A 280 billion parameter language model named Gopher ↦
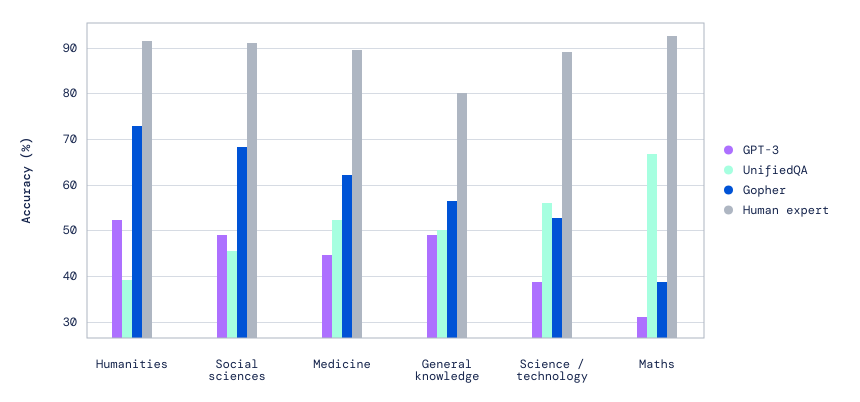
In the quest to explore language models and develop new ones, we trained a series of transformer language models of different sizes, ranging from 44 million parameters to 280 billion parameters.
Our research investigated the strengths and weaknesses of those different-sized models, highlighting areas where increasing the scale of a model continues to boost performance – for example, in areas like reading comprehension, fact-checking, and the identification of toxic language. We also surface results where model scale does not significantly improve results — for instance, in logical reasoning and common-sense tasks.
Sometimes size matters, sometimes it doesn’t as much. Fascinating analysis.
Discussion
Sign in or Join to comment or subscribe