Eight months ago, in 🎧 episode 49, Alex Sims (Solutions Architect & Senior Software Engineer at James & James) shared with us his ambition to help migrate a monolithic PHP app running on AWS EC2 to a more modern architecture. The idea was some serverless, some EKS, and many incremental improvements.
So how did all of this work out in practice? How did the improved system cope with the Black Friday peak, as well as all the following Christmas orders? Thank you Alex for sharing with us your Ship It! inspired Kaizen story. It’s a wonderful Christmas present! 🎄🎁
Featuring
Sponsors
Sourcegraph – Transform your code into a queryable database to create customizable visual dashboards in seconds. Sourcegraph recently launched Code Insights — now you can track what really matters to you and your team in your codebase. See how other teams are using this awesome feature at about.sourcegraph.com/code-insights
Raygun – Never miss another mission-critical issue again — Raygun Alerting is now available for Crash Reporting and Real User Monitoring, to make sure you are quickly notified of the errors, crashes, and front-end performance issues that matter most to you and your business. Set thresholds for your alert based on an increase in error count, a spike in load time, or new issues introduced in the latest deployment. Start your free 14-day trial at Raygun.com
Notes & Links
Chapters
| Chapter Number | Chapter Start Time | Chapter Title | Chapter Duration |
| 1 | 00:00 | Welcome | 01:04 |
| 2 | 01:04 | Sponsor: Sourcegraph | 01:43 |
| 3 | 02:46 | Intro | 05:56 |
| 4 | 08:43 | Moving towards Kubernetes | 04:14 |
| 5 | 12:57 | Feature flagging, did it work? | 04:00 |
| 6 | 16:57 | Black Friday and Christmas | 06:59 |
| 7 | 23:56 | From problem to solution | 01:37 |
| 8 | 25:40 | Sponsor: Raygun | 02:07 |
| 9 | 27:53 | Datadog | 01:44 |
| 10 | 29:37 | MySQL and MariaDB | 05:28 |
| 11 | 35:06 | SLIs and SLOs | 03:17 |
| 12 | 38:22 | Day to day before Christmas | 02:42 |
| 13 | 41:07 | The improvement list | 03:06 |
| 14 | 44:14 | Deployment pipeline for legacy | 03:10 |
| 15 | 47:24 | It's going great | 05:02 |
| 16 | 52:26 | Big plans for 2023 | 02:54 |
| 17 | 55:20 | Where software meets the real world | 01:31 |
| 18 | 56:51 | More Kubernetes or less? | 00:50 |
| 19 | 57:41 | RUM (Datadog) | 02:55 |
| 20 | 1:00:36 | Key takeaway | 01:39 |
| 21 | 1:02:15 | Wrap up | 02:00 |
| 22 | 1:04:17 | Outro | 00:52 |
Transcript
Play the audio to listen along while you enjoy the transcript. 🎧
Alex, welcome back to Ship It.
Yeah, it’s great to be back. It doesn’t feel that long since our last chat.
No, it wasn’t. It was episode #49, April(ish)… Six months, actually; six, seven months.
So much has changed…
Yes. The title is “Improving an e-commerce fulfillment platform.” A lot of big words there… The important one is the improving part, right?
Indeed, yeah. So much has changed, and it’s really interesting… I think the last time we spoke, we fulfilled about 15 million orders, and we’re closely approaching 20 million. So almost another 5 million orders in six months. It’s just crazy the pace we’re moving at this year.
That’s nice. It’s so rare to have someone be able to count things so precisely as you are… And it’s a meaningful thing, right? It’s literally shipping physical things to people around the world, right? Because you’re not just in the UK. Now, the main company is based in the UK; you have fulfillment centers around the world.
Yeah, we’ve now got four sites. We’re in the UK, we’ve got two sites in the US, in Columbus, Ohio, and just over one up in Vegas, and we’ve got another site in Auckland. So it’s growing pretty quick, and I think this year we’re opening two more sites.
This year 2022?
Sorry, yeah - we opened one site this year, which is the Vegas one… Oh, and Venlo; that’s the Netherlands… And yeah, we’ve got plans for two more sites next year, I believe.
Nice. So an international shipping company that shipped 5 million orders in the last six-seven months. Very nice.
Funny story on that… I’d love to imagine it was just me, sat there, counting orders as they go out the door, but we’ve actually got a big LED sign that’s mounted to the wall, and every time an order dispatches, it ticks up. It’s a nice bit of fun. There’s one in the office and there’s one mounted on the wall in the fulfillment center, and it’s quite interesting to see that ticking up, especially this time of year, when the numbers really start to move.
Yeah. Okay, okay. So for the listeners that haven’t listened to episode #49 yet, and the keyword is “yet”, right? That’s a nudge; go and check it out… What is it that you do?
Yeah, so I mischaracterized myself last time as a 4PL; we’re actually a 3PL. I was corrected. And essentially, we act on behalf of our clients. So imagine you’re somebody that sells socks, and you have a Shopify account, and you come to us and we connect to your Shopify account, we ingest your orders, and we send them out to your customers via the cheapest shipping method, whether that be like Royal Mail in the UK, or even like FedEx, going international [unintelligible 00:05:58.17] We handle all of that. And then we provide tracking information back to your customers, and give you insights on your stock management, and – yeah, there’s tons of moving parts outside of just the fulfillment part. It’s all about how much information can we provide you on your stock, to help you inform decisions on when you restock with us.
Okay. So that is James & James. James & James, the company - that’s what the company does. How about you? What do you do in the company?
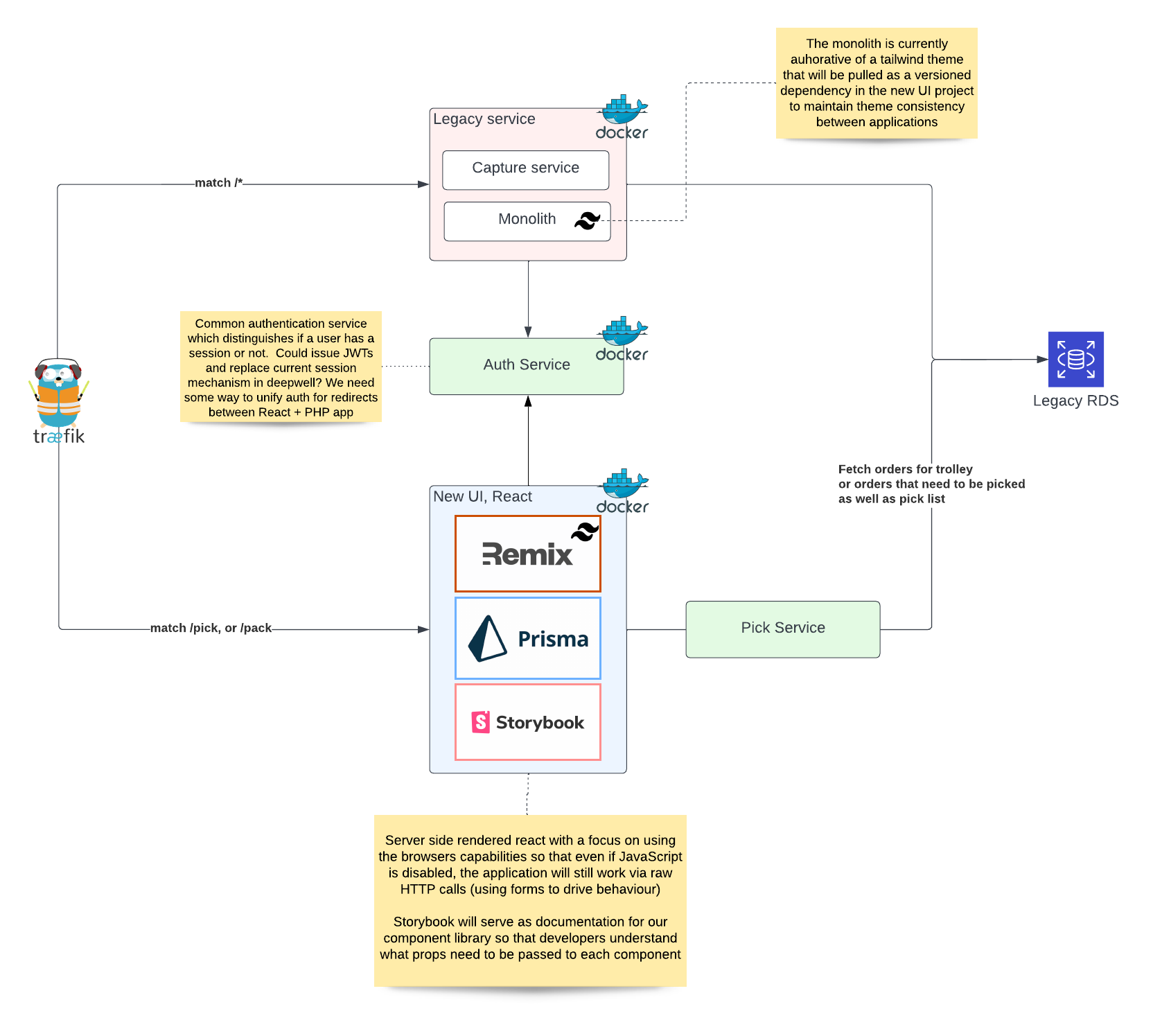
Yeah, so I’ve sort of transitioned through many roles over the last few years. Started this year, I was a senior engineer, and I’ve transitioned to a solution architect role this year. Main motivation for that is we’ve predominantly been a monolithic – we had a big monolith that was on a very legacy version of Symphony; Symphony 1.4, to be specific… And we want to start making tactical incisions to start breaking some of those core parts of our application now into additional services, that use slightly more up-to-date frameworks that aren’t going to take us years to upgrade, say, 1.4 version of Symphony to something modern. We’ve decided it’s going to be easier to extract services out, and put them into new frameworks that we can upgrade as we need to, and it’s sort of my job to oversee all of the technical decisions we’re taking in the framework, but also how we plan upgrades, how we stitch all these new systems together, and most importantly, how we provide sort of like a cohesive experience to the end user. I think there’s six services running behind the scenes. To them it’s just one sort of UI that’s a portal into it all.
Yeah. When you say end users, this is both your staff and your customers, right?
Exactly. We have two applications, one called CommandPort which is our sort of internal tool where we capture orders, and pick and pack them and dispatch them, and then we have the ControlPort which is what our clients use, which is their sort of portal into what’s going on inside the warehouse, without all of the extra information they don’t really care about.
[08:08] Okay. And where do these services – I say services; I mean, where do these applications run? Because as you mentioned, there’s multiple services behind them. So these two applications, where do they run?
Yeah, so they run in AWS, on some EC2 instances, but we have recently created an EKS cluster for all of our new services, and we’re slowly trying to think about how we can transition our old legacy application into the cluster, and start spinning down some of these old EC2 instances.
Okay. I remember in episode #49 that’s what we started talking about, right? Like, the very early steps towards the Kubernetes architecture, or like Kubernetes-based architecture, to see what makes sense, what should you pick, why would you pick one thing over another thing… That’s been six months ago. How did it work in practice, that migration, that transition?
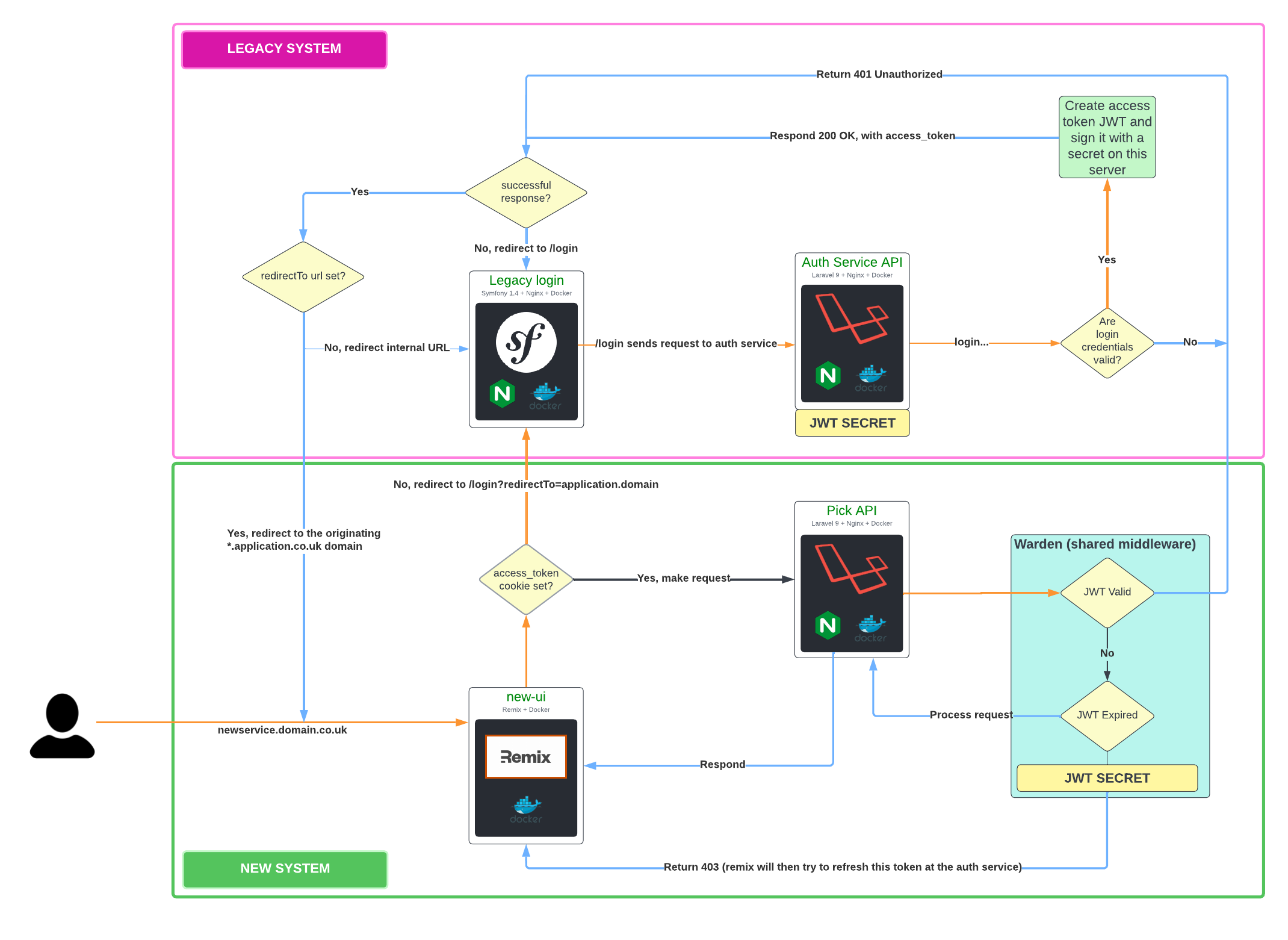
Yeah, so it worked pretty well. So one of our biggest projects over these last six months has been to rewrite Pick, which is one of our largest parts of our operation, into a new application. So what we ended up doing - we created a Remix application, which is a React framework, and that’s deployed on the edge using Lambda, just so you get pretty much fast response times from wherever you’re requesting it from… So that sits outside the cluster. And then we have a new Pick API, which is built using Laravel; that’s deployed inside of EKS, and also a new auth service, which is deployed inside of EKS as well.
So currently, the shape of our cluster is two services running inside of EKS, and then our EC2 instances make requests into the cluster, and that lambda function also makes requests into the cluster. We have three nodes in there, operating on a blue/green deploy strategy. It was actually really interesting, we got bitten by a configuration error.
Okay…
This might make you laugh… To set the scene - it’s Friday night, the shift is just handed over to the next shift manager in the FC. We’ve been Canary-releasing one or two operators for the last two weeks, doing some testing in production on the new Pick service, and everything’s been going flawlessly. We’re like “This is such a great deployment. We’re happy. There’s been no errors. Let’s roll it out to 30% of everybody that’s running on tonight’s shift.”
And earlier that day, I was speaking with one of our ops engineers, and I said, “It’s really bugging me that we only have one node in our cluster. It doesn’t really make much sense. Could we scale it to three nodes, and then also do blue/green deploy on that?” He was like, “Yes, sure. No worries.” We added two more nodes to the cluster, we deployed the app over those three nodes. He sort of looked at the state of Kubernetes, and he was like, “Yeah, it’s great. I can see all three instances running, I can see traffic going to all of them… Yeah, no worries. Call it a day.”
I started getting pinged on WhatsApp, and they’re saying “Everything in Pick’s broken. If we refresh the page, it takes us back to the start of our Pick route. We’re having to rescan all the items again… Someone’s got a trolley with 100 stops on it, and they’re having to go to the start…” And I’m like “What the f is going on?” And it turned out that in the environment variables that we’d set for the application, that we’d set the cache driver to be filed instead of Redis.
Ahh… Okay.
So as soon as someone got directed to another node, they lost all of their progress, and they were getting reset. So that taught me to not just deploy on a Friday night and be happy that the tests passed, because…
Oh, yes. And then I think – because you’ve been testing with like a single instance, right? …and everything looked good. So going from one to three seemed like “Sure, this is gonna work. No big deal.” It’s so easy to scale things in Kubernetes when you have that.
Yeah…
And then things like this… “Ah… Okay.” That sounds like a gun to your foot. What could possibly happen? [laughs] Okay, wow…
[12:10] It was really nice to have an escape hatch, though. So we deployed everything behind LaunchDarkly. So we have feature flags in there. And literally, what I did is I switched off the – scaled the rollout down to 0%, everyone fell back to the old system, and it was only the cached state that was poisoned. So their actual state of what they picked had all been committed to the database. So as soon as I scaled that down to zero, they fell back to the old system, and were able to continue, and I think we only really had like 10 minutes of downtime. So it was really nice to have that back-out method.
Yeah… But you say downtime - to me, that sounds like degradation, right? 30% of requests were degraded. I mean, they behaved in a way that was not expected. So did – again, I’m assuming… Did the majority of users have a good experience?
No, everybody that was being targeted – sort of 30% of operators that were going to the new service, everyone had a bad experience.
Right. But the 70% of operators, they were okay.
Oh yeah, exactly.
Yeah. So the majority was okay. Okay… Well, feature flags for the win, right?
Yeah, it was really nice, because this is the first time we’ve deployed a new service like this, and it was the first time trying feature flags. And even though we had an incident, it was really nice to have that graceful backout, and be confident that we could still roll forward. And in the WhatsApp chat with our operations manager, we were just sending emojis… roll forward, and it’s like, rolling panda down a hill. He was just like “Yeah, no worries…”
[laughs] That’s what you want. That’s it. That’s the mindset, right? That’s like the mindset of trying something new. You think it’s going to work, but you can never be too confident. The more confident you are, the more – I don’t know, the more painful, I think, the failure… Like, if you’re 100% confident it’s going to work and it doesn’t, what then? Versus “I think it’s going to work. Let’s try it. I mean, if it won’t, this is the blast radius… I’m very aware of the worst possible scenario, and I’m okay with that risk”, especially comes to production, especially when it comes to systems that cost money when they’re down. So imagine if this would have happened to 100% of the stuff. I mean, you’d be basically stopped for like 10 minutes, and that is very costly.
Yeah. And it’s been really nice to see like the mindset of people outside of tech evolve over the past couple of years. There was a time where we would code-freeze, everything would be locked down, and nothing would happen for two months. And slowly, as we’ve started to be able to introduce things that mitigate risk, the mindset of those people external to us has also changed, and it’s just a really nice thing to see that we can keep iterating and innovating throughout those busy periods.
Once you replace fear with courage, amazing things happen. Have the courage to figure out how to apply a change like this… Risky, because all changes are risky if you think about it, in production. The bigger it is, the hotter it runs, the more important the blast radius becomes. I don’t think that you’ll never make a mistake. You will.
No, exactly.
Sooner or later. The odds are in your favor, but every now and then, things go wrong. Cool. Okay.
I mean, I was very confident with this until I realized I’d broken all of the reporting on that service that I shared in the last episode; it just completely fell on its face.
Really?
[15:46] Because I found in the old system it did two saves, and we use change data capture to basically analyze the changes on the record as they happen in real time with Kafka. And it ultimately did two saves. It did one to change the status of a trolley from a picking state to an end shift state, and one change to divorce the relationship with the operator from that trolley. And in the application that consumes it, it checks for the presence of the operator ID that needs to be on the trolley, and the status needs to change in that row. If that case wasn’t satisfied, it would skip it, and that trolley would never be released, which means the report would never be generated.
And what ended up happening is I saw that old code and went “Why would I want to do two saves back to back, when I can just bundle it all up into one and be like micro-efficient?”
[laughs] Of course.
“Oh, okay. Yeah, I’m just gonna take down like a week’s worth of reporting.” Yeah, that wasn’t fun.
All great ideas.
We could live without it, though. It’s all edge stuff, and – yeah, we can live without it. It’s fixed now, but… Yeah, finding those things and going “Oh, my god, I can’t believe that’s a thing…”
Okay… That’s a good one. So you had two, possibly the biggest events – no, I think they’re probably the biggest events. I mean, I don’t work in the physical shipping world, but I imagine that Black Friday and Christmas are the busiest periods for the shipping industry as a whole. I think it’s like the run-up, right? Because the things have to be there by Black Friday, and things have to be there by Christmas. How did those two major events work out for you with all these changes to the new system that started six months ago?
So to give an idea of what our normal sort of daily volume is, and maybe set the scene a bit - we’re normally about 12,000 orders a day, I think, and on the ramp up to Black Friday, from about the 20th of November, we were up to release 20,000 a day. And on Black Friday I think 31,000 was our biggest day of orders. And to also set the picture a little bit better, in the last six months I said we’ve done about 5 million orders; in the last 15 days, we’ve done about 400,000 orders across all of our sites.
That’s a lot.
So yeah, volume really ramps up. And we were really, really confident this year, going in from like a system architecture perspective . We’d had a few days where we had some spiky volume and nothing seemed to let up, but it seemed to all – not start going wrong, because we never really had a huge amount of downtime… But a lot of our alarms in Datadog were going off, and Slack was getting really bombarded, and we had a few pages that were 503ing, because they were just timing out… We were suddenly like “What’s going on? Why is the system all of a sudden going really slow?” And we’d released this change recently called “label at pack.” And essentially, what it did is as you’re packing an order, previously, you’d have to like pack all the items, and then once you’ve packed all the items, you weighed the order, and then once you’ve weighed the order, you wait for a label to get printed… But it was really slow, because that weighing step you don’t need; you already know what’s going in the box, you know what box you’re choosing, so you don’t need that weigh step. And it means as soon as you start packing that order, we can in the background go off and make a request to all of our carriers, quote for a label, and print it.
So at the time that you finished packing all the stuff in the box, you’ve got a label ready to go. But what we didn’t realize is that AJAX request wasn’t getting fired just once; it was getting fired multiple times. And that would lead to requests taking upwards of like sometimes 30 or 40 seconds to print a label… If you have tens of these requests going off, and we’ve got 80 packing desks, that’s a lot of requests that the system’s making, and it really started to slow down other areas of the system. So we ended up putting some SLOs in, which would basically tell us if a request takes longer than eight seconds to fire, we’ll burn some of the error budget. And we said “Oh, we want 96% of all of our labels to be printed within eight seconds.” And I think within an hour, we burned all of our budget, and we were like, “What’s going on? How is this happening?” And it was only when we realized that the AJAX request was getting fired multiple times that we changed it. And as soon as that fix went out, the graph was like up here, and it just took a nosedive down, everything was sort of printing within eight or nine seconds, and the system seemed to be a lot more stable.
[20:24] There’s also a few pages that are used for reporting, they’re like our internal KPIs to see how many units and orders we’ve picked, and operator level, by day, week, month… And they’re used a lot by shift managers in the FC. And historically, they’re a bit slow… But in peak, when we’re doing a lot more queries than normal, we’re going really slow. I think – what was happening? I’m not sure how much technical detail you want to go into…
Go for it.
Yeah, we use ORM in our legacy application, and we greedy-fetch a lot of stuff.
Okay…
We definitely over-fetch…
From the database, right? L
From the database.
You’re getting a lot of records, a lot of rows; any scanning, anything…
Yeah, just tons of rows, and we’ve got a reasonably-sized buffer pool. So all those queries run in memory. But what happens is when the memory in the buffer pool is used up, those queries will start running on disk. And once they start running on disk, it significantly degraded performance.
Yeah. Let me guess - spinning disks? HDDs?
So I thought we’d upgraded to SSDs on our RDS instance, but I need to go back and clarify that.
That will make a big difference. And then there’s another step up; so you go from HDDs to SSDs, and then you go from SSDs to NVMEs.
Yeah, I think that’s where we need to go. I think we’re at SSD, but it’s still on those – like, scanning millions of rows queries, and over-fetching like 100 columns or more at a time, maybe 200 columns, the amount of joins that those queries are doing… Yeah, they’re going straight into the table. But yeah, they were essentially taking the system offline because they would just run for like 10-15 minutes, eat a connection up for that entire time, and then you’ve got someone out there hitting Refresh, so you’ve got 30 or 40 of these queries being ran, and no one else can make requests to the database, and it chokes. So we ended up finding that if we changed, or forced different indexes to be used in some of those queries, and reduced the breadth of the columns, they are able to still run, within tens of seconds; so it’s still not ideal, but it was enough to not choke the system out.
And luckily, these things all started happening just ahead of Black Friday, so then we were in a much better position by the time Black Friday came along. We also found that we accidentally, three years ago, used Redis keys command to do some look-ups from Redis, and didn’t realize in the documentation it says “Use this with extreme care in production, because it doesn’t onScan over the entire cell.”
Okay…
Yeah. And when you’ve got 50 million keys in there, it locks Redis for a while, and then things also don’t work. So we swapped that with scan, and that alleviated a ton of stress on Redis. So yeah, there’s some really pivotal changes that we made this year. They weren’t massive in terms of like from a commit perspective, but they made a huge difference on the performance of our system.
That’s it. I mean, that’s the key, right? It doesn’t matter how many lines of code you write; people that still think in lines of code, and like “How big is this change?” You actually want the really small, tiny decisions that don’t change a lot at the surface, but have a huge impact. Some call them low-hanging fruit. I think that’s almost like it doesn’t do them justice. I think like the big, fat, juicy fruits, which are down - those are the ones you ought to pick, because they make a huge difference to everything. Go for those.
I’m wondering, how did you figure out that it was the database, it was like this buffer pool, and it was the disks? What did it look like from “We have a problem” to “We have a solution. The solution works”? What did that journey look like for you?
[24:12] Yeah, so I’m not sure how much of this was sort of attributed to luck… But we sort of dived straight into the database.
There’s no coincidence. There’s no coincidence, I’m convinced of that. Everything happens for a reason. [laughs]
There’s no correlation.
You just don’t know it yet. [laughs]
But yeah, we just connected to the database, to the Show Process list and saw that the queries had been running for a long time… It’s like “Hm… We should probably start killing off all these ones that have been sat there for like 1000 seconds. They don’t look healthy…” [laugh]
Okay. So before we killed them, we sort of copied the contents of that query, pasted it back in, and put an “explained” before, and just sort of had a look at the execution plan… And then saw how many rows it was considering, saw the breadth of the columns that are being used by that query, and then when we tried to run it again, it gives you sort of status updates of what the query is doing. And when it’s just like copying to temp table for about over two minutes, you’re like “That’s probably running in disk and not in memory.” So there’s a bit of an educated assumption there of – we weren’t 100% confident, that’s what was happening, but based on what the database was telling us it’s doing, we were probably assuming that’s what was happening. Now, none of us are DBAs, I just want to sort of clear that up… But that was our best educated guess, correlated with what we could find online.
Is there something that you think you could have in place, or are thinking of putting in place to make this sort of troubleshooting easier? …to make, first of all figuring out there is a problem and the problem is most likely the database?
So we already have some of that. We use APM in Datadog, and it automatically breaks out like queries as their own spans on a trace, so you can see when you’ve got a slow-running query. And we do have some alarms that go off if queries exceed a certain breakpoint. But there are certain pages and certain queries that we understand are slow, and we kick those into like a “Known slow pages” dashboard, that we don’t tend to look at as much, and we don’t want bombarding Slack, because we don’t want to be getting all these alarms going off for things we know are historically slow.
There’s a few of us on the team - shout-out to George; he’s a bit of a wizard on Datadog at the moment, and really gets stuck in there and building these dashboards. And those are the dashboards that we tend to lean towards first; you can sort of correlate slow queries when disk usage goes up on the database, and those dashboards are really helpful… But normally, when we’re in the thick of it, the first thing that I don’t run to is Datadog, and I don’t know why, because it paints a really clear picture of what’s going on.
I tend to – I think it’s muscle memory, and… Over the past five years, when we didn’t have Datadog, I would run straight to the database ,first and start doing – show the process log, and what’s in there, and why is that slow… And then I’d forget to go check our monitoring tool. So I think for me there’s a bit more of a learning curve of how do I retrain myself to approach a problem looking at our tooling first, rather than at the database.
Okay. So Datadog has the APM stuff. From the application perspective, what other integrations do you use to get a better understanding of the different layers in the system? Obviously, there’s the application, there’s the database server itself, then there’s the - MySQL or Postgres SQL?
We use MariaDB.
MariaDB, okay.
So it’s a variant of MySQL.
In my head - MySQL. Legacy - MySQL. [laughs] It’s like a fork… Like, “Which what is it?” The MySQL fork. So I don’t know, does Datadog have some integration for MySQL MariaDB, so that you can look inside of what’s happening in the database?
I believe it does. And I think we actually integrated it. I just have never looked at it.
Oh, right. You’re just like not opening the right tab, I see… [laughs]
Yeah, because if I look at integrations, we’ve got like 15 things enabled. We’ve got one for EKS… Oh, we do have one for RDS, so we should be able to see… We have it for Kafka as well, so we can see any lag that on topics, and when consumers stop responding… So those sorts of things alert us when our edge services are down. Yeah, I think we monitor a lot, but we haven’t yet fully embraced the culture of “Let’s get everyone to learn what’s available to them”, and that’s something that I hope we sort of shift more towards in ’23.
That sounds like a great improvement, because each of you having almost like a source of truth… Like, when something is wrong, where do I go first? Great. And then when I’m here, what happens next? So having almost like a – I want to call it like play-by-play, but it’s a bit more than that. It’s a bit of “What are the important things–”, like the forks, if you wish, in the road, where I know it’s the app, or it’s the instance, like the frontend instances if you have such a thing, or it’s the database. And then even though we have services – I think services make things a little bit more interesting, because then you have to look at services themselves, rather than the applications… And then I know there’s tools… Like, service meshes come to mind; if anything, that’s the one thing that service meshes should help with, is understand the interaction between services, when they degrade, automatic SLIs, SLOs, all that stuff.
So that’s something that at least one person would care about full-time, and spent full-time, and like they know it outside in, or inside out, however you wanna look at it; it doesn’t really matter… But they understand, and they share it with everyone, so that people know where to go, and they go “That’s the entry point. Follow this. If it doesn’t work, let us know how we can improve it”, so on and so forth. But that sounds – it’s like that shared knowledge, which is so important.
[32:17] It’s a bit of an interesting place, because we have a wiki on our GitHub, and in that wiki there are some play-by-plays of common issues that occur. I think we’ve got playbooks for like six or seven of them, and when the alarm goes off in Datadog, there’s a reference to that wiki document.
So for those six or seven things, anybody can respond to that alarm and confidently solve the issue. But we haven’t continued to do that, because there aren’t that many common issues that frequently occur, that we’ve actually then gone and applied a permanent fix for you. We’ve got a few of these alarms that have been going off for years, and it’s just like, “Hey, when this happens, go and do these steps”, and you can resolve it. And as a solutions architect, one of my things that I really want to tackle next year is providing more documentation over the entire platform, to sort of give people a resource of “Something’s happened in production. How do I start tracing the root cause of that, and then verifying that what I’ve done has fixed it for any service that sort of talks about that?” But yeah, we’re not there yet. Hopefully, in our next call we touch on that documentation.
Yeah, of course. The only thing that matters is that you keep improving. I mean, to be honest, everything else, any incidents that come your way, any issues - opportunities to learn. That’s it. Have you improved, having had that opportunity to learn? And if you have, that’s great. There’ll be many others; they just keep coming at you. All you have to do is just be ready for them. That’s it. And have an open mind.
And I’m wondering… So I know that the play-by-plays and playbooks are only so useful, because almost every new issue is like a new one. Right? You haven’t seen that before. Would it help if you’re able to isolate which part of the system is the problem? The database versus the CDN (if you have such a thing), network, firewall, things like that?
Yeah, it would be really useful. And one thing we’re trying to do to help us catalog all of these is anytime we have an incident. We’ve not gone for propper incidents [unintelligible 00:34:19.25] We were looking at incident.io. We haven’t sprang for it yet. We just have an incidence channel inside of Slack, and we essentially start a topic there, and we record all of the steps that happened throughout that incident inside of that log. So if we ever need to go back and revisit it, we can see exactly what caused the issue, and also what services or pieces of infrastructure were affected… Because Slack search is pretty nice. You can start jumping into that incidence channel, something’s gone wrong, you do a search and you can normally find something that might point you in the right direction of where you need to steer your investigation. We know it’s not the most perfect solution, but it’s worked so far.
If it works, it works. If it works, that’s it. You mentioned SLI and SLOs, and how they helped you understand better what is happening. I mean, first of all, signaling there’s a problem with something that affects users, and then being able to dig into it, and troubleshoot, and fix it. Are SLIs and SLOs a new thing that you started using?
Yeah, we’re really sort of dipping our toes in the water and starting to implement them across our services. I think we currently have just two SLOs.
It’s better than zero…
Exactly. We haven’t yet decided on SLIs. We’ve got a chat next week with George, and we’re going to sit down and think what components make up this SLO that can sort of give us an indication before it starts triggering that we’ve burned too much of our budget. So we’ve both got like a shared interest in SRE, and we’re trying to translate that into James & James… But yeah, that’s still very much amateur, and just experimenting as we go, but it’s nice to see at the peak this year that the SLA that we did create gave us some real value back… Whereas previously, we would have just let it silently fail in the background, and be none the wiser.
[36:14] Yeah, that’s amazing. It is just like another tool in your toolbox, I suppose… I don’t think you want too many. They’re not supposed to be used like alarms. Right? Especially when, you know you’re like thousands and thousands of engineers… By the way, how many are you now in the engineering department?
I think we’re eight permanent and four contract, I believe.
Okay, so 12 people in total. Again, that’s not a big team, and it means that everyone gets to experience pretty much everything that happens in some shape or form. I think you’re slightly bigger than a two-pizza team, I think… Unless the pizzas are really, really large. [laughter] So you’re not like – sure, it can be one team, and I can imagine that like retros, if you have them, or stand-ups, or things like that are getting a bit more complicated with 12 people. Still manageable, but 20? Forget about it. It’s just like too much.
Yeah, it was getting a bit tough… And what we do now is we have a single stand-up once a week, an hour long. Everyone gets in, and sort of unites their teams, and what we’ve been doing… And then we have like breakout teams. So we’ve got four sub-teams…
That makes sense.
And yeah, we have our dailies with them, and that seems way more manageable.
That makes sense. Yeah, exactly. But still, you’re small enough, again, to have a good understanding of most of the system, right? I mean, once you get to like 20, 30, 40, it just becomes a lot more difficult, because the system grows, more services, different approaches, and maybe you don’t want consensus, because that’s very expensive, right? The more you get, the more expensive that gets; it just doesn’t scale very well.
What I’m thinking is SLIs and SLOs are a great tool. A few of them that you can all agree on, all understand, and at least focus on that. Focus on delivering good SLOs… No; actually, good SLIs, right? SLIs that match, that everyone can agree on, everyone understands, and it’s a bit of clarity in what is a chaotic – because it is, right? When you have two, three incidents happening at the same time… It does happen.
Okay. Okay. So these past few weeks have been really interesting for you, because it’s been the run-up to Christmas. More orders, as you mentioned, the system was getting very busy… What was the day to day like for you? Because I think you were mentioning at some point that you were with the staff, on the picking floor, using the system that you have improved over those months. What was that like?
Yeah, it was really interesting. This year I really wanted to just use the Pick part of the system. So last year I did a bunch of packing of orders, and that was fine. But after spending sort of like four months rewriting Pick, I really wanted to just take a trolley out and just go pick a ton of orders and experience it for myself. So yeah I did three, four days down there, picked like a thousand orders…
Wow… Okay. Lots, lots of socks; too many socks. [laughter] I don’t want to see another pair of socks for a while. But yeah, it was really nice to sort of get down there and involved with everybody, and sort of going around and talking to operators, and then sort of saying parts of the system they liked, but also parts they didn’t like, and parts they felt slowed them down, versus what the old one did… And it got some really, really useful feedback on what we could then put into the system going into 2023. And we try and do – we have like two or three [unintelligible 00:39:41.06] days a year where we will all go down into the FC and we’ll do some picking and packing, or looking in, just so we can get a feel for what’s going on down there, and how well the systems are behaving.
[39:54] But at the peak, when it’s our most busy time of the year, it’s sort of like, everybody, all hands-on deck, we’ll get down there, all muddle in, DJ plays some music in the warehouse, and we’ve got doughnuts and stuff going around, so… It’s a nice time of the year; everybody sort of gets together and muddles in and makes sure that we get all the orders out in time. I did some statistics earlier, and out of the 300,000 orders that left our UK warehouse, we processed them all within a day.
Wow…
So it gives you an idea of how quickly those orders need to come in and get out once we receive them.
That’s a lot of like 300k a day – this is like… How many hours do you work?
It’s a 24/7 operation?
24/7. Okay. So that is 12,500 per hour… That is three and a half orders per second.
That’s crazy, isn’t it?
Every second, 3.5 orders gets ready. Can you imagine that? And that’s like 24/7. That’s crazy. Wow…
And we’re and we’re still quite small in the e-commerce space. It’s gonna be interesting to see where we are this time next year.
Six months ago, you were thinking of starting to use Kubernetes. You have some services now running; you even got to experience what the end users see… What are you thinking in terms of improvements? What is on your list?
Oh, that’s a really hard one… I want to get more tests of our legacy system to run. So we had another incident where we’d essentially deployed a change, and it took production down for like six or seven minutes for our internal stuff… And it would have been caught by a smoke test. Like, outright, the system just wouldn’t have booted. And we’ve now put a deployment pipeline replace which will run those smoke tests and ensure the application boots, and it will just run through a couple of common pages… And that was a result of that incident.
But what we really want to do is gain more confidence that when we deploy anything into production for that existing system, we’re not going to degrade performance, or take down like certain core parts of the application. What we want to probably do is come up with a reasonable time to deploy. Maybe the test harness that runs can’t take more than ten minutes to deploy to production… Because we still want to keep that agility that we’ve got.
One of the real benefits that we’ve got working here is deployment in terms of production is under sort of two or three minutes. And if we have a bug, we can revert really quickly, or we can iterate on it quickly, and push out. So having a deployment pipeline that sits in the way and takes over 10 minutes to run - that’s really going to affect your agility. So yeah, next year I really want the team to work on hardening our deployment pipeline, just so we can keep gaining confidence in what we’re releasing… Especially as we plan to scale our team out, we’re going to have much more commits going through on a daily basis.
Now, when you say deploying, I’m wondering - do you use blue/green for your legacy app?
No. Not yet.
Because if you had two versions running at any given point in time… So the old one, the legacy one, and just basically change traffic, the way it’s spread, then rollbacks would be nearly instant. I mean, the connections, obviously, they would have to maybe reconnect depending on how the app works, where they’re persistent, whether retry… And everything goes back as it was. And if it’s a new one, if it doesn’t boot, so if it can’t boot in your incidents case, then it never gets promoted to live, because it never came up, and it’s not healthy.
Yeah, that would be really nice if we could get that in place. I think our deployment pipeline for legacy at the moment is just - they push these new changes to these twelve nodes, and do it all in one go. And then flush the cache on the last node that you deploy to. It’s very basic. Whereas the newer services do have like all the bells and whistles of blue/green, and integration, unit tests that run against it to give us that confidence.
[44:13] Would migrating the legacy app to Kubernetes be an option?
We’re thinking about it. So only one issue that I’ve run up to so far… So I’ve Dockerized the application, it runs locally, but there’s one annoying thing where it can’t request assets. And this is probably some gap in my knowledge in Docker, is it runs all in its Docker network, and then when it tries to go out to fetch assets, it’s referencing the Docker container name, where it should actually be referencing something else, which would be like outside of that Docker network… And that causes assets to load. So once I fix that, we’ll be able to move into production. But that’s a pretty big deal-breaker at the moment.
Yeah, of course. When you say assets, do you mean static assets, like JavaScript, CSS images, things like that?
Yeah, like our PDFs, and those sorts of things.
Okay. Okay. So like the static files… Okay. Okay. Interesting. I remember – I mean, that took us a while, because the static assets… I mean, in our case, in the Changelog app, before it went on to Kubernetes, it had volume requirements, a persistent volume requirement. And the thing which enabled us to consider, just consider scaling to more than one was decoupling the static assets from the volume from the app. If the app needs to mount a volume, it just makes things very, very difficult. So moving those to S3 made a huge, huge difference. In your case, I’m assuming it’s another service that has to be running; it’s trying to access another service that has the assets.
Yeah, yeah. Because we’ve got a bunch of stuff in S3 and requesting that, it’s fine. But it’s any time it needs to request something that’s on that host, and then it’s using the Docker container name rather than the host name. And the whole reason is just because of the way that legacy application is written; it’s a configuration variable that says, “What’s the name of my service that I need to reach out to?” But when you’re accessing it externally into the container, you can resolve it with the container name; but when the container tries to resolve it internally to itself, it then falls over and doesn’t work.
Oh, I see what you mean. Okay. Okay. And you can’t make it like localhost, or something like that.
Exactly. On my local machine, it’s like manager.controlport.local. But then internally, Docker would see that as DefaultPHP, which is the name of the container. But it’s trying to go for the manager.controlport.local, which doesn’t exist on that network. So then it just goes “I don’t know what you’re talking about”, and that’s the end of it.
Well, as it’s becoming obvious, I am like – how shall I say? How should I say this? I’m like a magpie. It’s a shiny thing, I have to understand “What’s the problem?” “The problem?” Like, “Oh, I love this. Like, tell me more about it.” I’m basically sucked into troubleshooting your problem live as we’re recording this… [laughter] Okay, I think we’ll put a pin in it for now, and change the subject. This is really fascinating… But let’s go to a different place. Okay. What are the things that went well for you, and for your team, in the last six months, as you’ve been improving various parts of your system?
Yeah. So I think the biggest thing that’s been really our biggest success in this year is that whole rewrite of the Pick application. The fact we went from no services – I just sort of want to be clear as well, when I talk about services, how we’re planning to structure the application, we’re not going like true microservice, like hundreds of services under each domain part of the system. What we’re really striving to do is say - we have this specific part of domain knowledge in our system; say like Pick, for example. We also have Pack, and maybe GoodsIn. And we want to split those like three core services out into their own applications, and as we scale the team, we’ve then got the ability to say, “Team X looks after Pick. Team Y looks after Pack.” And they’re discrete and standalone, so we could just manage them as their own separate applications.
[48:25] Is there a Poc? I had to ask that… There’s Pick, this Pack… There has to be a Poc. [laughter] Those are so great names.
Yeah, no Poc…
Okay, there’s lots and lots of POCs. Right? Lots of proof of concepts.
Yeah… We had a POC six months ago, and it’s now actual real production. It’s now Pick. It evolves from a POC to a Pick.
Right.
Yeah. It was really fascinating to sort of go from – we’ve never put a microservice out into production, and we’ve now somehow got this cluster that’s running to microservices… And the user experience from the operator’s perspective - they either go to the old legacy application that has its frontend, or the new Remix application. And regardless of which one you go to, it feels like the same user experience. And to build that in six months, and have a cohesive end-to-end experience… Yeah, it’s something that we’re really, really proud of, for delivering that in such a short period of time.
And also to not have that many catastrophic failures on something so big. It is really nerve-wracking, being responsible for carving out something that’s used every single day, building a new variant of it that performs significantly better, but also introduces some new ideas to actually gain operational efficiency. And then to see it like out in the wild, and people are using it, and the operation is still running, nothing’s fallen on its face, apart from when we didn’t set the cache driver to be Redis… But apart from that, it felt seamless. And sort of re-educating the team as well to start thinking about feature flags, and the benefits of Canary releases, and how that gives external stakeholders confidence… Yeah, there’s a lot of new tooling that came in, and I’m really happy with how the team started to adopt it.
Yeah. Not to mention SLIs and SLOs that the business cares about, and the users care about… And you can say, “Hey, look at this. We’re good. The system is too stable; we have to break something, dang it.” [laughs]
[laughs Yeah. I think the next stage is to put a status page up so that our stakeholders and clients can sort of see uptime of the service, and sort of gain an understanding of what’s going on behind the scenes. But we’ll only really be able to do that once we’ve got a list of SLIs and SLOs in place that will drive those.
only if it’s real-time. The most annoying thing is when you know GitHub is down, but GitHub doesn’t know it’s down. It’s like, “Dang it… I can guarantee you that GitHub is down.” Five minutes later, status page, of course it’s down. So that’s the most annoying thing about status pages, is when they’re not real-time. I know there will be a little bit of a delay, like seconds… Even 30 seconds is okay. But I think if it’s SLI and SLO-driven, that’s a lot better, because you start seeing that degradation, as it happens, with some delay; 15-30 seconds, that’s acceptable. Any more than a minute and it’s masking too many things.
Yeah. So I’m completely new to all this stuff. I thought the status page was driven by those SLIs and SLOs. Is that not something that – that’d be really cool.
It depends which… I mean, there’s obviously various services that do this; you pay for them, and it’s like a service which is provided; sometimes it can be a dashboard, a status page. I mean, like a read-only thing. They are somewhat better… It’s just like, deciding what to put on it, you know? And then when you have an incident, how do you summarize that? How do you capture that? How do you communicate to people that maybe don’t need to know all the details, but they should just know there’s a problem. So it’s almost like you would much rather have almost like checks… You know, like when a check fails, it goes from green to red, you know there’s a problem with the thing. It’s near real-time. But you hide, like – because to be honest, I don’t care why it’s down; I just want confirmation that there’s a problem on your end, and it’s not a problem on my end, or somewhere in between.
Okay… So we talked about the status page, we talked about… What else did we talk about? Things that you would like to improve.
Yup, that’s right.
…and the deployment pipeline for legacy.
Ah, yes. That was the one. How could I forget that? A deployment pipeline. Okay, cool. So these seem very specific things, very – almost like it’s easy to imagine, easy to work with… What about some higher-level things that you have planned for 2023? The year will be long, for sure.
Yeah. So we’ve sort of had a big change this year, where [unintelligible 00:53:02.09] We’ve got changes to Pick, and we’re changing Pack next year… But we’re trying to think from like an operational perspective how can we gain more efficiency out of our packers. And right now, when you’ve finished picking a trolley, you put it in like a drop zone, and then someone could – they’re called a water spider. They come in, they grab the trolley, they shimmy it off to the packing desk, and then the packer puts it into a bin, and that water spider comes back and takes the bin that’s full of orders over to a dispatch desk. And what we want to do is start automating that last bit of the journey, from the pack station to dispatch and labeling. Essentially, what we’ll do then is an operator will finish packing their order, they will put it onto a conveyor belt, and that conveyor belt will have a bunch of like sensors on it, which will sort of do weighing as the order is like conveyancing from the pack desk to the outbound desk. And if the order is not within like a valid tolerance that we’re happy with, we will kick it back into a “problem order” bin, which will be like reweighed and relabeled. Because I said earlier, we got rid of the weighing step, and there’s a certain variance that our carriers will tolerate, and say “Yep, that’s fine. It should have been like X amount of grams we’ll still process it.” But if we go like too much under or too much over, we can get chargebacks from the carrier, to say “Hey, you sent us this order, and it didn’t have the correct weight.” So we want to start handling those in-house.
And what’s gonna be really interesting is building the SLOs and SLIs around that. Like, how many orders are we weighing at Pack, we’re skipping and weighing at Pack, and putting it on the conveyancing system and how many orders are we kicking out? And have like an error budget on that, and seeing like how accurate our product weights are in the system, how accurate our packaging weights are… It’s gonna be really interesting to see that in operation next year.
So I think the plan is we’ll probably get an independent contractor to come in and set up the conveyancing. But then we want our own bespoke software running in that pipeline that we can hook into, and start pulling data out of that. And I’m really, really excited to start working on some of those automation pieces.
It’s really interesting how you’re combining the software with the real world, right? So how everything you do – like, you can literally go in the warehouse and see how the software is being used, what is missing, what software is missing, what can be made more efficient… Because what you’ve just described, it’s a real-world process that can be simplified, can be made more efficient by adding a bit more software. And that belt. Very important. With the right sensors.
See, one of the really interesting parts about our company is everything, end-to-end, is bespoke; from like order ingest, to order being dispatched from the warehouse - we control everything in that pipeline.
[56:01] The only things we depend on is buying labels from carriers. I mean, we spoke at some point about managing our own price matrixes in real time of the carriers, and doing our own quoting and printing our own labels… Maybe one day we’ll go in that direction, but it’s a lot of work. And there’s companies out there that are dedicated to doing that, so we have those as partners for now. But apart from that, pretty much everything out in the FC is completely bespoke.
You mentioned FC a couple of times… Fulfillment center.
Yes.
That’s what it is. I was thinking,” What is it? What is FC?” It’s not a football club… [laughter] Because it’s like the World Cup is on, so FC - it’s easy to associate, we’re primed to associate with a football club… So it’s not that. Fulfillment center, that’s what it is.
Yeah. We used to warehouses, but I think fulfillment center is more accurate to what we do.
Do you see more Kubernetes in your future, just about the same amount, or less? What do you think?
So I think purely because we’re moving to a more service-oriented architecture, we’re probably going to continue to depend on Kubernetes. I can’t see how practical a world would be where we have to keep provisioning new EC2 instances, and setting up our deployment pipelines to have specific EC2 instances as targets, and managing all the ingress to those instances manually… It just feels a little bit messy. Having one point of entry to the cluster, and also being able to like pull that from AWS to like GCP in the future if we ever wanted to move cloud providers - I think for us it makes more sense to stay on Kubernetes.
Okay. Technology-wise, Datadog was also mentioned, so I’m feeling a lot of love for Datadog coming from you, because it just makes a lot of things simpler, even though easier to understand, even though it’s not muscle memory just yet… Are there other services that you quite enjoyed using recently?
Yeah. I’m shouting out to Datadog again, but it’s just – it’s another part of their ecosystem; they have something called RUM, real-time user monitoring. And when we actually deployed the Pick service, we were getting tons of feedback, but there was no real way to correlate the weird edge cases people were having, and we installed RUM. Basically, what it does is it records the user session end-to-end, takes screenshots and then uploads it to Datadog, and you can play that session back and watch it through, but it will also have like a timeline of all the different events that that operator clicked on through that timeline. So you can scrub through it and attach as much meta information to that trace as you’d like, just like with any other OpenTelemetry trace.
So in our example, we began to get lost, because we couldn’t correlate a screen recording to some actual like picker data that was stored in S3… Whereas now, we store the picker into S3, which is like all of the raw data that the operator interacts with from an API perspective… But we also take that picker ID and attach it to the trace, along with their user ID, and along with the trolley they were picking on… So now we can just go into Datadog and say, “Hey, give me all the traces for this user, on this trolley.” And if they said like they had a problem on Sunday with that trolley, we can now easily find that screen recording and watch it back. And we can also then correlate that with all of the backend traces that happened in that time period.
So we used to use Datadog and Sentry, and even though I have a lot of love for Sentry, and I think they’re a great product, having it all under one roof and being able to tie all the traces together and get an end-to-end picture of exactly what a journey looked like - I’m really starting to enjoy that experience with Datadog.
Nice. Very nice. Okay. That makes a lot – I mean, it makes sense. I would want to use that. If I were in that position, why wouldn’t I want that? It sounds super-helpful… And if it works for you, it’s most likely to work for others. Interesting. Anything else apart from these two?
[01:00:05.20] I’m trying to think what else I’ve used… I mean, I was looking a bit at Honeycomb, and I really wanted to get it up and running for us, but they don’t yet have a PHP SDK. You have to sort of set it up with an experimental one that’s sort of community-driven. I just haven’t had the time to plug into it. I went through their interactive demos, and I really, really, really want to try it. It’s bugging me that we can’t make it work for us just yet. But no, no additional tooling. Those are the two at the top of my list.
Okay. So as we prepare to wrap up, for those that stuck with us all the way to the end, is there a key takeaway that you’d like them to have from this conversation? Something that – if they were to remember one thing, what would that thing be?
I think don’t be scared to keep moving the needle, and keep iterating on what you’ve got; even if you want to try a new service in production, having the sort of foresight to say “We can gracefully roll this out and scale out, but also gracefully roll it back if we’ve got issues” is really powerful. And from my experience, like I’ve touched on today, the more you do it, the more confidence you can get the rest of your business to have in your deployments. And that sort of leads to being able to keep iterating and deploy more frequently. And that’s what we all want to do, right? We want to just keep making change and seeing like positive effects in production.
How do you replace fear with courage? How do you keep improving?
Just keep failing. Failing and learning from it. Like, there’s no real secret formula. The first time you fail, as long as you can retrospect on that failure and take some key learnings away from it… And I think the more you fail, the better. As long as you’re not failing to the point where you’re taking production completely offline and costing your business like thousands of pounds, and maybe your customers lose confidence in your product… As long as you’ve risk-assessed what you’re deploying and you have a backup strategy, I think that’s how you replace fear with courage - just knowing you’ve got that safety blanket of being able to eject.
Yeah. Well, it’s been a great pleasure, Alex, to watch you go from April, when we first talked, and we posted some diagrams, to now December… You successfully sailed through Black Friday, Christmas as well, a lot of orders, physical orders have been shipped, a lot of socks, by the sounds of it…
Yeah… Everyone’s getting socks for Christmas this year.
Exactly. Yeah, apparently. It’s great to see, from afar, and for those brief moments from closer up, to understand what you’re doing, how you’re doing it, how you’re approaching problems that I think are fairly universal, right? Taking production down. Everyone is afraid of that. Different stakes, based on your company, but still, taking production down is a big deal. Learning from when things fail, trying new things out… It’s okay if it’s not going to work out, but at least you’ve tried, you’ve learned, and you know “Okay, it’s not that.” It’s maybe something else, most probably. And not accepting the status quo. Each of us have legacy. Our best idea six months ago is today’s legacy. Right? And it is what it is; it’s served its purpose, and now it’s time for something new. Keep moving, keep improving… There’s always something more, something better that you can do.
I completely agree. It’s been great to come back on, and i look forward to sharing the automation piece sometime next year.
Yeah. And I’m looking forward to adding some more diagrams in the show notes… Because I remember your 10-year roadmap - that was a great one. I’m wondering how that has changed, if at all… And what is new in your current architecture, compared to what we had. I think this is like the second wave of improvements. Six months ago we had the first wave, we could see how well that worked in production… And now we have the second wave of improvements. Very exciting.
Yeah, I’ll send those over when I have them.
Thank you, Alex. Thank you. That’s a merry Christmas present, for sure. Merry Christmas, everyone. See you in the new year.
Merry Christmas. Cheers.
Our transcripts are open source on GitHub. Improvements are welcome. 💚