
That is the question. Whether ’tis nobler in the mind to suffer the slings and arrows of outrageous test coverage, or to take arms against a sea of bugs…
Featuring
Sponsors
Sourcegraph – Transform your code into a queryable database to create customizable visual dashboards in seconds. Sourcegraph recently launched Code Insights — now you can track what really matters to you and your team in your codebase. See how other teams are using this awesome feature at about.sourcegraph.com/code-insights
Square – Develop on the platform that sellers trust. There is a massive opportunity for developers to support Square sellers by building apps for today’s business needs. Learn more at changelog.com/square to dive into the docs, APIs, SDKs and to create your Square Developer account — tell them Changelog sent you.
FireHydrant – The reliability platform for every developer. Incidents impact everyone, not just SREs. FireHydrant gives teams the tools to maintain service catalogs, respond to incidents, communicate through status pages, and learn with retrospectives. Small teams up to 10 people can get started for free with all FireHydrant features included. No credit card required to sign up. Learn more at firehydrant.com/
Notes & Links
Chapters
| Chapter Number | Chapter Start Time | Chapter Title | Chapter Duration |
| 1 | 00:00 | Opener | 00:19 |
| 2 | 00:19 | Sponsor: Sourcegraph | 03:04 |
| 3 | 03:24 | It's Go Time! | 00:50 |
| 4 | 04:13 | Welcome, friends | 01:55 |
| 5 | 06:09 | The tweet that started it all | 03:10 |
| 6 | 09:19 | How do you test an API design? | 04:56 |
| 7 | 14:16 | The importance of feedback loops | 02:47 |
| 8 | 17:03 | What TDD really is | 04:50 |
| 9 | 21:53 | Preventing vs actually getting errors | 03:09 |
| 10 | 25:02 | Small vs large projects | 02:00 |
| 11 | 27:15 | Sponsor: Square | 00:52 |
| 12 | 28:23 | Top-down test creation | 05:42 |
| 13 | 34:05 | Frontend & backend out of sync | 03:56 |
| 14 | 38:01 | Does the process really changes the outcome? | 04:27 |
| 15 | 42:28 | Coordinating between teams | 02:53 |
| 16 | 45:39 | Sponsor: FireHydrant | 01:18 |
| 17 | 47:07 | Test speed & unit tests | 03:49 |
| 18 | 50:55 | The Test Pyramid 👀 | 01:51 |
| 19 | 52:46 | When is your code actually done? | 05:28 |
| 20 | 58:14 | DDD & bug recovery | 05:44 |
| 21 | 1:03:58 | Writing tests in production | 03:42 |
| 22 | 1:07:40 | It's time for Unpopular Opinions! | 00:43 |
| 23 | 1:08:23 | Bill's unpop | 01:35 |
| 24 | 1:09:58 | Chris's unpop? | 00:36 |
| 25 | 1:10:34 | Mat's !unpop | 00:32 |
| 26 | 1:11:06 | Time to Go! | 00:21 |
| 27 | 1:11:31 | Outro | 01:01 |
{kind=link}
Transcript
Play the audio to listen along while you enjoy the transcript. 🎧
Good time of the day, wherever you all are. Today we are here to talk about TDD - is it good, is it bad, what other alternatives are out there? And I’m being joined by my co-host, Mat. Hi, Mat. How are you doing?
Yeah, hello, Natalie. I’m alright. Thanks. How are you?
Good. You are very well centered in the stream, in the video part, so I’m grateful that we’re all trying to keep doing that throughout the episode.
Thank you. I’ll take that as a compliment. I have had better compliments, but I’ll take it.
This is a compliment right now. It’s great that you are taking it.
Yeah. Thank you. Normally, you say like “Oh, you look well” or “How attractive you are.” But no. “You are centered in the screen.”
It’s a German compliment, Mat.
Okay.
I can see you well.
Well then, danke. [laughter] Yeah, danke.
Bitte. And we are joined by two guests today. We have Chris James, who wrote the book on testing with Go, “Learn Go with tests”, specifically… And you are now an engineering manager at SolPay Hi, Chris.
Hey. How’s it going?
Good. You have lots of coffee in your background.
Yeah, I enjoy coffee, and I drank loads, so I’m hyped up. And I’m fairly well centered.
You are, and that’s great. And we’re joined by Bill, who before anything else, is also well centered. Bill, it’s awesome. And Bill wears many hats, including the one with the many pins, and you have the one – so you are a trainer of Go, and recently blockchain, you are heading GoBridge, and also, in September you tweeted something that led to this episode. How’re you doing, Bill?
I’m doing great, in Miami, where it’s nice and warm. I just want to say that… Because I live in the Caribbean. It’s been – other than we’ve had torrential rain for two days, but you know… You’ve got to pay your price a little bit.
Nice.
So the tweet that you tweeted in September and led a very long conversation is about TDD and how you feel about that… And I’ll start with reading it. So you’re writing that you’ve never kept it a secret that you’re not a fan of TDD; you believe in prototype-driven development, PDD, with a focus on data-driven development, data-driven design, DDD. And you believe that general engineering cycles should be prototype, solidify, refactor, test, minimize, reduce, and simplify, and in that order.
Wow. I said all that one day, huh?
You even wrote that.
Wow…
It’s on the Twitter blockchain.
I must have been willing to get lambasted on Twitter, because this stuff is like a religion to some people. So I get really nervous when I talked about – even in training, I get nervous when I talk about testing, because some people are really just – I don’t know, they’ve got these really strong opinions and ideas about it, and it can touch nerves, so you have to walk this line gently.
Let me say this… I’ve learned from working in Go now for about a decade, and even learning how the Go team kind of develops. I’ve seen them go after this sort of prototype-driven approach. They start with a design document where they’re really prototyping everything. Maybe it’s on paper, I know they’re trying it out on some code, and then they get those ideas solidify to a point where everybody feels like – because everything goes in API design. I try to tell my team this all the time, “You’re writing packages all day. Everything is an API. If you don’t put yourself in this sort of mindset… You’re not building monolithic code bases anymore. You’re developing APIs.”
[08:00] Then the idea for me is that I know, at least for myself, and with my teams, it can take a couple of days before we feel like we have an API that is checking every box in terms of what layer of code it exists in, what it can expose, what it can’t expose… Even just today I had one of my engineers saying, “Bill, you can’t put that API there, because that’s app layer stuff, and you put it in business layer stuff.” And I’m “Oh yeah, you’re right. So now I have to move it.”
So if you’re lucky, it just takes two days to get an API design where it checks every box. And so for me, at least, when I think about test-driven development, with the understanding that that means I’ve gotta write my tests first - I don’t even have an API yet that everybody agrees on is designed the way it should be.
Now, the moment we feel that the API is right, immediately I’m going to start writing some tests, because I can’t do go build… And I can start testing that API. But for me, it’s like putting the cart ahead of the horse.
Now, I know that there are people who are very successful at doing this. I’m just not one of those people. I just know the way I work. So that tweet was more about the way that I work, and the way my teams work, and I feel like we get a lot of success with that approach.
So how do you test the design? How do you test that API design? Is it literally on paper, and you’re just thinking about it?
I’m doing two things. The first thing I’m trying to do is figure out, if this is in my business – everything for me is a layering. So we’ve got three layers of code in all of our projects: we’ve got our application layer, business layer, and we have our foundation layer. And these layers have rules, they have policies… In the foundation layer, we’re not allowed to log. That’s like our standard library. So the moment a logger is introduced, it already immediately means you can’t be here. Right?
So based on what layer you’re in, we’re already kind of thinking about what the API can do and what it can’t do; what policies it can set, what policies it can’t set. And so what we’re really trying to do here is develop an API that eventually either has – if it’s a foundation layer API, it’s going to be consumed by the business layer. If it’s a business layer API, it’s gonna be consumed by the app layer. And so that’s our user. And so once we feel like we’ve got an API that’s going to work for the layer above, the consumer, the user of the API, then immediately what I do is I can write a test and I use the _test and the package name. See, for me, having to import the package in the test already gives me that feel for how the API is gonna work.
Yeah.
And this is why I get crazy when somebody wants to use these assert packages for tests, because it takes away from the experience of using the API as a user. that’s your first opportunity to work with this API as a user. I just don’t want to walk away from that. I want to experience even the pain of saying “error” and the pain of it coming out of a function. Because sometimes you might realize, “You know what, this is painful. Are there better ways to do this?”
Yeah. But you are still using that API; just because you then make assertions about it… You’re still using the API, aren’t you?
For me, I don’t have the visual connection to it, because I’m not seeing the ‘if’ there. I’m not seeing the fact that I might want to wrap the error inside the ‘if’ or I can’t wrap the error inside ‘if’ and what is that gonna cause… There are things that you miss, I think, when you try to make the testing easier. I’ve seen some really nice testing frameworks, and they produce a lot of nice output, and I get it… But I feel like you’re missing a part of – your user’s not using the API that way so why is the test– You know my big thing, “Don’t make things easy to do. Make things easy to understand.” So if your user’s not using it that way, why are you using it that way, at a critical moment in time where you’re the first person actually being the user for that API that you’re designing?
[12:00] Yeah, I think that is the benefit, really, of TDD, the one you’ve just described, is you get to be the first user. By the way, you know I’ve made Testify, don’t you? You just talk about these assert packages, like “Oh, you know…” But you know full well I made Testify, mate… Well, yeah, so the process you describe of that prototyping thing is kind of how I do it as well. It’s just that I do it with the test there. It evolves a lot, and it changes, and often it’s wrong. It’s not like I’ve written the test and got it right the first time. That is that kind of process still. And I love the idea that you say putting the tests in a package with _test. In Go you can do that, even though normally we have, for anyone that doesn’t know, normally a folder, all the Go files inside the folder have to be the same package. That’s what makes a package. But you are allowed for test files to use a different package. And then you import the other package. And that, like you say, Bill, I love that, because you literally in your test code, you’re using the package name as well. So you catch things like jarring, and little usability things like that.
Like stuttering and all the other little things that you wouldn’t catch otherwise. I’m not writing a single function that has the word “test” in it until I feel like that API and my team feels like the API is where we want. I don’t want to go back and redo test code because I didn’t get the API right.
But how do you know until you’ve used it?
Well, look, that’s part of the code review process, We’re looking at it. I might even, honestly, begin to integrate that into that upper layer. I might start to integrate it into the app layer, into the handlers that need to use it, and start to get that feel. And the moment we all feel like it’s right, I’m going to immediately jump in and start writing those unit tests, because I think you need to have a set of unit test just in case your integration tests start to fail. You want to localize yourself into testing that. I just feel like if I do it any sooner, I’m adding more work to my workflow… And I’d rather feel like the team feels like this is right, and it feels right in all the different layers, and then the next thing is tested.
Yeah, I think what I find interesting about this is that what you’ve described is not so different from the way I work or the way my team works. And everyone on my team does TDD, Because software development is never as straightforward as you want it to be. It’s a learning process, even for something that seems like a simple problem. It’s only when you start digging in, and you start realizing what are kind of weird contradictions and requirements and how a domain isn’t quite as simple as you hoped it would be.
So for me, an important thing about software development - this kind of goes beyond TDD - is this importance of high-quality and frequent feedback loops. We need to be able to hear about our design, we need to be able to hear about whether the behavior of our code is what we expect it to be. And for me, that’s the strength of TDD, is about giving you that high-quality piece of feedback that your code does what it’s supposed to do.
As you mentioned, what tests do is they also reflect your design back at you as well. So you can look at the design of your code, you can see it behaves how you’d and it’s like a button press away; it’s like Ctrl+F5, or whatever the magic incantation is on your IDE, to get that feedback that “Yeah, it works how I want it to work”, and I can read the test and see, if I were a user of this package, this looks reasonable to me. Or, more often than not, the opposite; “Why was this test so awkward to write, and why is it so difficult to read?” Well, that’s not testing that’s difficult here, it’s the design you’ve created. Well-designed code is simple to test. And the opposite is true as well - poorly-designed code that kind of has mixed responsibilities, and too many dependencies, and everything else you guys talked about, they are difficult to test as well.
So by starting by a test, it kind of centers you on a particular goal… Because I think another problem that I’ve encountered with people who don’t do TDD – I’m not saying this is true of everyone, but I’ve worked with a lot of inexperienced developers, and they think they understand a problem, and they start writing tons of code all over the place. And I ask them, “What are you doing? What problem are you solving?” and it’s they’re solving five problems at once, and they’re solving them all poorly.
[16:17] And I ask them, “How many times have you executed this code?” and it’d be like one or two times, when they can be bothered to wire it up into main.go, and then run the thing manually. And to me, the strength of TDD is it just gives you a very simple, repeatable process that gives you those feedback loops quickly and with high-quality. So that’s kind of the way I see it.
But I think it’s interesting that this kind of discussion is sort of framed as “I love TDD” or “I hate TDD”, but really, actually we kind of have – I mean, we’re all software developers, and we all recognize that this is more difficult than people sort of give it credit for. We need to be able to learn quickly. So I find it interesting that, basically, we have the same problems, it’s just different ways of attacking them.
I think it comes down to the order of things. I’m not writing tests first. For me, TDD is always - and I could be wrong, but when I first heard about TDD, it was always write tests first. And that order that I gave you, Natalie - I don’t remember off the top my head, but can you read that order again, that I threw out on that tweet?
Prototype, solidify, refactor, test, minimize, reduce and simplify.
Alright, so I have Test fourth there, which is kind of what I said, right? We need a package that does this. Let’s design the API. Let’s see how it feels. Do we feel like it checks every box? Good; we like it. Now let’s write the tests before we do a go build, so we know that that API is behaving that way. So I have it four. I’m not saying “Don’t test.” I just I can’t put it first, I just tell you that. So maybe I’m wrong about what TDD is then, right? Is it write tests first, or is it just write tests at some point?
I think it’s write tests first. Chris?
But I would add it’s write test first. This is the interesting thing about TDD, is that there’s unfortunately a lot of misrepresentations from what Kent Beck & co write. I think a lot of people seem to be under the impression that you get given this project of “Let’s rewrite Twitter.” And okay, I’m going to spend days writing tests, and then I’ll make them all pass. That is not TDD. TDD is about taking your first small step, capturing it as one test, and at that point you’re just trying to make it work, and you’re kind of free to write whatever garbage you want, to an extent; you’re just trying to get the test passing, and your software working how you want. And then the other really important step that people will skip is the refactoring part, where now you have a test that proves your software works how you want it to do, you’re now liberated to be creative, and think about design, and reshape the code, and do refactoring… And you keep hammering that Run Test button. So you never go down the rabbit hole. Because quite often, people talk about refactoring, and all the time - they’re spending hours doing refactoring. And I’m sorry, if you’re spending hours doing refactoring, you’re probably not actually doing refactoring. You’re probably redesigning your code. And there is a difference between those two activities.
So for me, that is a really common misconception, and that’s why when people say things like “I don’t have time to write tests first”, and I’m kind of like “Mate, it takes like five minutes, if that.” It shouldn’t feel like a big blocker to you achieving work. The opposite, in fact. Once you get proficient at TDD, and once you get proficient at software design, TV speeds you up; it doesn’t slow you down.
Yeah, it’s mind blowing to me, Chris; mind blowing. I cannot – I’m telling you right now, the thought of me writing a test first, for an API that doesn’t exist yet, because I haven’t really figured out what I need it to do is mind blowing.
But when you think about the design of that API, Bill - like, it’s going to be used by somebody writing code; they’re going to be calling functions, and using types in that package, and things. That’s the bit I don’t get. Because for me, first of all, I should say, I have had the case before where I’ve overdone it on the tests upfront, where I’ve just done too much. I thought I knew the thing so well that I just wrote – I know exactly what the tests need to be, and then I can just bang through and implement it. And then during the implementation, which was kind of like the prototyping phase really, I learned things that then impacted the design; for necessity. And then a lot of my tests were then useless.
[20:25] So Chris’s point I think is quite good, but you write a bit of a test first, and then you do a bit over here, and you sort of do them at the same time. But driven by the test means you automatically get better coverage, because you immediately – well, in my experience, the test coverage is always high, kind of automatically… But I think the principle - you wouldn’t want to ignore what’s in the code and what the code is telling you. And that’s like – the prototyping bit I think is one of the key inputs you want for the design, too.
So just recently, I had to write an API to access some service out there; there’s authentication bits to it, there’s HTTP calls I have to make, there’s data coming back… I wrote 30 lines of code to start; happy path. I put my programming hat on, right? Find the 30 lines of code that make at least parts of the API I know I need working. Like, that’s stage one, right? You’ve got to do the programming. Now, once I see those 30 lines of code, and I see what I need as for config, now I know types I need to return, and I have all this, my next thing really is to design the API based on that programming, and then to share that API design with my team, and maybe even see how it feels, again, in that app layer, and then write the tests. I cannot wrap my head around writing tests without really feeling that it plugs in as a puzzle piece.
So I think a useful thinking tool when I’m coaching people TDD is I ask them to sort of ask themselves, “Pretend this code already existed as an open source package. What would you want to see?” And it gets you to forget about the implementation details. When you’re designing packages in Go, the good ones are the ones where you just sort of see a very useful API, and you don’t know, and you don’t care how it works underneath. It shouldn’t matter to you. I’m a user of this API, this package; you’ve taken care of all the messy work. I just want a nice, beautiful API that I can use. And that helps people make that first step. Because yeah, I think when you’re first starting with TDD, it does feel a bit unnatural; you sort of have to make this weird first step where you’re just writing code for something that doesn’t exist, and your VS code or IntelliJ is all red because the code doesn’t exist, and it makes you feel uncomfortable.
But what you need to be doing when you’re in this mindset is have this positive attitude towards it, and go “What would be the best package design that I as a user could put in front of myself?” and then encode that as a test. And you immediately document it to yourself; you sort of say, “Okay, so if I do this right, I see exactly how to use this package.” Then you dig into the messy details and make it pass, and things… But I guess my point I’m trying to make is like well-designed packages hide that from you anyway. So you’re not gonna see that in the test; you should just see a well-designed API in front of you in the test. And that thinking tool helps you write a good test in the first place.
Because how many tests have we all seen where it’s like there’s a load of messy implementation details and things that’s really difficult to read… And worse still, difficult to maintain, because then when you change an implementation detail, you’re suddenly like “Oh, my goodness… Ten tests are now failing because I changed this one line of code.” There’s all these terrible things. But if you start with a test-first attitude, and think of it in terms of the behavior you want, rather than the implementation details, you’re more likely to write a maintainable test suite.
I quite like those errors that you get, actually. Like, when you write a test for something that just completely doesn’t exist, you get compiler errors, but you get one error at a time, and it’s almost like a to-do list; it tells you what to do. And then once you’ve got past all your compiler errors, you then have a failing test, which is then telling you “Hey, now you have to fix this thing.”
[24:08] And the classic case of – if you take red/green testing, this idea that it’s important to see a test fail first…Or if you write a test, and it always passes, and it’s always passed, how do you know you’re really saying anything about the service, or anything? So I really want to see it fail, so I know it’s actually saying something, and then I can make it – it’ll say, “Oh, this has now failed. The expected output was 42.” Okay, so I’m just going to return 42 from this method - and this is an extreme case - which then makes that test pass. But then that highlights the test isn’t complete yet, because I made just one assertion about it being 42, and just returning a 42 is enough to make that pass… So I’ll put a couple of other examples in there, and then I can’t cheat like that, really. So yeah, I quite like that error list that you get guides you through it.
The majority of packages I write are not single-module packages that are going to be in somebody’s vendor folder. They are for these big projects, where we’ve got four people working on this thing, and now the app layer needs support for being able to order things from the database. So now I’ve got to figure out this package; parts of it might even live here, parts of it might even have to be app layer, because I can’t put that intelligence there… And so I’m designing something not as a vendor package, which might have an API where maybe you can think TDD to start, I’m thinking already “I’ve got to integrate this support in the right way based on our rules, and I’ve got to make sure that puzzle fits first.” And I’m telling you that I have never, on any project like this, gotten the API right even the fourth time. There’s always somebody who remembers something, like “Bill, you can’t – Bill, you’re leaking this. Bill, you’re doing that.” And I’m like “I teach this stuff, and I’m still making these mistakes.” Or I’m moving fast, and… One time I put something in there, and I wrote, “You’re not gonna like this.” And everybody was like “What?” And I said, “If you don’t see it, Pavel will.” And immediately when Pavel woke up, this first thing was “Bill, you can’t do that”, and I started laughing. I just left it for him, because I knew he was going to say “You can’t do that.”
And so for those packages, the majority the packages I write, I really need to be thinking about the design as it relates to how its integrated into this project; not as a vendor package. So again, my brain says, “If I’m writing tests first, I’m not leveraging my time enough.” Because I really don’t know how it fits best until I try to fit it in. I haven’t run the code. I’m just trying to make sure it fits in and checks all the boxes, and then immediately, yes, I’m gonna write – I don’t care about the implementation so much as, again, the behavior in the field. But integrating into a big project is a much different problem than the vendor, say, package that you’re going to be building.
Chris, I have a question for you. You said that it’s important for you to separate the responsibilities, and decouple, and make sure that each part is individual, and that way it’s simple, and you know that when you’re asking, “What is this doing?”, “This is doing this one thing.” “What is this testing?” “This is testing this one thing.” So when you start writing tests for something completely new, do you go bottom-up or top-down? So do you write the first test to be the biggest functionality, and then you add small tests, or do your first write tests for the very small things, and then later on add the big test that kind of checks everything?
I tend to favor top-down development, because it’s the least risky way of working, in my view. I’ve seen a lot of kind of bottom-up efforts where people are making these kind of beautiful-looking packages, that have corresponding beautiful test suites… But then when you try and integrate them together, you realize this is just a mess, and it doesn’t actually do what you need it to do. Again, it’s this idea of like high-quality and relevant feedback. Like, yeah, you’ve unit-tested this package, and yeah, it’s wonderful, but it hasn’t done anything useful until it’s wired up into main.go in effect, right?
So I generally prefer a top-down approach, and I would definitely plug Steve Freeman and Nat Pryce’s book “Growing object-oriented software, guided by tests.” And I know some people in the Go community are a bit allergic to OO, and it’s a Java book as well… But I promise you it’s a valuable book, because it kind of talks about this kind of approach of work, of working from the top down, starting with an acceptance test. And what the acceptance test does is exercise the system as if it was a black box. So it doesn’t matter what the package design is, it doesn’t matter how it works underneath. It just literally hits the system and checks “Does it do what you need it to do?” Starting with that as like your Northstar is an incredibly powerful way of working, and it’s something that my team really strongly embraces, because it forces you to think about “What does our system actually has to do?” Like, forget about design, and stuff, because as engineers, we love to talk about design and all this kind of business… But our system has to do something useful; it needs to do something that makes money, or helps people, or whatever. An acceptance tests forces you think about “What will this system do from the outside in?” You then use that as a North Star to guide your efforts.
So you have your [unintelligible 00:30:40.15] acceptance test, and then you just start writing some code. And then again, like the kind TDD approach in itself, at first you’re just trying to make the tests pass. You’re not worrying too much about package design. Honestly, when I do it, most of the time I’m making it work all in main.go. I’m just like “Get it working. Let’s just get the software doing something useful.” And then again, once we have that passing the acceptance test, and it proves the system works how we need it to do, now I have the license to start putting things into packages and things, and then I might start testing some edge cases for unit tests that aren’t so great with acceptance tests… And then the software grows from there, hence the book title “Growing object-oriented software.” It’s this idea that you don’t just write software and it’s done; you grow it. And in order to grow it, again, you need these high-quality feedback loops that keep coming at you quickly, letting you know whether you’re going on the right track or not.
Are your acceptance tests integration tests then, essentially like end-to-end tests?
Yeah, the naming around all this stuff is incredibly confusing. For me, an integration test is something that takes two units, or two or more units and checks that they integrate and do something together. For me, an acceptance test is something that tests the system as a black box. So if you’re making like a HTTP API, in [unintelligible 00:31:52.21] you could do an acceptance test with curl commands. That’s the way you look at it; you don’t really know there’s even a Go system at that point; it’s just some Go program that responds to HTTP. That to me is an acceptance test or a blackbox test.
Okay.
[32:06] Integration tests are more within the system for me.
Okay. So an end-to-end test maybe we could call that.
Yeah.
Yeah. So it’s funny, because that is how I do it… So I have a thing that we’re building, and it has a frontend, and it has a backend with an API. And the API is like – when we run this test suite, it literally spins up the database, it spins up the whole thing, and accesses it like the client is going to, like the frontend is going to, calling the methods, making the same calls.
We actually have an API client as well, which it uses. So we’re also kind of testing that at the same time as well. So this is like really getting as close as it can to what the browser is going to do. And then I’ll be able to write then in quite a clear way what I expect. Like, I’m going to do one thing, and then I’m going to do a few other bits… You know, it might be adding users to it, it might be adding a task, whatever the flow is. Then I’m going to get it and make assertions about what that state should then look like. And usually, when I’m adding a new feature, that’s a very easy way for me to reason about what the feature is that I’m adding, and it sort of takes away a lot of the ambiguity. Like, if we’ve discussed it, lots of people will have a different idea of what that thing is, and this lets you remove a lot of that ambiguity and saying, “Well, look, I’m literally calling this API in this order. It should result in this.” And if anyone doesn’t agree with that, that’s great to catch that nice and early, and we can figure it out.
And then yeah, you go about implementing it, making that test pass… And you sort of – because of that approach, I know that that new feature works as I expect, whatever else is going on. And I can get – actually, sometimes we’ll skip unit testing in some places, because that’s just such a kind of reliable thing that I just have the confidence that that works.
I’m always worried about guessing. I don’t want to guess. Let me give you an example, because you mentioned frontend… I have a person that works for me, he’s a frontend dev; we were working on something, and I started doing a code review… And it was all JavaScript Node, so I was really losing my mind. And I finally looked at him and I said, “Why are you doing that?” It got to the point where I went and I built a terminal frontend so I could experience the API that I gave them. And I realized so many things were missing that I changed the API, so I can write a frontend. And I went back to the frontend person and I said, “I don’t understand, one, how you got this working, and two, why didn’t you ask me for these changes?” And you know what was the saddest thing? They said, “Bill, as a frontend dev, we just deal with what we get, and we just make it work.” And I said, “This is a horrible way to live.” I go, “You can’t do that with me. You have to tell me when something’s missing.” And I got to the point with them now where if we need a new screen, I ask them to build it, and I asked them to go into the Go side and write handlers that send static data.
Yeah, great.
I said, “You tell me what you need, and I will do my best to make that API work for you.” And then I’ll work from the business layer first, so I can feed that, and then I’ll work at, say, the data layer. But it’s so sad, because a lot of the APIs that I had felt right to me, but were not frontend consumer-friendly. And again, I don’t want to guess… So there’s a situation where I could have written all those tests and done all that stuff, and realized that it was all wrong. So I’ll just throw that out there…
Yeah, but I think you just did TDD, really; you built the terminal… It’s not tests as code, but it is like, you are testing it; like, you run the thing, see if it works, and then make changes to it that way. That feedback loop is what you needed from that process.
[36:07] For mocking out the handlers as a test-driven thing? I mean, I was asking the frontend to do that, so they could drive my design, because I don’t want them to be – you know how horrible it is when you have an API that’s not even doing error handling consistently? The amount of extra code a frontend has to write because of that… And I’m thinking about these things, and I still wrote a – because I’m not a frontend dev; I still wrote a pretty poor API for web dev, frontend dev… [laughs] Oh, I felt horrible, man. I never want a frontend dev telling me that ever again. I felt horrible.
I guess the big difference here is that somebody else is testing for you.
I say this in class - we write APIs all day, so you can either make somebody’s life amazing, or miserable. And we’ve all not wanted to go to work the next day, because we had to work with an API that was just… Dude, I had a JSON API return XML on me once.
[laughs]
And then I had to deal with that.
Inside JSON? Or just pure XML.
Pure XML, not inside JSON. Apparently, they were fronting an XML service instead of rewriting it; they were transcribing XML, and I found a call that bypassed the trans– [laughs] But you understand what I’m saying… Consumer is everything. And I call them the user. The user is everything. And if you’re not the user, then you’re really guessing.
Fair enough.
I never do it right.
Yeah, I think that’s fair. I think that totally makes sense. I think TDD is about being obsessed with the user; you become the user. And to be honest, in the case I talk about, it’s possible for me, from just starting at the API, it would be possible for me to build a horrible API, i.e. you make this call to get some data, and you have to make lots of them if you want lots of data, and what the UI really wants to show is a summary. Things like that, I think… I don’t know that you get that solved for you by any sort of process.
But I wonder, Bill, if – and I don’t know the answer to this, but I do wonder if the approach changes what we end up with much, or if we sort of end up in the same place, regardless of process. Because when you talk about things being like in your big system, where there’s lots of moving pieces, and you have to think a lot more, you can’t just jump straight into coding bits, I wonder if that would be different if you’d started with that process… Or if you just end up still with the same thing, and the process is really just personal taste almost, for the team.
It’s about, for me, trying to minimize the amount of guessing you’re doing, and prototyping does that. The more you can prototype and solidify something, then the less guess you’re going to deliver. So I’m curious, Mat, since you do a lot of frontend stuff, if you’re not the one working on the frontend, is your frontend developer allowed to say “That API isn’t working for me”? Because this person was never allowed to say that.
Yeah, so that is interesting. I love that idea. One thing we did in the past place was we would collaborate on that JSON API, and we’d have a .json file, and we’d just serve that from the backend. So the frontend is unblocked, because they’re getting at least the test data. A bit like how you said, just have a Go handler that returns it; I’d kind of prefer that, actually, because it’s easier. I’ll probably do that from now on. And then you’re both working to a kind of point in the middle… Like, when they built the tunnel between the UK and France, they started digging from the French side, they started digging from the English side, and they met in the middle.
So yes, I think you’re right, the frontend is really kind of paramount, because that’s where the actual end users are going to be touching something. So I put more importance in that. So if a frontend needs data in a particular way, I think that outweighs what else might be considered there…
[39:57] Yeah. So I don’t want to guess, and you are going to have some level of guessing. It’s impossible until you actually finish whatever that integration is. But I want to minimize that. And I just feel like, personally, that if I’m starting with writing tests - again, because I’m not just writing a package that somebody’s going to vendor; I use vendors, you understand what I mean there. I’m writing a package that has to integrate in complex ways, and so I just need to make sure those puzzle pieces come in.
I have a person on my team that likes to start the business layer. Doesn’t want to even look at like – a data store is a complete abstraction to them, right? So they just want to completely start in the middle of the business layer, and get a feel for those APIs first, before we do anything. There’s lots of ways to succeed here.
I think that’s going to end up being where we land on this, honestly… But yeah, so what we’d do with those JSON files in the past place - they would be the tests for the backend API. So it gets served to the frontend for them to code against, and it becomes the same file as the test. So we call the API in the expected way, and assert that the JSON we get back matches this JSON. And often, as you’re going, it doesn’t, and it breaks, and that’s a conversation point, because you want to change that JSON. You’re like “Okay, so because I learned about this thing, it’s not a boolean in the end, it’s a string… So is it okay? Can we make this change?” And you have to then make the change and sort of negotiate a little bit.
But here’s the cool part with letting my Node developers write handlers… Because they learned how to do that in like 15 minutes. They’re designing, at some level, the application-level models. And I’m making them define – and I show them how to write a literal struct. But they’re also defining the data model at the app layer. That doesn’t mean it’s going to be the business layer model. It’s always good to have that decoupled. But they’re also writing that model, that data… Remember, we talked about data-driven development. If you don’t understand the data, you don’t understand the problem. So the frontend devs get two huge – everybody wins. In fact, the frontend devs are always ahead of me. I’ve never had that in my life. I always had to be ahead of the frontend devs. Now, I’m constantly trying to figure out what they’re going to do, because I’m now behind, because they wrote the handler, they wrote the literal struct, they defined the data model, they filled it in, they know it works, they can show it to me… And now I’m scrambling to make that come to life, right? And that’s the contract.
Yeah, I love that. I mean, that is literally how I like to work as well. So I think I’m with you there. While you’re implementing it, do you then ever say, “Oh, hang on… I’ve just learned something. I can’t give you it like that. It’s going to have to be like this”? Do you have that handshake? Or will you just take it like as law that what they’ve asked for is what they’ll get?
I try to keep the application model exactly the way they want. And then at the business layer we define our own models that are going to work better for [unintelligible 00:42:49.11] Right? But there are times, obviously, where we’ve gotta negotiate… Time is a great example. Time is a nightmare. How do you want to deliver time down to JSON? And sometimes we just pick a format, an RFC format, sometimes we’ll do some other things… So if we were to negotiate anything with the frontend, after looking at a data model they’ve put together, probably time is always the sticking point; bringing time back and forth.
I also want to answer your question, Mat, although it was for Bill…
Please do, Natalie.
…if this is the same goal, or is this - you end up in different places, doing the two different methods… Because recently, I had a project where it was a very new, and it was not TDD at all; it was very much – not with the frontend, but actually with two microservices. And it was one team telling the other team always, or the person from microservice A telling the person in microservice B, “Please make this change. I need it like that.” So a very similar interaction to what Bill was describing with the frontend people. And I did work mostly in TDD, I would say, but this one was so different, and I feel that this did lead to different interactions and a different result because of this – the person who tests, who does this test is not you; you cannot guess that. You have other people bringing other expectations. So I do think this is a different – you don’t end up in the same place.
Yeah, I think you might not end up in the same place. But also, that I quite like also, having somebody else write the tests. If you’re pairing, it’s quite nice to have - one person will write a bit of a test, and the other person then switches and does the implementation. That works quite nicely as a way to collaborate, and evolve, or grow, as Chris said. So I don’t know that that’s like mutually exclusive, really, who writes the tests… And honestly, I feel like there’s a big “It depends.” I feel like “It depends” needs its own little theme tune in tech, because basically there’s so much “It depends.”
And I feel like often whenever someone on Twitter, or whichever platform is now still going, by the time this goes out on Thursday… I feel like when there’s a strong opinion like this, and there’s big disagreement, what we find out if we dig in deeper is we’re actually doing different things, or the scenario is subtly different, or sometimes dramatically different. And we need like a big stamp that just says “It depends.”
So I want to answer to something Dylan’s asking on Slack, and I really would love Chris’s opinion on this, too… Because I have opinions on this. Dylan’s asking two things. He’s asking about “Tests must be fast, and spinning up a Postgres database in Docker.” Let me just talk to that. I do that. I feel like if you’re mocking a database, you’re not really knowing if your stuff works properly. And Postgres spins up so quickly… I do it in CircleCI; those tests run easily within a couple of seconds. So I have no issues personally right now with how long a test necessarily takes, as long as there’s an expectation…
But the other thing is the big one, where it’s this idea that if your test hits a database, it’s not allowed to be a unit. So let me just tell you what I think a unit test is, and then I’d love to get Chris’s opinion. See, what I love about Go is it’s already defined what a unit of code is. We don’t build monolithic codebases. The unit test is a test that tests that package’s API in and of itself, right? Not any other interactions of other packages; just every interaction that that API has to make. And if that API is talking to a database, then I don’t know why, personally, I can’t spin up a database and write a unit test that makes sure that that API’s queries and calls work. To me, that’s still a unit test. It just happens to be hitting a database to run that unit of code. So Chris, I’d love to hear your opinion on that.
I wish I could bring in some controversy, but I basically completely agree. I think there’s been a big misrepresentation in tech about what a unit test is… Or it could only be a particular function, or whatever. I wouldn’t describe it as a unit test; to me, this is an integration test. But that distinction isn’t that important in the grand scheme of things. Like, you’re testing your code integrates with Postgres, or whatever database, right? So basically, I agree. And I do the same thing. I will have some kind of package that is in charge of doing whatever I need to do with Postgres, and I’ll write – I have to use test containers most of the time to spin up a Postgres Docker, and I run my tests… And yeah, they’re not as fast as unit tests, they take a few seconds, but - big deal. Still a wonderful feedback loop in the grand scheme of things.
Yes, I’m afraid to say, I basically completely agree. I think mocking the database is really clunky and difficult to do, and you still don’t really have particularly useful tests, because you can prove that like your SQL string equals select star from users, but does that do what you need it to do? I don’t know… It just doesn’t prove anything, in my view.
So it’s really like – maybe we could talk about things that your tests should give you. I think the feedback loop thing is very important. By the way, you can just spin up a database and keep it running as part of your dev environment too, and just clear it out every time, rather than having to spin up the container every time… But again, that’s just little optimizations, and things…
[49:59] But yeah, so that is a question people should ask, because there’s a lot of language – I don’t know what people mean when they say an integration test, honestly… I don’t know what they mean. I’d have to find out, I’d have to ask them more questions. So what do you get from your tests? Is it really telling you what you want to know? Can you break something in your code somewhere, and then you get a failing test that points to that failure? And so this speaks a little bit to that idea… Really, the reason I think unit was used as a word was, ideally, you would just get one test that fails if you break something, because it tells you exactly what’s broken. You can’t always do it, and if you’ve found a function that’s called all over the place for doing auth, or whatever it is, and that breaks, loads of tests will fail. But actually, that’s quite a good clue that there’s something fundamental that’s broken here. So I like that laser-sharp focus on failing tests as well.
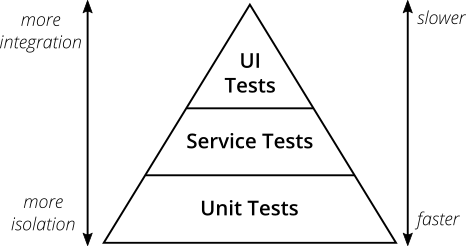
Yeah, I think the useful thing to look at here is the test pyramid, which describes different kinds of tests in the shape of a pyramid, funnily enough. So at the top of a pyramid you have your end-to-end tests, your acceptance tests… And the idea is that you should only have a few of those comparatively, because whilst they’re great, and they give you a lot of confidence that your system does what it’s supposed to do, they typically are slower than the tests further down the pyramid. They’re usually more expensive to maintain, and normally, the quality of the feedback loop isn’t as great. So you can write an end-to-end test and it can go where it doesn’t work; typically, it doesn’t tell you why it doesn’t work, and you have to dig into your system to try and understand why.
Integration tests - you’re getting a few more of those; they’re proving that two lumps of code, whether it be two packages, or a package and a Postgres database, whether they work together… Again, they’re faster than your end-to-end tests, they give you better quality feedback, but again, because they’re two different things, which one’s the problem here when it fails, right? You have to kind of dig into the various units to understand, “Okay, it was this bit of code that was the problem here.”
And then finally, you have unit tests, which are what you’re describing, Mat; typically, when they fail, you get a very precise reason as to why they fail, and they also give you really fast feedback loops. These are the ones that really helped you refactor, because you want to be able to do refactoring frequently, and small, frequent refactorings. And that’s what unit tests give you, they give you this ability to just refactor [unintelligible 00:52:18.18]
And you should have loads of unit tests, to a point. You can get to a point where you have perhaps too many tests that are kind of coupling themselves as stuff you don’t need, and I’m sure we’ve all been in projects where there are tests that are impeding our ability to change a system. You get to a point where you’re like “I want to do some refactoring, but I know if I do this, I’m going to have a bunch of tests failing.” And that’s definitely not a situation you want to be in.
I have a question for everybody here… NASA did a study and they said roughly every 20 lines of code you write, there’s a bug in your code, whether you like it or not. Now, this was off of their codebases that are written in C, so maybe we get some better numbers out of Go.
Who’s this NASA?
That’s boring, ain’t it?
Well, if they’ve got that many bugs, how did they get to the Moon?
There we go, man… It was a lot of testing.
Confidence.
But here’s the question.. I get asked this, so I’m curious, everybody here… At some point, you have to be done. You have to be done writing tests at some point. So one, what is your definition of “We’re done writing tests”, and if that answer has to do with some sort of level of code coverage, then what is your code coverage number to say “We’re done. We’re moving on.” Because you’re not going to get to 100%. It doesn’t mean anything. So I’m curious about what your done answer is for when you’re done writing tests for that package, and if there’s a number, what the number is.
[53:42] It’s not easy to come up with a straightforward answer to this, and I think I’d like to stress also, again, that whilst TDD does give you a test suite, and does kind of naturally give you coverage, TDD is not primarily about verification. It’s a method for driving out software, right? So just because you’ve done TDD doesn’t mean your testing picture is over. So you might need to do some pen tests if you’re writing something that needs to be particularly secure; you probably need to do performance tests. You might just need to write other verification tests, like fuzzing tests, for instance.
So TDD and testing, they’re clearly related, but they’re not quite the same thing. And I think really, it just comes down to confidence. In terms of software, we want to be able to ship it as quickly and as reliably as possible. So if a bug comes up, I want to be able to like fix a bug and ship it as quickly as possible. And most modern teams these days would rely on tests to say to themselves “Yeah, we’re good to go. We can release this to production.”
So if your test suite is in that state, I would say you’re done. But as I said, writing software isn’t quite like that. Normally, it has to grow and evolve over time as you learn from your users. You need to – “Oh, the users told us they need to do this. Okay, well, now we need to go back and change things.”
That’s fair. But if you’re managing a team of people, and you say to that person – at some point you say, “Do we have enough test coverage? Because if we don’t, I don’t want you moving on to the next thing.” So it’s like anything in engineering - how do we know we’re done with this so we can move on to the next thing?
In my experience, I’m not interested in code coverage that much, because essentially, the only promises I’m making are what the tests say. And so the tests – you know, if there’s hidden logic, if there’s like hidden stuff that happens that’s not in the tests, then it’s unofficial, essentially; it’s not part of the official API. So that gives you a lot of freedom, because as long as your tests pass, you can deploy it. And honestly, for me that’s the real value of testing - you want to have the confidence to be able to push to production, and not be worried, and not be like “Oh, let’s keep an eye on it, mate.” I’m so confident with our tech that if all the tests are passing, push. That’s the only promise we’re making, just from that layers point of view.
Okay, but you still didn’t answer my question, Mat. How do you know that the tests are giving you that? How do you know you’re done? How do you know the tests are giving you that ability to sleep tonight? We all agree, and I’ve learned this too hard over the last ten years working with people from Google - everything has to be measurable. You’re not allowed to to say “Because it feels right.” You’re not allowed to do that. Things have to be measurable. So how are you measuring that that package is done? Let’s keep it down to a unit of code. You’ve assigned a package to somebody to write; how do you know it’s done, so they can work on the next package? I know testing has to be a part of the done equation… So how do you know you’re done to move on to the next thing?
Well, just if I’ve satisfied the user, really. That’s the thing. And also, I understand when people say “We’re never done” in software. So I understand that basically it’s fine, this is good enough for now; but it’s not done. Like, we’ll definitely evolve it and change it.
Okay, at some point you’re done. It may not be complete.
Okay, fine.
How many times have you seen a module out there where the author said, “I’m not working on this anymore”? I consider those done. The PQ driver for Postgres - I still use it. Everybody’s like “Why are you using it?” Because it’s done, and it’s stable, and why should I go to PGX, where they’re still doing active development on it? …and this is done. We get scared of done sometimes, and I don’t know why. It may not be complete, but it’s done. You know, Dave Cheney taught me that…
Yeah. Well, I think – I look at code coverage, because I’m interested if there’s any blocks that I’ve missed. And I don’t test every error – like, if error return; I don’t test those. I sort of trust myself that I get those right. And sometimes that bites me, because there’ll be some strange little thing where I’ve shattered the arrow or something like this, and there is a bug in there. So I only test error things like that if it’s part of the API. Like, it’s returning a special error in a certain case, and that’s part of the API; I’ll make sure that’s covered in the test. But it’s just if the thing is… If it’s done. Um… [laughter]
[58:07] It’s done when it’s done, right?
Yeah, Chris [unintelligible 00:58:11.05]
I mean, I can only describe what my team does. And I tried to bring up another TLE but, BDD, behavior-driven development, right? That’s another thing that people throw around.
It’s another DD…
Yeah. To me, without going on too much about it, it’s about understanding your problem with your stakeholders, like the customers, or like your business people, or whoever. So when my team pick up a ticket, what we try to do is understand these requirements, and we try to express them in these kinds of BDD terms, like “Given something, when something happens, then this happens.” And we discuss it as a team, we try and understand, “Okay, this is the problem we’re trying to solve.” And then we basically tell ourselves, “So in order to do this ticket, we need to have tests for each of these scenarios.” But we also acknowledge that something will fall through the cracks. Of course it will. No one can write perfect software. It’s just not possible, right? But we have enough confidence, we think we discussed it enough, and we’re going to put it live.
And then of course, something goes wrong… Okay, we recover from it. And I think a far more interesting question to me in terms of software developer - it’s not so much like “How many bugs can you prevent?” but “How quickly can you recover from them?” Mean time to recovery for me is a way more interesting question. And again, this idea of having a very effective test suite is such a key components to that. I’ve heard of companies that have test suites that take days to run. So if you’ve got a bug, what do you do? Well, what they do is they circumvent the process; they skip the tests, because they need to fix the bug. And then that causes more bugs. And it just gets worse and worse and worse. And when you read like the State of DevOps reports and things, it just constantly talks about this stuff, about how important it is to recover quickly. And to me, an effective test suite is like the center stage of that particular problem for us.
I see that there’s a little bit of an MVP, in the sense that you do the basic thing you need in order to run with that, and then you can always add to that. And what is included in that MVP is what sort of, you can say what is in the API, in the sense of what you communicate, what you commit to has to be tested, the expected behavior, and at least catching the unexpected behavior… So even if it’s as basic as “if not expected behavior, then…” And then this is like the very minimum that you need to call this done, and you can improve on that, for example, by breaking down the scenarios of “Not expected, A, B, C”, and so on.
Yeah, I really like that idea, actually, of anticipating how it might be misused, and catching that. Sometimes that really is helpful. And that’s really the only time I will write panics, is if it’s going to panic anyway, but I want to add a bit more context, or I want to just explain what’s happened in a more specific way. So I do quite like that too, sort of defensive – and try in the test some error cases, and make sure that it doesn’t do the thing, because you passed in – I had a thing once where, for whatever reason, it was a username and a password check, and if they were both blank, it was just true. It just worked; it would just return true. So if you just didn’t pass in anything… And you know, that’s not great. It’s not the most secure software I’ve ever written.
This is actually one of the best answers I’ve gotten for done, to knock it against that list. Just the last two days I’ve had to go through JIRA tickets for a client, because they were like “Is all the stuff in there?” I’m like “I don’t know”, and I had to rip all the JIRA tickets out in a spreadsheet.
I’m sorry…
And now my brain is just like that; I can’t use JIRA directly, I have to move it. I have to see 30,000 feet of feature functionality, and I need to see it at a high level. But for me, I love that idea that it’s done when I check those boxes off, because that feature functionality is at least in there. That’s good.
[01:01:58.15] Now, Chris said something that triggered something else in my head, and it’s this idea of deploy-first sort of development, where from day one you get enough of a little thing working where you start deploying it… Because if you’re not deploying it day one, you’re not able to deal with bugs that are going to be only fixable at the deployment level, or in the system you’re deploying to. Too many people want to turn a debugger on, which they can do at their desk, or that they can do in that system that they’ve deployed to. So it’s that same idea, Chris - like, you can’t have a test running for a full day. You’ve also got to already start learning how to deal with that bug that’s in the system out there that you’ve deployed… So I try to teach this too, this idea of deployment-first sort of development, where we get one little service going on, and we deploy it right away.
I love that. I think anything you can do from the beginning, any constraints you can put in like that, really… I.e. this deploys automatically. The tests have to always be passing before you can get them into main” - those kinds of rules, I find them to be just great. It’s easy to do, because you spread the pain out. You’re doing it as you go along, rather than waiting until the end, and suddenly you have this mammoth task. So yeah, I think that applies to anything, and be close to production as you can, and things.
And in my case, with the test suite I talked about, by the way - I can actually point those tests to production, and run the same test suite in production. And that’s a great, nice little check. Post deploy, it runs the same tests again. And because it’s hitting real API’s, it’s the same thing; or very, very similar. So yeah, I love that. I love that. Do it early, and get your constraints in. Start with the constraints. It’s very hard to retrofit. That’s why I do TDD as well.
That’s also kind of the essence of CI/CD.
Right. Yeah, continuous.
Yeah, I’d like to say, definitely making it so that those acceptance tests can be ran in production is such an enabler for that kind of agility… Because - you know, just because those tests run locally, or even in like the staging environment, the whole kind of dev/prod parity thing is, at best, like a white light. When you go to prod, there’s CDNs involved, there’s other configuration involved which can break your software, right? But if you can run these tests in production, you suddenly have way more confidence in your ability to change the software. And honestly, one of the biggest challenges we have as engineers is managing the cost of change. Because that’s what we say - yeah, for some things there may be is a state where the software is done, but most software, it always needs evolving and changing, at least for like a few years. So the cost of change is so important, and yeah, trying to retrofit this stuff, even a few months later, becomes so much more expensive and painful to do. It is unreal. If you’re starting a project today, think about this stuff upfront and make sure you fit it in at first, because otherwise, you’re just setting yourself up for pain.
Yeah, I agree. One of the nice things is - and this happened - I had an error, a bug in production, I wrote a test to prove it, I ran the test suite against production, and proved the bug. And then I was able to fix it locally, and I ran it locally too, and saw the same behavior. So that’s – first of all, that’s quite important. And then fixed it. How confident was it that that was going to fix it? Like, very confident? I’d do a deploy, I’m like “Yeah, the fix is going in now, and I’m sure it’s gonna fix it.” It didn’t, but… That’s not the point. [laughter]
I’m curious about – I’ve never thought about running tests in production. So I think it’s a brilliant idea, but my brain gets stuck on two things. If the tests are doing some form of database manipulation, how do you not put that bad data in? And if it’s making API calls, how do you make sure that’s not changing any state and/or cost that might be involved? I’m really curious about those two things.
[01:06:01.21] Well, it does change the state, because my later bits of the test will be asking for that state to verify that it’s correct. I’ll have either a – usually, it’s multi-tenant. That’s another thing, I tend to build everything kind of multi-tenant as well, from the beginning… So just a tenant that is a test account almost, and then test users, and stuff. Some people are like “You shouldn’t ever change your system to enable your tests.” Are you comfortable having like special little secrets that unlock things for testing?
I think you should avoid that as much as possible, and you should try and test as a user would…
As a real user.
Because if you start putting those kind of backdoors in, you run the risk of making these tests green, but actually, it doesn’t work for real users. I think for me it’s a really interesting topic in itself, is just as having your architecture enable you to do this kind of test automation in production. Because again, for me, I remember being first exposed to this kind of thing like six years or so; I was working on this project, and I just cannot describe how liberating it was compared to other projects I’ve worked on, where the big release day was the most chill time of my life. Like, we just sat there, because we’d already run the tests in production hundreds, if not thousands of times before, but we’ve just hidden it all behind a feature flag. And then we just turned the feature flag on… “Yeah, it’s fine.” All we really did was just stare at Datadog all day, just to pat ourselves on the back, because we were so confident, because we’d run these tests in prod, and these tests were like a user.
Other observability platforms are available.
Sorry… [laughs]
And then came time for all the loading tests and so on, and the chaos and start breaking things. So I have a question for you all…
My question is, how do you like Mat’ song? [laughter] No, what is your unpopular opinion?
Well, this whole episode’s been Bill’s…
[laughs] I think Bill is slowly convincing you all…
Is it popular, Bill?
My opinion?
Yeah.
You know, I might lose half of my Twitter followers after this one.
Well, you might anyway, mate. But…
I may anyway, so I’m starting local…
Yeah, it’s slowly happening.
So my unpopular opinion is – you heard about the whole FTX crash, right? And everything that’s now falling behind it. So my opinion here is that the FTX crash shouldn’t be associated with the blockchain technology directly. It wasn’t the blockchain technology that caused that. It was people that caused it. And again, I’m not a crypto fan, so I think all these people should go to jail ten times over. But I am a fan of the technology that’s being built, and just the new math that’s been built over the last five years in the crypto space, and I don’t want to see that go away. So my opinion here is that people shouldn’t be attaching what’s happening with people in like crypto with blockchain technology, because one really has nothing to do with the other.
I am interested in seeing how that goes…
There we go, everybody is quiet! [laughs]
That is an interesting one.
I’ll be very interested to see the results when they get polled out on whichever platform survives…
Hey, you know, if you’re gonna do this, do it right. [laughter]
Although it will be a new, interesting bias, given that more and more people are just not on Twitter. So the people that leave are the ones that more agree with you, or less.
Well, I’ve moved to TechHub.social. I’m actually moderating that instance… So if people are looking to jump, and they’re looking for an instance that’s being moderated in the same way GoBridge would moderate anything, TechHub.social is a great place to check it out.
We’ll add that in the show notes. Chris, do you have an unpopular opinion?
I don’t know, I completely forgot about this segment, and I feel under pressure…
That’s unpopular, mate…
Football’s coming home? There you go. Football’s coming home. [laughter] It’s the wrong audience, but I don’t care. Football is coming home.
Is that the one with the green floor?
Yeah. And the ball, and they’re kicking it around.
Yeah, I’ve seen it.
It’s that one.
The round ball, or the one with the…
Yes.
Is that an egg?
Not the egg. Not the egg ball.
Not the egg.
But is that an egg? Because they’re not very careful with it, if that’s like a, like an egg… Do you know what I mean? They’re proper just kicking – they throw it around all sorts…
It’s a spiky one.
It’s a very strong egg, ain’t it?
Matt, I heard you have an unpopular opinion.
Oh, yeah, I did have an unpopular opinion, actually… I thought of one, and I thought “I must write that down”, and then I distinctly remember not writing it down, thinking it’s so good I’ll definitely remember it…
It’s just building up for the next episode. I see where this is going…
It’s a great story.
But then I thought, “I should write it down”, but then I still didn’t. I can’t remember.
Well, next episode, tune in for Mat’s unpopular opinion. Thank you, Mat, for joining. Thank you, Chris and Bill, for sharing your thoughts. It was very interesting. Thanks everyone who tuned in to listen and was super-active on our Slack. That’s super-fun. It is very interesting, and it looks like this is a hot topic, so we probably will meet again to talk about this. A good rest of your day, everyone!
Bye!
Cheers!
Our transcripts are open source on GitHub. Improvements are welcome. 💚