogfood FreeBSD [unintelligible 00:26:25.10] There are read-only mirrors available on GitHub. And there are still some discussions around “Do we want to introduce GitLab, or some other tools?” The idea is that because that’s a private – not a private, but internal Git repository, currently we don’t have all the nice tools provided by GitHub, for instance. It’s still a barrier to entry for contributors who are used to use GitHub for any kind of open source project… And yeah, that’s still a discussion, because you have to balance the fact that you want to dogfood FreeBSD, you don’t want to depend on a company’s service, which is perhaps free for now, but we cannot tell what the future will be. So that’s on one side. And on the other side, the fact that GitHub is so popular, it’s a great source for new contributors and contributions in general.
Okay. So I know that you can obviously communicate everything via the website. I don’t know whether you have any commenting enabled; most websites don’t. It tends to be a one-way channel… But how does the community talk to the developers? Is there a mailing list? How does that work?
[27:46] There are many mailing lists. In fact, either by topic, for instance, there are mailing lists around the graphics stack, around the Wi-Fi drivers, around network storage, a particular CPU architecture, and so on. And there are some mailing lists about topics such as the current development branch or the stable release branches. That’s the primary communication channel in FreeBSD.
Let me guess - these mailing lists are software that runs on the same FreeBSD servers as the Git repo?
Yeah.
Okay.
Yeah, they are hosted…
Okay. Those must be some beefy machines, to run everything…
Yeah, the infrastructure - initially, it was hosted in the Yahoo infrastructure, because some FreeBSD developers were employed by Yahoo; they offered that service. But now that Yahoo doesn’t use FreeBSD anymore and the company is splitting the various services, the infrastructure moved to some other companies. I don’t remember which one, but they are offering the hosting and there are some servers around New York, still in San Francisco, and some of them are also in Europe and Asia.
So I understand how the community can talk to the FreeBSD developers… How can they participate in FreeBSD development?
One way to find tasks is to look at the Bugzilla bug tracker. That’s also one tool which is discussed, because people of my age are very happy with Bugzilla, but I’m sure people almost 20 years younger might find it quite archaic. [laughs] So yeah, that part is still being discussed and will evolve… But yeah, Bugzilla is one place to find bug reports, and thus things to work on. The mailing is another one where you can see what people are talking about or complaining about in particular.
So if you don’t know what to do, that’s one way to find work to do. Another one is just solve the problem that you hit every day if you are using FreeBSD for work, or at home. That’s how I started, in fact.
And how do you submit the patches?
You can send pull requests on GitHub. They should be taken care of by someone at some point. You can submit patches on mailing lists, you can submit patches on Bugzilla after opening an issue… There is no one specific channel to submit your work.
Okay. So this is a little bit of a tangent that we had for the last few minutes, because the question was “How does the FreeBSD release engineering look like?”, so we covered that… So coming back to that topic, you had a very good description of how things work. I don’t think you mentioned any timelines, in the sense that when a new release starts, how long before that release gets shipped? How long before the GA? What does it look like to go to a beta? Is there a time period when beta starts shipping? How long does it take typically before an RC (or the first RC) ships? And eventually the GA.
Yeah. It depends if it’s a minor release or a major one. FreeBSD does not follow semantic versioning.
That’s interesting, because the version would make you think that it does, right? It’s currently version 12 or 13, I can’t remember…
Yeah, both exist currently. [unintelligible 00:31:28.23]
Right, so both version 12 and 13. And you also have 12.1, 12.2… But those are not semantic versions.
No, not really. It’s close, but - how can I say…? Yeah, this is close to semantic versioning, but this is not documented as that. I mean, in FreeBSD we pay a lot of attention to breaking changes, as we have what we call POLA, Principle of Least Astonishment. It means that old changes which go into FreeBSD should be the less disruptive, in fact. And we should not surprise users, even between major releases.
[32:13] So when you want to deprecate something or remove something, you have to announce that a long time before you want to do that. If possible, it’s good if you can mitigate what you are about to change in a breaking way, so that the transition from one version to another major version - it must be as smooth as possible. We pay a lot of attention to compatibility between major releases. Of course, you cannot guarantee that all of the time, but that’s an important part of the FreeBSD release engineering.
Back to the timeline, I would say that a major release – between the beginning of the release cycle and the end we are talking 2-3 months, perhaps more if there are bugs that crept in and are difficult to track down. For minor releases, they are shorter, but we are still in the range of weeks, and perhaps months sometimes.
Okay. So now that we think about the FreeBSD release engineering as a whole, what can RabbitMQ learn from the FreeBSD release engineering?
I like the fact that it’s based on a fixed interval between major and minor releases, and the fact that the release cycle follows a calendar which is announced in advance to everyone involved, contributors and users. I think this is a great tool to improve the communication and the organization of the work, in fact. I would love to introduce that into RabbitMQ, having that calendar.
Yeah, I think it makes a lot of sense. We have been thinking about this for a while, and we have been looking at – well, FreeBSD is one example, but also other projects… And it does sound like a good idea. Obviously, between the idea and the implementation there’s a whole ocean of things to go through, but the direction sounds reasonable to me. I’m wondering if there are any other open source projects that you like how they do release engineering.
For instance, there is the Darktable open source photo editing project. They are also publishing a calendar in advance, and because they provide translations of the software, they also have to take that into account into their release cycle, to give time to translators to provide their translations. That’s one thing I like in what they do.
Another one is the Mesa library, that you can use on Unix. It’s a library providing a 3D implementation of OpenGL, for instance, and all the new standards in that area… And now it grew a lot [unintelligible 00:35:21.18] GPU drivers, for instance. So this is a large piece of code now, and what I like in their release engineering – I don’t remember if they followed a fixed timeline or if they provide calendars, but I like how they handle the batches. A developer is working on a batch, and he doesn’t know if that batch will go into the next minor release or that needs to wait for the next major release.
[35:59] So they have someone, like FreeBSD, who is responsible to manage the release engineering. This time he’s not higher or paid for that work, so it’s on his free/spare time. They are trying various ways to – that was a few years ago, so that probably settled since, but they wanted to try several things on what would be the best way to make that communication possible… Like - a developer wants that batch into the next stable minor release, but it might not fit the timeline, and so on. They tried tags in the Git commits; I think they tried specific mailing lists, where people would post their patch, and so on. I don’t know what they chose in the end, but I like how they explored various methods.
Do you know what I remember about this specific topic? During one of our RabbitMQ team summits – by the way, RabbitMQ is a distributed team. As I mentioned, twice per year we used to meet in a single place. It used to be London. So we had like an on-site, which was an off-site for some – but anyways, it was an on-site… And during these team summits I noticed that your laptop had a weird thing on its screen. I said “JSP, I think your screen needs replacing. This laptop needs replacing”, and you were saying “No, it’s okay. I’m working on some graphics drivers, and I don’t quite have this thing right.” So pixels were looking a bit weird, and I noticed the pixels started changing. I was like “Oh, JSP, why did you have to bring development graphics drivers to the team summit? Now we can’t code properly.” Then obviously I would take my laptop out and like “Okay, let’s get a properly-tested and properly-running graphics card and graphics drivers.” [laughter] That was a fun one.
Then you told me about your interest in developing graphics drivers, which I thought was fascinating. How do you even do that? I was like, “Whoa… Really?” Little did I know that – you know, also FreeBSD, I have to thank you for my FreeNAS server, how stable that is, and a couple of other things… So yeah, that is pretty important. It’s the backups, right? All the pictures, before iCloud and before other services I used to back everything up on FreeNAS, and it never failed me, so… There’s something to say there. ZFS has something to do with it. Drives failed, but FreeBSD never failed me, so I was very happy.
Nice. That’s good to know.
Yeah, that is good feedback for you.
Yes. [laughs]
It wasn’t 5.0, it was 9 and 10 – actually, no, it was 11. I remember that one, 11; when I started really depending on it, it was great. That was a great few years of service.
Great. And yeah, you mentioned the graphics drivers - that’s a nice topic around release engineering, because it’s one area where it’s difficult to find the right balance, in fact, because we want to ship obviously a stable operating system in the end, and the Mesa library also wants to be stable for all end users, so that it can render your desktop videos and video games.
But that’s an area where the hardware and the new models are put in the market at a high pace; the technology evolves a lot, and the GPU is a very complex beast. So on one side, you want to support the latest GPUs, but because if a user today buys a laptop, he will go for the latest shiny one. He won’t choose the one released three years ago. So you want to ship all those new drivers and bug fixes as soon as possible, but it’s very difficult because the drivers themselves are very complex, so it’s very difficult to test what you ship, because no one has all the various graphic cards and GPUs and configuration in general, so it’s impossible to thoroughly test.
[40:15] Yeah, it’s very difficult to find the right balance between shipping often and shipping something stable. I don’t think we’ve found the right balance in FreeBSD either. Now drivers are provided as packages; they are not in the core anymore, the source code of FreeBSD. That improved a lot, but it still has some issues from time to time to decide on when to ship a new version of that package.
I think the more you dig into this and the more you work with this, you realize that it’s not as straightforward, and everybody tries to make the best decisions they can given what they know. No one is trying to purposefully ship broken software. Sometimes it’s really hard, and it looks like people don’t care, or they don’t think, but they do, and it’s really hard. That’s something worth emphasizing again and again.
Yeah.
I think in certain contexts it’s much easier to maybe use feature flags, or something similar, in that you’re shipping the feature, but you’re not enabling the feature. And this is a very important distinction to make. In some cases you can ship it, but not enable it, and that’s okay. And then test it, or trickle it down through users, beta testers, and whatnot. When you have all your feedback, then if you can ship an update, then you do that, and everything is good, and everybody has the best, latest version, or the closest it can get, because it can always be improved, and there will always be bugs. After all, we are all human, and we will make mistakes. And that’s okay, that’s not the problem. Don’t try not to make mistakes; try to limit the impact of those mistakes, and fix them before anyone notices, because then it looks like you’ve never made the mistake, while everybody knows the truth, right?
[laughs]
So yeah, countless times this has happened, and it will happen, so better be honest about it.
That’s why it’s important to communicate well to contributors and users. That’s the responsibility of that release engineering; you know that it might not be perfect in the end, what you ship, but at least you tried to make sure that people are aware of what is fine and what might not be fine.
Break: [42:35]
JSP, what did you work on before RabbitMQ?
I worked as an Erlang developer for a small French company. The company was providing a website aggregating ads, so that people could look for jobs, apartments, various objects they would like to buy.
[43:58] Craigslist, or Gumtree? For the listeners…
Yeah, something like that. And we wanted to provide some kind of social media features on top of that, so that people could easily interact between them. In that company I was an Erlang developer; we were two Erlang developers working on the server side of that service. We chose to take Yaws, which is an Erlang-based web server. That was because it was easy for us to extend write directly in the Erlang VM. In fact, add our own modules and applications in addition to Yaws.
The website itself was developed in PHP and JavaScript, but we were not working on it; other developers were responsible for it. But those PHP files and static files were served by an Erlang VM. And what I liked about what we did is that we put some effort to make sure that the website was always running, even when we were working on it and upgrading it.
So if we had to upgrade the operating system, and especially the kernel which was Debian, obviously we would have to reboot the computer. But otherwise we wanted to leave the service running. And what was great is that we could in the end benefit from the hot code reloading feature of Erlang, this brilliant, awesome feature.
We were very happy, because we could build Debian packages for our service. So we packaged the Yaws server, all our Erlang codebase and the website itself, so the PHP scripts, static resources, so JavaScript and CSS on images, and so on… So we packaged everything as Debian packages, and when we would apt-get update, apt-get dist-upgrade the machine, the servers, then the new copy of the Erlang code was deployed, and we were using the Erlang features to reload that code live, while the HTTP server was still running and serving requests. We were very happy with that. It’s a really great feature from Erlang.
To me, that sounds like you’re using Erlang the way it was meant to be used, and what you’re telling me is that it works really well when you use it the way it was built.
Okay. Well, that is a great complement, and working as expected in this case, it’s great; and sometimes even rare. Obviously, not all software works as expected, that’s why I mention this. And when it does, like “Oh, yes! Everything works as it should”, and it’s great, and it feels great. So you were on the beaten track, as designed, and everything was good.
I know the answer to this, but I know that many listeners will be wondering… First of all, is RabbitMQ using hot code reloading?
No, it’s not.
And the follow-up - why not?
It’s quite difficult to manage. The first part is that all developers and all contributions to the RabbitMQ code might lead to changes which don’t look as breaking changes when you think of a single instance of your Erlang VM, for instance; you stop the service, you load the code from the disk, it runs as expected, you stop the VM, and all is fine. But the problem starts to show when, for instance, the state of a process changes between one copy of the module and the next one. So you need to handle that migration from state v1 to state v2. There are tools to do that in Erlang, but this is not magic. You have to use them, and implement that migration from v1 to v2.
[48:10] And it gets even more complicated when you’re having a cluster of Erlang VMs. So you have to take care of the fact that, for instance, an Erlang process, while the code is reloaded, will modify its own state, and will start to use inter-process messages with a newer structure. When I say “message”, in this context it’s messages exchanged between Erlang processes, not messages that RabbitMQ would handle from other applications.
You have to handle all those changes live, so that new process which was reloaded might receive new messages using the new format from process on that same node, but it might receive all the messages from a node which was not yet upgraded, and so on. So that part is quite difficult to handle, and if you have mistakes, then it will crash, obviously. So that feature is great, but it puts a lot of load and responsibilities on developers and contributors’ shoulders, because you have to handle all the cases.
And the second part which is difficult is how to package that… Because Erlang was designed so that in the end you do not ship just the RabbitMQ Erlang applications, for instance; it was designed so that you ship the Erlang VM itself, the Erlang code you want to run on it, and the configuration. In the end, it’s an appliance that you put on a server, but it’s a whole thing, and a standalone thing. It has the VM, the code and the configuration. It’s not meant to support changes to that configuration, even that. And trying to package that - in my previous job - as Debian packages was a great challenge, because the Erlang VM is installed by other Debian packages. We also want to be able to change the configuration, configuration which was installed not by the package, but by tools like – we were using Puppet, but a configuration management tool. So it’s quite difficult to use that Erlang feature in today’s packaging and configuration management infrastructure.
I remembered that – this just reminds me of a discussion that we had a few years back about this very subject… And it’s interesting how it comes back again. I remember the plugin system in RabbitMQ being one of the challenges when it comes to packaging RabbitMQ in an Erlang release, being able to define what is running, when, and how it’s running. Again, for the listeners, RabbitMQ has this concept of plugins; a lot of them ship with RabbitMQ, others can be added, just dropped in a directory and off you go… And those plugins - they are applications. So RabbitMQ really is - this is the way I think about it - a microservices architecture in a single Erlang VM, in a single system process. Because you have all these applications exchanging messages, and by the way, they could be cross-nodes. So that’s where the Erlang distribution comes in, where those messages have to traverse a network, and then you have a cluster of three nodes or four nodes. And any message, by the way - this is like an AMPQ message, whether 0-9-1 or 1.0 or any MPQ protocol - it can arrive at any node and it will end up in the right place, because the cluster is aware of where the members are, where the processes are, and how to send those messages internally. And that’s what makes it challenging.
[52:03] So the one thing that helped (I think) in recent years is containers. Containerizing RabbitMQ, having that tarball, which really used to be the Debian package, now it’s called something else… FreeBSD jail - similar concept. So the container allows us to package Erlang, even the operating system… Because that’s where you have OpenSSL and all the dependencies, and we have a single tarball, which is a runnable artifact. You spin it up and it has everything that you need, in the right order, preconfigured, a bunch of things. So that really helps.
And then on top of that, obviously, if you use something like Kubernetes, you want a cluster operator, or an operator that manages your deployments, which is especially important if you have a clustered stateful system such as RabbitMQ, or a distributed stateful system. In those cases it really helps.
And this just made me realize that one discussion which I would really like to have is with [unintelligible 00:52:58.19] about the cluster operator, and how RabbitMQ runs in the context of Kubernetes… Because I think it does a lot of thing really well, being a stateful distributed system on Kubernetes; that’s challenging.
And I think the new tools made this problem easier from some perspectives, but they also made it harder from others… And adapting to the new world - it’s very challenging. I think a lot of this is lost in the details, and it’s important because many can learn from this, many stateful systems can learn from this. And I know a few stateful systems, databases which don’t work that well in the context of containers of Kubernetes, of things that come and go so often, networks that break all the time, or more frequently than they do in the traditional data center, in the traditional bare metal hosts. So that’s something which is challenging.
Okay, so I would say that my understanding is that you miss this hot code reloading from the olden days, that RabbitMQ doesn’t have, and there are some practical limitations why it will be very difficult to implement. Not impossible, but very challenging. Is there anything else that you miss?
No, I think that’s something I would love to see in RabbitMQ, and even though it’s difficult, I don’t think it’s impossible. For instance, if we were to ship only bug fixes into our batch versions, then it would be pretty easy to have that hot code reloading. The way you describe it in Erlang means that we could say that going from a batch release to the next one, it supports hot code reloading… But we can also say that going from a version to the next minor it doesn’t; the VM has to be restarted. So even that is supported by Erlang itself. The hot code reloading knows when it cannot be reloaded live.
So I think if we were to have only bug fixes in batch releases, we could have hot code reloading implemented, and it would not add a lot of load to our team, I think. That is achievable, and a great benefit from that is that upgrading RabbitMQ to the next patch release means you don’t have to restart RabbitMQ, which means you don’t have to spend a lot of time starting RabbitMQ if you have thousands or tens of thousands or hundreds of thousands of queues and exchanges and bindings, and so on.
Well, I’ve really enjoyed this discussion, JSP.
Yeah, me too.
Thank you for joining me. It was great fun. I’m looking forward to the next one… And I’m wondering if there’s any closing thoughts that you have?
Yeah, so I would like to know in fact what people are doing in their job or their personal projects to ship what they produce. Do they have experience with various release engineering practices, and what works and didn’t work for them. I would love to hear from their writing software, but I would also love to hear from people who are consuming those open source projects, or even commercial projects, what they like and what they don’t like when they want to learn more about the new versions of the tool they use.
So if you’re a FreeBSD user or a RabbitMQ user, let JSP know what you like about the release engineering, what don’t you like, and what would you like to be better, and what does even better mean for you. He would enjoy, and I would enjoy as well, knowing about that.
Yeah, we will both benefit from the answer.
Well, this was fun, JSP. Thank you very much. See you next time.
Yeah. Thank you for the invitation.
Our transcripts are open source on GitHub. Improvements are welcome. 💚