The new changelog.com setup for 2020
Now running on Linode Kubernetes Engine (LKE)
We talked about the changelog.com setup for 2019 in episode #344, and also captured it last year in this post. At the time, changelog.com was running on Docker Swarm, everything was managed by Terraform, and the end-result was simpler & better because:
- We traded Ansible’s imperative approach for Terraform’s declarative one
- We delegated Docker management to CoreOS
- We stopped using our own Concourse and switched to CircleCI, a managed CI/CD
This year, we simplified and improved the changelog.com setup further by replacing Docker Swarm and Terraform with Linode Kubernetes Engine (LKE). Not only is the new setup more cohesive, but deploys are 20% faster, changelog.com is more resilient with a mean time to recovery (MTTR) of just under 8 minutes, and interacting with the entire setup is done via a single pane of glass:
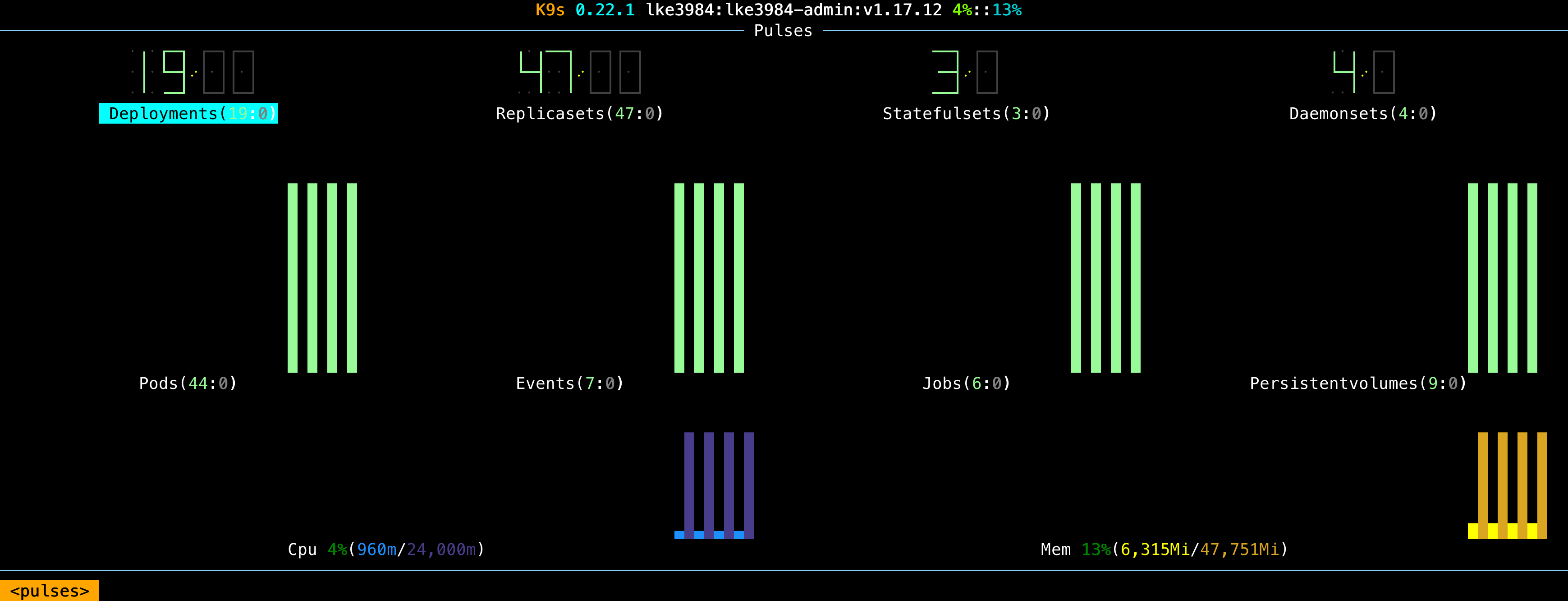
You must be wondering:
- Why Kubernetes?
- How is Kubernetes simpler than what you had before?
- What was your journey to running production on Kubernetes?
We will answer all these questions, and also cover what worked well, what could have been better, and what comes next for changelog.com. Let’s start with the big one:
Why Kubernetes?
Because managing infrastructure doesn’t bring any value to Changelog, the business. Kubernetes enables us to declare stateless & stateful workloads, web traffic ingresses, certificates and other higher level concepts instead of servers, load balancers, and other similar lower-level concepts. At the end of the day, we don’t care how things happen, as long as the following happens: automatic zero-downtime deploys on every commit, daily backups, minimal disruption when an actual server goes away, etc. Kubernetes makes this easy.
Let us expand with a specific example: what business value does renewing the TLS certificate bring? Yes, all web requests that we serve must be secured, and the SSL certificate needs to be valid, but why should we spend any effort renewing it?
Maybe your IaaS provider already manages SSL for you, but does that mean that you are forced to use the CDN service from the same provider? Or does your CDN provider manage one certificate, and your IaaS provider another certificate?
In our case, even if Fastly, our CDN partner, can manage Let’s Encrypt (LE) certificates for us, we need to figure out how to keep them updated in our Linode NodeBalancer (a.k.a. load balancer). We have learned this the hard way, but if Fastly manages LE certificates for a domain, no other LE provisioner can be configured for that domain. Our load balancer needs TLS certificates as well, and if we use LE via Fastly, we can’t get LE certificates for the load balancer. While this is a very specific example from our experience, it shows the type of situations that can take away time & effort from higher-value work.
In our Linode Kubernetes Engine setup, cert-manager is responsible for managing certificates for all our domains, and a job keeps them synchronised in Fastly. If we need to check on the state of all our certificates, we can do it from the same pane of glass mentioned earlier:

How is Kubernetes simpler?
A single Linode CLI command gets us a managed Kubernetes cluster, and a few commands later we have changelog.com and all its dependent services up and running, including DNS, TLS & CDN integration. We no longer provision load balancers, or configure DNS; we simply describe the resources that we need, and Kubernetes makes it happen.
Yes, we need to install additional components such as ingress-nginx, cert-manager, postgres-operator and a few others, but once we do this, we get to use higher-level resources such as PostgreSQL clusters, Let’s Encrypt certificates and ingresses that handle load balancer provisioning.
Did I mention that the Kubernetes is managed? That means updates are taken care of, and the requested number of nodes will be kept running at all times. If one of the VMs that runs a Kubernetes node gets deleted, it will be automatically re-created a few minutes later, and everything that should be running on it will be restored. This changes the conversation from the IaaS provisioner needs to run and converge on the desired state to Kubernetes will automatically fix everything within 10 minutes.
How does this help you?
We are convinced that you have heard about “production Kubernetes” many times in recent years. Maybe you have even tried some examples out, and had it running on your local machine via Kind or k3sup. For the vast majority, the beginning is easy, but running production on Kubernetes is hard. Many who start don’t fully complete the migration. Even with Monzo and Zalando sharing Kubernetes in production stories for years, it doesn’t make it any easier for you.
The best way that we can think of helping your production Kubernetes journey is by making all our code available, including all the commit history that got us where we are today. If you spend time exploring past commits, you will even find links to public discussions with our technology partners that lead to specific improvements in Linode Kubernetes Engine (LKE), as well as other related areas such as kube-prometheus & fastly-cli.
Changelog.com is proof that running on production on Kubernetes can be straightforward, and it works well. Even if your team is small and time available for infrastructure-related work is limited, you can use our approach to get you going, then modify and adapt as and when needed. If changelog.com has been running on this setup with improved availability, responsiveness and resiliency, so can your production web app.
Tell me more about your Kubernetes journey
It all started at KubeCon + CloudNativeCon North America 2019 (remember #374 & #375?), when I met with Hillary & Mike from Linode. They gave me early access to Linode Kubernetes Engine (LKE) and one Linode CLI command later, we had our first three-node Kubernetes cluster running in Newark, New Jersey.
By the way, if you want early access to new Linode new products before they hit the market and provide valuable feedback to influence product direction, you can join Linode Green Light too.
The first few baseline components were fairly straightforward:
- ingress-nginx for TCP routing, automatically integrated with Linode NodeBalancers
- external-dns for automatic DNS management
- cert-manager for TLS via Let’s Encrypt, integrated with external-dns & nginx-ingress
- cert-manager dnsimple extension for wildcard TLS certificates -
*.changelog.com
Monitoring was a bit trickier because we had to figure out how to do Prometheus & Grafana in Kubernetes properly. There is some conflicting advice on how to get this up and running, and the documentation didn’t work for us, so we have contributed our solution. Out of all the available approaches, we have settled on the kube-prometheus operator which gives us plenty of insight into Kubernetes and system metrics out of the box. We are yet to integrate kube-prometheus with other services such as ingress-nginx, PostgreSQL, Phoenix etc.
As soon as we had grafana.changelog.com in place and all baseline components worked well together, we moved to setting up a static instance of changelog.com. This would give us a clear picture of how a simple changelog.com app would work in various conditions (upgrades, loss of nodes, etc.). The resulting artefact was temporary - a stepping stone - which kept things simple and allowed us to observe web request latencies and error rates in various failure scenarios. Our findings gave us confidence in LKE and we gave it the green light by sharing our Linode customer story.
We settled on Crunchy Data PostgreSQL Operator for running our production PostgreSQL on K8S. Just as we have been running PostgreSQL on Docker for years with no issues, PostgreSQL on K8S via Crunchy is an even better experience from our perspective. We are happy with the outcome, even if we don’t leverage all of Crunchy PostgreSQL features just yet.
For zero-downtime automatic app updates, we chose Keel. CircleCI continues to build, test & publish container images to DockerHub. The decision that we have made for our 2019 setup to keep a clean separation between CI & production paid off: we didn’t have to change anything in this part of our workflow. We could build a new second half of the workflow based on Kubernetes, while continuing to run the existing Docker Swarm one. In the new workflow, when the changelog.com container image gets updated, DockerHub sends a webhook event to Keel, which is just another deployment running in LKE. In response to this event, Keel updates the changelog.com deployment because we always want to run the latest commit that passes the build & test stages. Yes, we know that GitOps via Flux or ArgoCD is a more comprehensive and robust approach, but in this case we chose the simplest thing that works for us. Having said that, this discussion with @fwiles makes us think that we should revisit Flux soon.
Throughout our entire changelog.com on Kubernetes journey, Andrew, a Linode engineer, was always there to help with a recommendation, fix or simply bounce some ideas off. We talked about Kubernetes upgrades and helped make them better (first implementation of linode-cli lke pool recycle would update all nodes at once, meaning significant downtime), kicked off PROXY protocol support for LoadBalancer Services, and touched on persistent volumes performance. If there was one thing that captures our interaction with Andrew best, it is this highly detailed & clear example on how to configure PROXY protocol support on LKE.
Thank you for all your help Andrew, we really appreciate it.
What worked well & what could be better?
All put together, the time that it took us to migrate from Docker Swarm to Kubernetes was around three weeks. Most of this time was spent experimenting and getting comfortable with the baseline components such as ingress-nginx, external-dns, cert-manager etc. Taking into account how complex the K8S ecosystem is regarded to be, I would say that our changelog.com migration to LKE worked well.
There is room for improving the performance of persistent volumes in LKE. When we disabled the CDN, disk utilisation for the persistent volume which serves all our media went up to 100% and stayed there for the entire duration of this test scenario. As unlikely as this is to happen, a cold cache would mean high latencies for all media assets. The worst part is that serving the same files from disks local to the VMs is 44x faster than from persistent volumes (267MB/s vs 6MB/s). Even with Fastly fronting all changelog.com media, this is what cache misses mean for disk IO utilisation & saturation:

During our migration, we had HTTP verification configured for Let’s Encrypt (LE) certificates. With the DNS TTL set to 3600 seconds, after the changelog.com DNS A record was updated to point to LKE, a new certificate could not be obtained because LE was still using the previous, cached changelog.com A record for verification. Having hit the LE certificate request limit, combined with the fact that we didn’t change the default DNS TTL of 3600 in external-dns, we ended with about 30 minutes of partial downtime until the A record revert propagated through the DNS network. We have since switched to DNS-based verification for LE, and are now using a wildcard certificate, but this aspect of the migration did not work as well as it could have.
Linode Kubernetes Engine (LKE) worked as expected. The interaction with Linode was spot on, all improvements that were required for our migration have shipped in a timely manner, support was always responsive and progress was constant. Thank you Linode!
What comes next for changelog.com on LKE?
To begin with, we are still playing the manual upgrade game. Now that we are on LKE, we want to automate K8S upgrades, baseline components upgrades (ingress-nginx, cert-manager etc.) as well as app dependency upgrades (Erlang & Elixir, PostgreSQL, etc.). We know that it’s a tall order, but is now within our reach considering the primitives that the Kubernetes ecosystem unlocks. The first step will be to upgrade our existing K8S v1.17 to v1.18 so that we are running on a supported version, as well as all other components that had significant releases in the last 6 months (cert-manager for example shipped 1.0 since we started using it).
We would very much like to address the persistent volume limited performance on LKE. Even if with some work we could migrate all media assets to S3, we would still have to contend with our PostgreSQL performance, as well as Prometheus which is highly dependent on disk performance. The managed db service that Linode has on the 2020 roadmap might solve the PostgreSQL performance, and Grafana Cloud may be a solution to Prometheus, but all these approaches seem to be solving a potential LKE improvement by going outside of LKE, which doesn’t feel like a step in the right direction. As an aside, I am wondering if our friends at Upbound - hi Jared & Dan 👋🏻 - would recommend Rook for pooling local SSD storage for persistent volumes on LKE? 🤔
I am very much looking forward to integrating all our services with Grafana & Prometheus, as well as Loki which is still on our TODO list from last year. We are missing many metrics that are likely to highlight areas of improvement, as well as problems in the making that we are simply not aware of. Centralised logging running on LKE, alongside metrics, would be very nice to have, especially since this would enable us to start deriving more business outside of the app, which is currently hand-rolled with PostgreSQL & Elixir. While this approach works well, I know that we could do so much better, and take business insights into directions that right now are unfathomable.
Another thing on our radar is picking up OpenFaaS for certain tasks that we still run outside of LKE, and for which we use Ruby scripting. While we could rewrite them to Elixir so that everything runs within the same app, it seems easier to lift and shift the Ruby code that has been working fine for years into one or more functions running on OpenFaaS. Well spotted, the hint was in the video above. 😉
As always, our focus is on steady improvement. I feel that what we delivered in 2020 is a significant improvement to what we had before. I am really looking forward to what we get to build for 2021, as well as sharing it with you all!
Until next time 💙 Gerhard.
Listen to the full story on The Changelog #419!
Did you know?
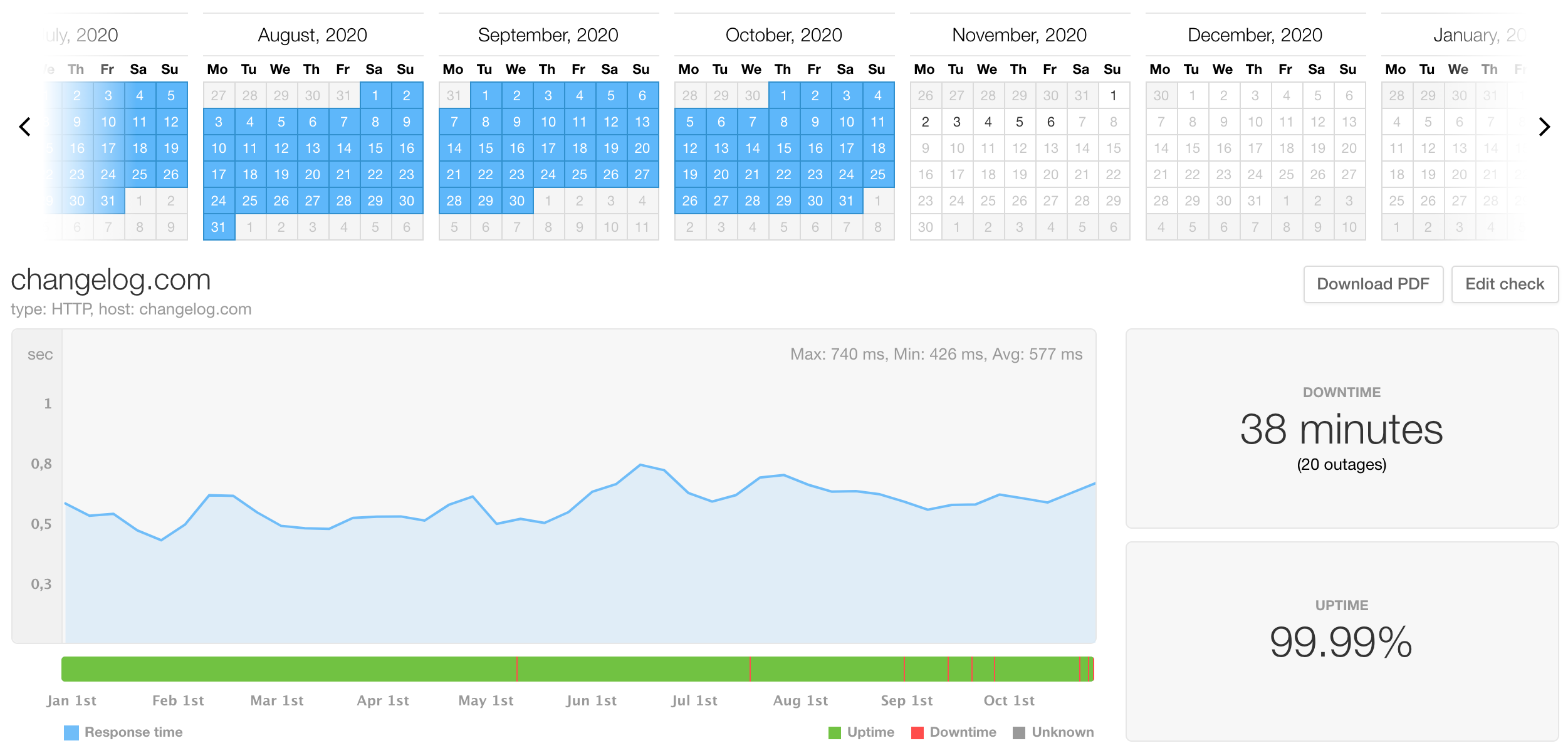
changelog.com availability SLO is 4 nines, (99.99%) which translates to just over 50 minutes of downtime in one year. Our 2019 availability SLI was 3 nines and a 6 (99.96%) with over 220 minutes of downtime. A misconfigured Docker service was the main reason, but we also had 50 micro downtimes of a minute or two.
With an ongoing LKE migration, our 2020 availability SLI stands at 4 nines, with 38 minutes of downtime currently. Most of it was due to my DNS & LE certificate blunder hit during the migration to LKE, but with 2 months to go, our availability SLI is almost 6 times better this year compared to the previous one.
Discussion
Sign in or Join to comment or subscribe
2020-11-21T22:20:14Z ago
Nice write-up, thanks!
Do you plan to use anything such as OpenTelemetry?
opentelemetry-beamhas some very interesting packages, but they seem quite immature currently.For instrumenting Elixir apps, how do you feel
telemetryandtelemetry_metrics_prometheusare positioned, are they viable for Changelog?Gerhard Lazu
UK
Make it work. Keep improving.
2020-12-03T05:55:47Z ago
The plan is to jam with Alex & roll out https://github.com/akoutmos/prom_ex this week. prom_ex is built on top of
opentelemetry-beam&telemetry. I can feel that a blog post on this subject for early 2021 is already in the making 😉Gerhard Lazu
UK
Make it work. Keep improving.
2020-12-27T17:40:11Z ago
@tobbbles this was shipped about a week ago: https://github.com/thechangelog/changelog.com/pull/340
Alex Ellis
London, UK
I help companies on their Cloud Native journey. CNCF Ambassador. OpenFaaS Founder.
2020-12-27T09:35:42Z ago
I saw your post reappear on Hacker News yesterday, up on the front page. Congrats!
Gerhard Lazu
UK
Make it work. Keep improving.
2020-12-27T17:41:17Z ago
Thanks, it turned out to be a great discuss: https://news.ycombinator.com/item?id=25543838 🙌🏻